Un fichero PDF es, en esencia, una colección de objetos que se apuntan mutuamente. Eliminad la compresión, la gestión de referencias cruzadas y los desplazamientos de bytes, y lo que queda es un grafo: un pequeño conjunto de valores tipados, conectados por referencias, con raíz en un único objeto que el lector sabe cómo encontrar. Todo lo que un PDF puede expresar, desde un párrafo de texto hasta una fuente incrustada o una firma digital, se construye a partir de ocho tipos de objetos primitivos y la regla que permite que un objeto haga referencia a otro. Aprended esos y el resto del formato se lee como composición en lugar de misterio.
Esta es la capa lógica de PDF, definida en la cláusula 7.3 de ISO 32000-1, y se sitúa un nivel por encima del diseño físico del fichero (la cabecera, el cuerpo, la tabla de referencias cruzadas y el trailer, que es un tema propio en la descripción técnica de la estructura de ficheros PDF). El modelo lógico es lo que significan esos bytes una vez analizados. Un visor lee el fichero hacia atrás para encontrar el trailer, lo sigue hasta la raíz y desde ahí el documento se despliega como objetos que referencian objetos. Esta es la parte sobre la que se razona al depurar una página malformada, escribir un analizador o confiar en una biblioteca para ensamblar un documento.
Ocho tipos de objetos, y nada más
PDF define exactamente ocho tipos de objetos básicos. Cada valor en un documento es uno de ellos, que es lo que mantiene el formato manejable a pesar de su alcance.
Los booleanos son las palabras clave true y false. Activan y desactivan indicadores, como si una anotación se imprime.
Los números vienen en dos sabores que la especificación trata como un solo tipo: enteros como 42 y reales como 3.14 o -0.002. PDF no tiene notación exponencial, por lo que nunca se verá 1e6 en un fichero conforme. Las coordenadas, los tamaños de fuente y los ángulos de rotación son todos números.
Las cadenas contienen secuencias de bytes, escritas entre paréntesis, (Hello), o entre corchetes angulares en hexadecimal, <48656C6C6F>. Ambas notaciones codifican contenido idéntico; el hexadecimal es la vía de escape para bytes incómodos dentro de paréntesis. Las cadenas transportan texto, pero son bytes antes que nada, lo que importa en cuanto se maneja algo más allá de ASCII.
Los nombres son tokens atómicos introducidos por una barra inclinada: /Type, /Pages, /MediaBox. Un nombre no es una cadena; es un identificador, usado como clave de diccionario o valor enumerado, y dos nombres son iguales solo si coinciden byte por byte. La barra inclinada es sintaxis, no forma parte del nombre. Esto confunde a los recién llegados que tratan /Times-Roman y la cadena (Times-Roman) como intercambiables; el formato no lo hace.
Los arrays son listas ordenadas y heterogéneas entre corchetes: [0 0 612 792] es un rectángulo de página, y un array puede mezclar tipos libremente, incluyendo referencias a otros objetos. Los diccionarios son el caballo de batalla. Escritos entre << y >>, un diccionario mapea claves de nombre a valores de cualquier tipo, y casi toda estructura significativa en PDF, página, catálogo, fuente, anotación, es un diccionario con una clave /Type que declara lo que es.
Los flujos son diccionarios con una cola de bytes sin procesar entre las palabras clave stream y endstream. El diccionario describe los bytes (su longitud y cualquier filtro como FlateDecode que los comprima), y los bytes transportan la carga útil voluminosa: instrucciones de contenido de página, programas de fuentes incrustados, imágenes. Un flujo es donde PDF pone todo lo que es demasiado grande o demasiado binario para estar en línea.
El octavo tipo es el objeto nulo, la palabra clave null. Es un valor real, distinto de la ausencia de una clave. Una entrada de diccionario establecida a null se trata como si no estuviera presente, y una referencia que resuelve a un objeto inexistente también devuelve null en lugar de un error. Ese comportamiento indulgente es deliberado: permite que un fichero dañado se degrade en lugar de negarse a abrirse. No hay un noveno tipo; todo lo que PDF expresa proviene de cómo se combinan estos ocho.
Valores directos, objetos indirectos y referencias
Cualquiera de esos ocho tipos puede aparecer de dos formas. Un objeto directo se escribe en su lugar, como el 612 dentro de un array MediaBox. Un objeto indirecto recibe una identidad para que otros objetos puedan apuntarle: dos enteros, un número de objeto y un número de generación, que envuelven la definición en obj y endobj:
12 0 obj
<< /Type /Font /Subtype /Type1 /BaseFont /Helvetica >>
endobjEste es el objeto 12, generación 0, un diccionario de fuente. En cualquier otro lugar del fichero, otro objeto hace referencia a él con una referencia indirecta: los mismos dos números seguidos de la palabra clave R, 12 0 R. La referencia es un puntero. Cuando el diccionario de recursos de una página dice /Font << /F1 12 0 R >>, nombra el objeto 12 como la fuente detrás del nombre de recurso /F1, sin copiar la definición de la fuente en la página.
El número de generación existe para eliminaciones y reutilización. Cuando se libera un objeto y se reutiliza su ranura, la generación se incrementa para que un 12 0 R obsoleto no pueda resolver al nuevo inquilino de la ranura 12. Los ficheros recién escritos son casi todos generación 0, pero un fichero muy editado puede tener números más altos, y un analizador que ignore la generación eventualmente leerá el objeto incorrecto.
La indirección es lo que hace a PDF eficiente y editable. Una fuente, imagen o espacio de color puede definirse una vez y referenciarse desde cien páginas. Un pequeño cambio puede anexarse como una nueva revisión que reemplaza un único objeto en lugar de reescribir el fichero. La tabla de referencias cruzadas es el índice que convierte un número de objeto en un desplazamiento de bytes, de modo que el lector salta directamente a 12 0 obj sin escanear, pero esa es una optimización física. Lógicamente, todo lo que hay que saber es que 12 0 R significa «el objeto identificado como 12 0».
El catálogo: donde comienza cada documento
Resolver referencias tiene que comenzar en algún lugar, y ese lugar es la entrada /Root del trailer, que apunta al catálogo del documento: la raíz del grafo de objetos, un diccionario con /Type /Catalog. El lector lo alcanza primero porque el trailer se encuentra primero, y desde ahí cada otra parte del documento es alcanzable siguiendo referencias.
El catálogo lleva solo dos entradas estrictamente obligatorias: su /Type y /Pages, una referencia indirecta a la raíz del árbol de páginas. El resto son opcionales y describen el comportamiento a nivel de documento en lugar de contenido: /Outlines apunta al árbol de marcadores, /Names contiene árboles de nombres indexados por cadena, /Metadata hace referencia a un flujo de metadatos XMP, y /PageMode y /PageLayout sugieren cómo debería abrir el documento un visor. Ninguno de esos es necesario para renderizar una página; configuran la experiencia alrededor de las páginas. Las estructuras de marcadores, metadatos y anotaciones colgadas del catálogo se tratan en el artículo sobre metadatos, marcadores y anotaciones de PDF.
El diagrama siguiente muestra dónde se sitúa el cuerpo de objetos en el fichero circundante. El catálogo y el árbol de páginas viven dentro de ese cuerpo como objetos indirectos ordinarios; la cabecera, la tabla de referencias cruzadas y el trailer a su alrededor son el andamiaje físico que permite a un lector localizarlos.
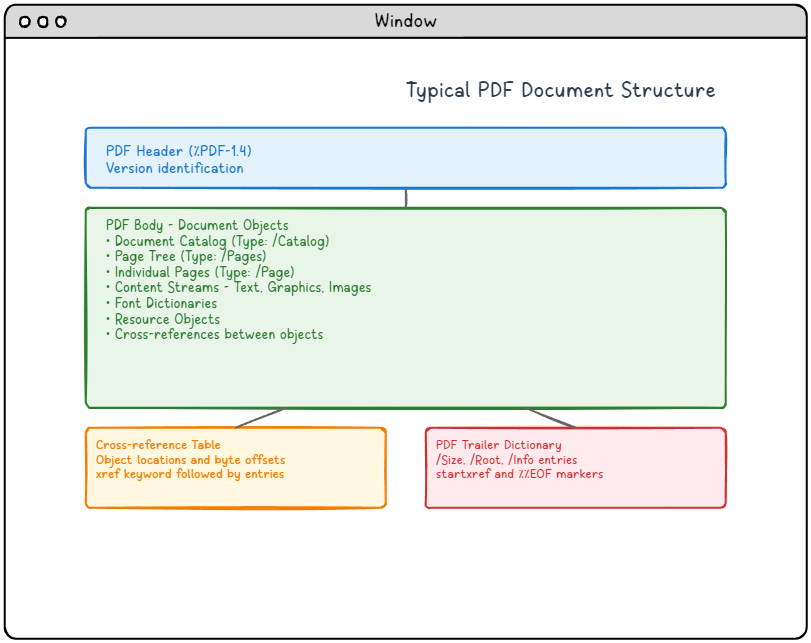
El árbol de páginas: una jerarquía equilibrada de páginas
Desde /Pages el documento se ramifica en el árbol de páginas, donde la elección de PDF de un grafo sobre una lista plana da sus frutos. Las páginas no se almacenan como una secuencia simple; cuelgan de un árbol cuyos nodos interiores son nodos de árbol de páginas (/Type /Pages) y cuyas hojas son objetos de página (/Type /Page). Un nodo interior lista sus hijos en un array /Kids y registra, en /Count, cuántas páginas hoja viven por debajo de él. Cada nodo excepto la raíz lleva una referencia /Parent hacia arriba, de modo que el árbol se recorre en ambas direcciones.
2 0 obj % root of the page tree
<< /Type /Pages /Kids [3 0 R 4 0 R] /Count 3 >>
endobj
3 0 obj % a leaf page
<< /Type /Page /Parent 2 0 R
/MediaBox [0 0 612 792]
/Resources << /Font << /F1 12 0 R >> >>
/Contents 5 0 R >>
endobj
4 0 obj % an interior node grouping two more pages
<< /Type /Pages /Parent 2 0 R /Kids [6 0 R 7 0 R] /Count 2 >>
endobjAquí el objeto 2 es la raíz, con tres páginas por debajo: la página hoja 3, más otras dos accesibles a través del nodo interior 4. El /Count de 3 de la raíz debe ser igual al total de hojas por debajo de ella, y un recuento que no concuerda con la estructura real es una forma habitual en que un fichero editado a mano sale mal. El propósito del árbol es la localidad de acceso. Un lector que abre la página 900 de un documento de mil páginas no recorre 900 objetos; desciende un puñado de nodos, porque un árbol bien formado permanece poco profundo y equilibrado. Construir ese árbol a mano es lo suficientemente laborioso como para que merezca verlo de principio a fin, lo cual hace el tutorial sobre construir un documento PDF desde cero.
El árbol gana su segundo valor a través de la herencia. Un puñado de atributos de página, /Resources, /MediaBox, /CropBox y /Rotate, pueden establecerse en un nodo interior y omitirse en las páginas individuales, que entonces heredan el valor del ancestro más cercano. Estableced /MediaBox una vez en la raíz y cada hoja obtiene el mismo tamaño de página sin repetirlo; una página que necesite diferir declara el suyo propio. Este es el único lugar en el modelo de objetos donde el significado de un valor depende de la posición de un objeto en el árbol, no solo de su propio contenido.
Qué contiene realmente una página hoja
Un objeto de página es el punto de unión entre el modelo estructural y el contenido visible. Su entrada /Contents hace referencia a uno o más flujos de contenido, los operadores de dibujo que pintan texto y gráficos en la página. Su diccionario /Resources nombra las fuentes, imágenes y espacios de color de los que dependen esos operadores, cada entrada una referencia indirecta a un objeto compartido entre páginas. El /MediaBox proporciona el rectángulo de página en puntos (1/72 de pulgada), y entradas como /Rotate y /CropBox ajustan cómo se presenta.
Esa división del trabajo es todo el modelo en miniatura. El diccionario de página es estructura: entradas tipadas y referencias que dicen qué es la página y con qué dibuja. El flujo de contenido son instrucciones: un blob separado y comprimible que dice cómo dibujar. La fuente detrás de /F1 es un recurso compartido, definido una vez y referenciado donde se use. Diccionario, flujo y referencia cooperan para renderizar una página, y los mismos patrones escalan a todo el documento. Los operadores del flujo de contenido dentro de ese blob se tratan por separado para texto y fuentes y para gráficos y elementos visuales.
Por qué vale la pena conocer este modelo
La mayoría de los desarrolladores se encuentran con el modelo de objetos solo cuando algo se rompe: una página se renderiza en blanco porque su referencia /Contents cuelga de la nada, el texto aparece como cuadros porque un recurso de fuente nunca se incrustó, una herramienta informa de un /Count que no coincide con las páginas que puede encontrar. Cada uno de esos es una afirmación sobre el grafo, y leer el grafo directamente es mejor que adivinar. Los ocho tipos y la regla de referencias son un vocabulario lo suficientemente pequeño como para tenerlo en la cabeza, y una vez que se ve un PDF como objetos que apuntan a objetos, los ficheros malformados dejan de ser opacos.
Dicho esto, escribir el modelo a mano rara vez es la decisión correcta más allá del aprendizaje. Mantener coherentes los desplazamientos de referencias cruzadas, los números de generación, los recuentos del árbol de páginas y las longitudes de flujo a través de las ediciones es exactamente el tipo de contabilidad para el que existe una biblioteca. En producción, una biblioteca de desarrollo PDF madura gestiona el grafo de objetos mientras deja pensar en páginas y contenido. Conocer el modelo sigue siendo rentable: se entiende lo que la biblioteca construye por debajo, y por qué.