掌握 PDF 文本和字型:開發人員指南
PDF 文件徹底改變了我們在不同平臺和裝置上共享和儲存格式化文本的方式。但在每個 PDF 的精美表面下,隱藏著一個複雜的文本渲染系統,它將高階排版概念與精確的數學運算相結合。瞭解 PDF 如何處理文本和字型對於從事文件生成、文本提取或 PDF 處理的開發人員至關重要。
本全面的指南將帶您深入瞭解 PDF 文本渲染的世界,探索從基本的字元間距到複雜的字型嵌入技術、字元編碼系統以及文本提取的複雜挑戰。無論您是經驗豐富的開發人員還是剛剛開始使用 PDF 技術,您都將獲得對這些無處不在的文件如何實際運作的寶貴見解。
PDF 文本渲染背後的哲學
當 Adobe 建立 PDF 格式時,他們面臨著一項根本的設計挑戰,這將影響數十億文件的渲染方式。問題是:如何在靈活性和一致性之間取得平衡,以確保文件在各種不同的系統上看起來完全相同,從高解析度印表機到移動裝置。
他們可以選擇兩種極端的方法:
- 動態佈局方法: 儲存純文本以及佈局指令,類似於桌面出版軟體的工作方式,從而在檢視過程中實現即時文本流程和格式計算。
- 純圖形方法: 在建立過程中,將所有文本轉換為向量圖形,以確保完美的視覺一致性,但完全喪失了所有語義資訊和基於文本的功能。
另一方面,PDF 採用了一種我們可以稱之為“黃金比例”的方法,這是一種複雜的折衷方案,它結合了兩者的優點,同時避免了各自的缺點。這種混合系統保留了字型和字元的基本概念,同時在文件建立過程中預先計算了大部分佈局決策。
PDF 方法的戰略優勢
完整的佈局控制和可預測性
諸如段落換行、行間距、列寬和頁面佈局等大規模的格式化決策,由建立應用程式在 PDF 建立過程中處理。這意味著您的文件無論是在東京的智慧手機上檢視,還是在矽谷的 4K 監視器上顯示,或者在紐約的雷射印表機上列印,外觀都將完全相同。佈局的完整性在所有檢視場景中都保持不變,從而消除了其他文件格式中常見的不可預測的自動換行問題。
可預測的小規模排版
諸如字元定位、單詞間距和字型縮放等小規模的文本操作,通過一套完善且明確定義的運算子進行標準化。這允許對排版進行精細控制,同時在不同的 PDF 檢視器和處理器中保持可預測的行為。該系統支援高階排版功能,如字間距、連字和上下文字元替換,同時確保獲得一致的結果。
高效的儲存和資源管理。
通過將字型視為可重用的字元形狀庫,即使是文本密集型的PDF檔案也能保持相對較小的體積。與其單獨儲存每個字母的向量輪廓,文件會引用共享的字型定義,這些定義可以在多個頁面甚至多個文件中重用。這種方法在顯著減小檔案大小的同時,還支援高階的字型子集和嵌入策略。
語義保留,用於輔助功能。
與純圖形方法不同,PDF 保持了視覺符號與其底層字元程式碼之間的關鍵聯絡。這種保留使得重要的功能成為可能,例如文本搜尋、複製和貼上操作、螢幕閱讀器輔助功能以及自動內容分析。該格式支援 Unicode 對映、替代文本描述以及標記結構資訊,從而使文件能夠被輔助技術訪問。
完整的 PDF 文本狀態系統。
PDF 的文本渲染系統通過一套複雜的引數集合來執行,這些引數協同工作,控制文本在頁面上呈現的各個方面。可以將這些引數視為一個全面的控制面板,它不僅控制基本的顯示效果,還控制高階的排版特性、定位計算和渲染最佳化。
完整的文本狀態引數系統包括:
| Parameter | Operator | Description | Default Value |
|---|---|---|---|
| Character Spacing | Tc | Additional space between characters | 0 |
| Word Spacing | Tw | Additional space between words | 0 |
| Horizontal Scaling | Tz | Horizontal scaling percentage | 100 |
| Leading | TL | Line spacing for T* operator | 0 |
| Font and Size | Tf | Font selection and scaling | N/A |
| Text Rendering Mode | Tr | Fill, stroke, or path mode | 0 (Fill) |
| Text Rise | Ts | Vertical text displacement | 0 |
字元間距 (Tc Operator) – 精確的排版控制。
字元間距引數提供對文本字串中每個字元之間額外空格的精細控制。此引數以文本空格單位為單位進行測量,通常為字型大小的 1/1000,從而實現極其精確的調整。
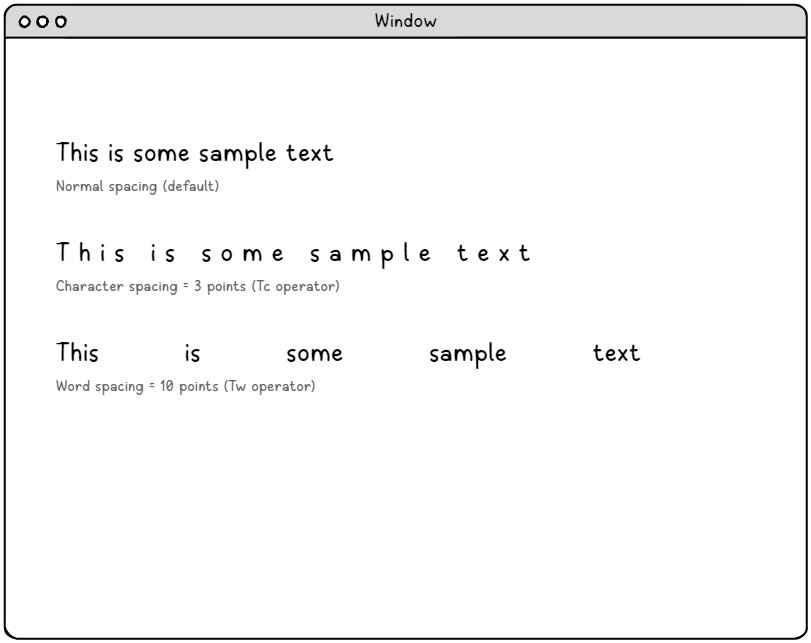
字元間距的應用包括:
- 排版增強: 在標題和正文中建立強調或提高可讀性。
- 文本對齊支援: 調整對齊文本佈局中的行長度。
- 品牌一致性: 匹配企業指南要求的特定排版風格。
- 可訪問性: 提高閱讀障礙或視力障礙使用者的可讀性。
|
1 2 3 4 5 6 7 8 9 10 11 |
BT /F0 24 Tf 1 0 0 1 50 700 Tm (Normal text spacing) Tj 0 -30 Td 3 Tc (Character spacing = 3 points) Tj 0 -30 Td -1 Tc (Tight character spacing = -1 point) Tj ET |
單詞間距 (Tw 運算子) – 智慧間距管理。
單詞間距專門針對文本字串中的空格字元 (ASCII 32),提供對單詞間距的精確控制,而不會影響其他空白字元。 這種精確的控制對於文本對齊演算法和建立專業文件佈局非常有用。
Tw 運算子展示了 PDF 對排版的精細方法,因為它認識到不同型別的間距具有不同的目的。 雖然字元間距會影響所有字元,但單詞間距僅影響實際的單詞邊界,從而使設計師能夠精確控制文本的流程和可讀性。
|
1 2 3 4 5 6 7 8 9 10 11 |
BT /F0 24 Tf 1 0 0 1 50 600 Tm (Normal word spacing) Tj 0 -30 Td 10 Tw (Extended word spacing improves readability) Tj 0 -30 Td -2 Tw (Compressed word spacing saves space) Tj ET |
水平縮放 (Tz 運算子) – 維度排版控制。
水平縮放允許您在不影響其高度的情況下,水平拉伸或壓縮文本,以百分比表示,其中 100% 表示正常寬度。 此引數支援響應式排版調整和特殊的排版效果,而這些效果在傳統的排版方法中是無法實現的。
水平縮放的應用:
- 空間受限的佈局: 將文本適配到預定的列寬或設計元素中。
- 樣式效果: 為標題和強調文本建立壓縮或擴充套件版本。
- 字型模擬: 在字型不可用時,近似模擬壓縮或擴充套件的字型變體。
- 響應式設計: 在保持可讀性的同時,將文本適配到不同的頁面尺寸。
然而,水平縮放應謹慎使用。 過度縮放會損害可讀性,併產生不自然的文本,從而破壞閱讀體驗。 最佳實踐建議將縮放限制在正文文本的 85-115% 範圍內,而更大幅的縮放應保留用於顯示目的。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
BT /F0 24 Tf 1 0 0 1 50 500 Tm 100 Tz (Normal horizontal scaling - 100%) Tj 0 -30 Td 80 Tz (Condensed text - 80% scaling) Tj 0 -30 Td 120 Tz (Extended text - 120% scaling) Tj ET |
行高 (TL Operator) – 垂直節奏和可讀性
行高,發音為“ledding”,源於傳統的排版,其中在行間插入薄的鉛條。 在 PDF 中,行高決定了文本基線之間的垂直空間,並控制文本在 T* (移動到下一行) 運算子使用時的位置移動程度。
適當的行高對於建立文本的可讀垂直節奏至關重要。 字型大小和行高之間的關係對可讀性、理解速度和整體文件美觀性有重要影響。 排版專家通常建議行高值在字型大小的 120% 到 145% 之間,以獲得最佳的可讀性。
行高注意事項:
- 字型大小關係: 通常,較大的字型需要成比例更大的行高。
- 行長影響: 較長的行需要增加行間距,以幫助讀者更容易地回到下一行的開頭。
- 字型特徵: 具有較大字高或裝飾性元素的字型可能需要調整行間距。
- 閱讀環境: 不同型別的內容(正文、標題、說明)需要不同的行間距。
|
1 2 3 4 5 6 7 8 9 10 |
BT /F0 18 Tf 18 TL 1 0 0 1 50 400 Tm (This text uses 18pt leading) Tj T* (which matches the font size) Tj T* 24 TL (This text uses 24pt leading) Tj T* (providing more generous spacing) Tj T* ET |
文本垂直位置調整 (Ts Operator) – 垂直定位精度
文本垂直位置調整功能提供精細的垂直調整能力,允許您在不影響整體文本流程的情況下,將文本向上或向下移動。此引數對於建立需要精確垂直位置的專業排版元素至關重要。

文本垂直位置調整的應用包括:
- 數學符號: 排列上標、下標和數學符號。
- 科學內容: 化學公式、分子結構和科學註釋。
- 編輯元素: 註釋標記、商標符號和版權宣告。
- 多語言排版: 調整不同書寫系統的基線位置。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
BT /F0 36 Tf 1 0 0 1 140 290 Tm (H) Tj -8 Ts /F0 24 Tf (2) Tj 0 Ts /F0 36 Tf (O represents water with O) Tj 8 Ts /F0 24 Tf (2) Tj 0 Ts /F0 36 Tf ( as oxygen) Tj ET |
高階文本變換和矩陣運算。
PDF 最強大的功能之一是其能夠通過雙矩陣系統無縫地將文本變換與圖形變換結合起來。這種能力可以在保持數學精度以確保在不同檢視條件下文本位置操作的一致性的同時,實現複雜的佈局效果。

變換系統通過兩個主要矩陣執行:
當前變換矩陣 (CTM)。
CTM 用於處理影響所有圖形元素的全域性座標變換,包括文本。它管理諸如旋轉、縮放、平移和傾斜等在頁面級別的操作。當您使用諸如 cm (concatenate matrix) 之類的運算子應用變換時,您正在修改 CTM。
文本矩陣 (TM)。
TM 專門處理文本定位和區域性文本變換。它與 CTM 協同工作,以確保文本定位操作(如換行、字元前進和段落流程)即使在整個文本塊被變換時也能正常工作。
矩陣變換序列。
當 PDF 渲染轉換後的文本時,它遵循一個精確的數學序列。
- 字形間距計算: 字元的形狀在字形空間座標系中定義。
- 文本空間變換: 字元的位置使用字型大小和文本狀態引數在文本空間中確定。
- 文本矩陣應用: 文本矩陣將座標從文本空間轉換為使用者空間。
- 圖形矩陣應用: 當前的變換矩陣用於最終的定位和方向調整。
- 裝置空間轉換: 最終座標轉換為特定於裝置的單位,用於渲染。
這個多階段過程確保文本變換在數學上精確,並且在不同的顯示條件、輸出裝置和縮放因子下,視覺上保持一致。
|
1 2 3 4 5 6 7 8 9 10 11 |
% Set up rotation transformation 0.96 0.25 -0.25 0.96 0 0 cm BT /F0 48 Tf 48 TL % Set text matrix for positioning 1 0 0 1 270 240 Tm (Text and graphics) Tj T* (transforms combined) Tj T* (with proper newlines) Tj ET |
文本變換的實際應用。
- 旋轉的標題和標籤: 建立傾斜的文本,用於圖表、圖解和特殊佈局。
- 藝術排版: 在保持可讀性的同時,實現創意的文本效果。
- 多方向文件: 支援包含混合縱向和橫向元素的文件。
- 座標系統對齊: 將文本方向與現有的圖形座標系統匹配。
完整的字型選擇和資源管理。
PDF 中的字型處理涉及一個複雜的資源管理系統,其功能遠不止簡單的字型選擇。該系統必須高效地管理字型資源、字元編碼方案、縮放操作以及相容性要求,同時在各種觀看環境中保持最佳的渲染效能。
字型資源字典系統。
PDF 文件維護一種分層字型字典結構,該結構將符號名稱對映到實際的字型資源。這一間接層在文件架構中具有多個關鍵作用:
- 資源最佳化: 多個頁面和內容流可以共享相同的字型資源,而無需重複。
- 替換控制: 可以在資源級別實現字型回退機制,而不會影響內容流。
- 編碼管理: 字元編碼方案可以與特定的字型例項相關聯。
- 效能提升: 字型載入和解析可以通過智慧快取策略進行最佳化。
字型型別和技術特性。
Type 1 (PostScript) 字型。
Type 1 字型代表 Adobe 最初的可縮放字型技術,使用三次貝塞爾曲線以數學精度定義字元輪廓。由於其出色的可縮放特性和複雜的襯線系統,這些字型在專業出版應用中表現出色。
Type 1 字型的主要特性:
- 三次貝塞爾曲線輪廓: 數學上精確的曲線定義,可以平滑地縮放到任何尺寸。
- PostScript 襯線: 智慧輪廓調整,可在小尺寸下實現最佳渲染效果。
- 編碼靈活性: 支援自定義字元編碼和專用字元集。
- 嵌入相容性: 完整嵌入支援,幷包含遵守許可機制。
TrueType 字型。
TrueType 字型使用二次貝塞爾曲線,幷包含專門針對螢幕顯示和低解析度輸出裝置最佳化的高階提示資訊。TrueType 字型最初由 Apple 開發,後被 Microsoft 採用,具有出色的跨平臺相容性。
TrueType 優勢:
- 螢幕最佳化: 針對畫素網格對齊進行了最佳化的高階提示系統。
- 平臺相容性: 廣泛支援各種作業系統和應用程式。
- 緊湊儲存: 使用二次曲線實現的有效輪廓表示。
- Unicode 支援: 原生支援大型字元集和國際文本。
OpenType 字型
OpenType 代表著數字排版的演進,它結合了 Type 1 和 TrueType 字型的最佳技術特性,同時增加了革命性的排版功能,從而改變了專業文本的呈現方式。
OpenType 的創新:
- 高階排版: 上下文連字、花體、替代字和風格集
- 龐大的字元集: 支援數千個字元和多種書寫系統
- 佈局智慧: 複雜的上下文字元替換和定位規則。
- 跨平臺一致性: 在不同的系統和應用程式中,具有相同的渲染行為。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
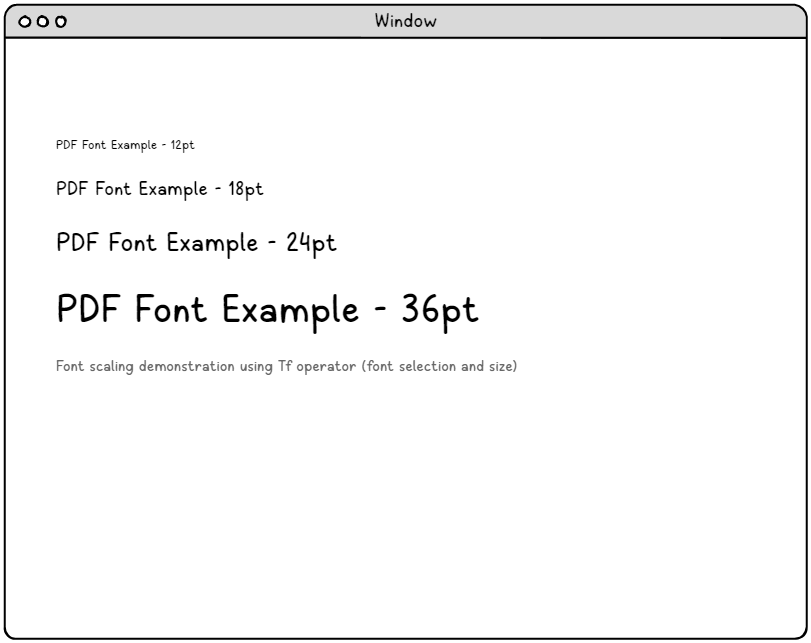
BT % Select font and set initial size /F0 12 Tf 1 0 0 1 50 750 Tm (12-point font example) Tj % Change to larger size, same font /F0 18 Tf 0 -25 Td (18-point font example) Tj % Even larger size /F0 24 Tf 0 -35 Td (24-point font example) Tj % Largest size /F0 36 Tf 0 -50 Td (36-point font example) Tj ET |
專業級的字間距和字形定位。
專業排版對單個字元之間的間距需要精確的控制。不同字母組合之間的視覺空間差異很大,這取決於字元的形狀,因此,智慧的字間距調整對於建立視覺上吸引人且高度可讀的文本至關重要,以滿足專業的出版標準。

TJ 運算子提供了先進的字形定位功能,超越了簡單的字元和單詞間距控制。與處理單一文本字串不同,TJ 接受一個異構陣列,從而可以實現具有數學精度的字元級別的定位控制。
理解 TJ 陣列架構。
TJ 運算子的基於陣列的方法通過接受混合內容,徹底改變了文本定位:
- 字串元素: 包含要渲染的實際文本內容,使用標準字型編碼。
- 數字元素: 指定水平調整量,以文本空格單位的千分之一為單位。
- 負值: 使後續字元更靠近,減小字元間距。
- 正值: 增加字元之間的間距,擴充套件文本佈局。
這種精細的控制,可以實現專業級的排版效果,通過精確的字間距調整,這是使用更簡單的文本操作無法實現的。該系統既可以進行美觀方面的改進,也可以對字型的各項引數進行技術性校正。
|
1 2 3 4 5 6 7 8 9 |
BT /F0 48 Tf 1 0 0 1 100 400 Tm % Standard text rendering (WAVE Type) Tj 0 -60 Td % Kerned text with precise adjustments [(W) -120 (A) -80 (V) -100 (E) 50 (T) -20 (y) -10 (p) -5 (e)] TJ ET |
高階字間距調整策略
光學字間距
光學字間距根據字元組合的視覺外觀來調整字元間距,而不是僅僅依賴於內建的字型引數。這種方法考慮了相鄰字元的實際形狀以及它們之間的視覺互動。
引數字間距
引數字間距使用字型的內建字間距表來調整特定字元對之間的間距。專業的字型通常包含大量的字間距表,其中包含數千個字元對的調整。
手動字間距
手動字間距允許對特定字元進行精確的調整,以滿足特定的設計要求,或者糾正那些無法通過自動字間距系統充分解決的字元組合問題。
實用字間距調整應用
- 標誌和品牌: 精確控制企業形象字型
- 標題字型: 最佳化大字型的視覺效果
- 精細字型: 實現出版級文本排版
- 多語言支援: 調整不同書寫系統和字元組合的間距。
文本渲染模式和視覺效果。
PDF 提供了八種不同的文本渲染模式,用於控制文本的視覺呈現方式,從而提供廣泛的靈活性,可以建立各種排版效果。這些模式決定了文本是填充、描邊、用於裁剪路徑,還是以不可見的方式呈現,以用於特殊目的。
完整的文本渲染模式參考。
| Mode | Name | Visual Effect | Common Uses |
|---|---|---|---|
| 0 | Fill | Solid color fill only | Standard body text |
| 1 | Stroke | Outline only, no fill | Decorative headers |
| 2 | Fill and Stroke | Both fill and outline | Emphasized text |
| 3 | Invisible | No visual rendering | Text positioning |
| 4 | Fill and Add to Path | Fill plus path construction | Text-based clipping |
| 5 | Stroke and Add to Path | Stroke plus path construction | Complex path operations |
| 6 | Fill, Stroke, and Add to Path | Complete text with path | Advanced graphics integration |
| 7 | Add to Path Only | Path construction, no rendering | Clipping path creation |
高階渲染模式應用。
不可見文本模式(模式 3)。
不可見文本在 PDF 文件中具有多種專門用途:
- 可搜尋的影像 PDF。 在掃描文件上疊加不可見文本,以實現搜尋功能。
- 文本定位: 在複雜佈局中,無需視覺輸出即可調整文本位置。
- 輔助功能增強: 提供替代文本描述,且不產生視覺干擾。
- 模板系統: 建立定位框架,用於動態內容生成。
路徑構建模式(模式 4-7)。
這些高階模式可以實現文本系統和圖形系統之間的複雜整合。
- 基於文本的裁剪: 使用文本形狀裁剪其他圖形元素。
- 複雜蒙版: 使用字元形狀建立複雜的蒙版效果。
- 藝術效果: 將文本與漸變、圖案和其他圖形元素結合使用。
- 互動元素: 建立精確匹配文本邊界的可點選區域。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
BT /F0 36 Tf 1 0 0 1 100 500 Tm % Standard filled text 0 Tr (Filled Text) Tj 0 -50 Td % Stroked text only 1 Tr 2 w (Stroked Text) Tj 0 -50 Td % Both filled and stroked 2 Tr (Filled and Stroked) Tj ET |
字型嵌入和子集最佳化。
字型嵌入是 PDF 建立中最關鍵的技術挑戰之一,需要在文件可移植性、檔案大小最佳化和法律合規性之間取得平衡。嵌入系統必須確保文件在不同系統上的顯示一致,同時遵守字型許可限制並保持合理的檔案大小。
字型嵌入策略。
完整字型嵌入。
完整字型嵌入將整個字型檔案包含在 PDF 文件中,以確保完美的渲染相容性,但會增加檔案大小。這種方法可確保所有字元、字距資訊和排版特性都可用。
優點:
- 完整相容性: 無論目標系統如何,所有字型功能均保持可用。
- 渲染保真度: 完美再現原始的排版和間距。
- 功能保留: 高階 OpenType 功能仍然可用。
- 具有前瞻性: 即使字型可用性發生變化,文件仍然可讀。
缺點:
- 檔案大小影響: 文件大小顯著增加,尤其是在使用多個字型時。
- 授權問題: 可能違反字型授權協議,這些協議限制了字型的嵌入。
- 處理開銷: 加大了字型載入所需的記憶體和處理時間。
字型子集化:
字型子集化僅嵌入文件中實際使用的字元,從而顯著減小檔案大小,同時保持所包含字元集的渲染準確性。
子集優勢:
- 最佳檔案大小: 在保留排版的同時,對文件大小的影響最小。
- 許可合規性: 減少法律風險,因為只包含使用的字元。
- 效能提升: 加快字型載入速度並減少記憶體使用。
- 頻寬效率: 較小的文件可以通過網路更快地傳輸。
字元編碼和 Unicode 對映。
PDF 的字元編碼系統必須彌合字型特定的字元程式碼與通用字元識別系統(如 Unicode)之間的差距。這個對映過程對於文本提取、搜尋和輔助功能至關重要。
編碼機制。
內建編碼: 使用字型的內部字元對映,適用於標準的西方字元集,但對於國際內容有限。
標準 PDF 編碼: 預定義的編碼方案,如 WinAnsiEncoding 和 MacRomanEncoding,可在不同平臺上提供一致的字元對映。
自定義編碼: 特定於文件的字元對映,用於支援特殊字元或舊字體系統。
Unicode (CMap) 系統: 現代方法,使用字元對映 (CMaps),提供字元程式碼和 Unicode 值之間的直接對映。
ToUnicode 對映表:
ToUnicode CMaps 通過提供字型特定字元程式碼和 Unicode 值之間的橋樑,實現準確的文本提取和搜尋。這些對映表對於可訪問性和內容分析至關重要。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
% Example ToUnicode CMap structure 23 0 obj << /Length 317 >> stream /CIDInit /ProcSet findresource begin 12 dict begin begincmap /CIDSystemInfo << /Registry (Adobe) /Ordering (UCS) /Supplement 0 >> def /CMapName /Adobe-Identity-UCS def 1 begincodespacerange <0001> endcodespacerange 2 beginbfchar <0001> <0041> % Map glyph 1 to Unicode U+0041 (A) <0002> <0042> % Map glyph 2 to Unicode U+0042 (B) endbfchar endcmap CMapName currentdict /CMap defineresource pop end end endstream endobj |
PDF 文本提取的複雜挑戰:
從 PDF 文件中提取文本是 PDF 處理中最具技術挑戰性的方面之一,需要複雜的演算法來從以圖形為導向的格式重建邏輯閱讀順序。與傳統文本格式不同,PDF 將文本儲存為一系列定位的圖形元素,這使得提取成為一個複雜的逆向工程過程。
基礎提取挑戰
非順序文本定位
PDF 內容流根據視覺佈局要求而非邏輯閱讀順序來定位文本元素。一個段落可能由數十個分散在內容流中的文本定位命令表示,這些命令與圖形操作和其他非文本元素交織在一起。
這種定位方法會產生以下提取難題:
- 恢復閱讀順序: 確定非按順序排列的文本元素的正確順序。
- 柱檢測: 識別多欄佈局並確定正確的欄佈局。
- 頁面結構分析: 區分頁首、頁尾、側邊欄和主要內容區域。
- 交叉引用解析: 連線由圖形或格式分隔的關聯文本元素。
字型和編碼問題。
字元提取需要準確解釋字型編碼方案,而這些方案在不同的字型和文件建立系統中可能存在很大差異。
- 缺少字型資訊: 文件可能引用提取系統上不可用的字型。
- 編碼變體: 不同的字型可能使用不相容的字元編碼方案。
- 字型子集限制: 嵌入的字型子集可能缺乏完整的字元對映資訊。
- Unicode 對映錯誤: 不正確或缺失的 ToUnicode 表格可能導致字元錯誤解釋。
佈局結構識別。
專業的文件採用複雜的佈局結構,這給自動提取系統帶來了挑戰。
- 表格識別: 識別表格資料並保持行/列關係。
- 列表結構: 識別帶有正確層級結構的無序列表和有序列表。
- 浮動元素: 處理中斷正常文本流程的文本框、側邊欄和提示框。
- 多頁連續性: 保持段落和章節在分頁之間的上下文連貫性。
高階提取方法.
多輪分析方法.
複雜的提取系統採用多輪分析,每輪分析側重於文件結構的不同方面:
- 字元級別分析: 提取單個字元的位置、字型和編碼資訊.
- 單詞形成分析: 根據空格和字型特徵將字元分組為單詞.
- 行檢測分析: 使用基線分析和垂直間距模式識別文本行。
- 段落組裝階段: 根據縮排和間距提示將行組合成段落。
- 結構分析階段: 檢測標題、列表、表格和其他文件元素。
- 內容組織階段: 將元素組織成邏輯閱讀順序和層次結構。
機器學習增強。
現代提取系統越來越多地採用機器學習技術來提高準確性。
- 版面分類: 訓練模型以識別常見的文件版面模式。
- 閱讀順序預測: 使用神經網路來確定最佳文本序列。
- 內容型別識別: 自動將文本元素分類為標題、正文、標題等。
- 表格結構檢測: 高階演算法,用於複雜表格佈局的識別。
文本提取程式碼示例。
以下示例演示了從 PDF 定位命令重建文本所涉及的複雜性。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
% Complex text positioning that challenges extraction BT /F0 12 Tf 1 0 0 1 72 720 Tm (This text appears) Tj 150 0 Td (out of order) Tj -150 -15 Td (in the content stream) Tj 200 0 Td (but should be) Tj -200 -15 Td (reconstructed properly) Tj 100 0 Td (by extraction algorithms.) Tj ET % Graphics elements that interrupt text flow q 1 0 0 1 100 650 cm 0.5 g 0 0 200 50 re f Q % Continuation of text after graphics BT /F0 12 Tf 1 0 0 1 72 630 Tm (Text continues after graphics elements) Tj ET |
質量保證與驗證。
專業的提取系統實現了多種驗證機制。
- 語言分析: 字典檢查和語法驗證,用於識別提取錯誤。
- 格式一致性: 驗證提取的結構是否符合常見的文件模式。
- 交叉引用驗證: 確保內部文件引用保持完整。
- 字元編碼驗證: 檢測和糾正字元編碼錯誤。
效能最佳化和最佳實踐。
高效的 PDF 文本處理需要仔細關注效能因素,這些因素會顯著影響渲染速度、記憶體使用情況以及整體系統響應速度。 現代 PDF 應用程式必須處理從簡單的單頁檔案到複雜的數千頁出版物。
字型資源管理。
智慧快取策略
字型載入和解析是耗費資源的操作,可以通過策略性快取獲得顯著的效能提升:
- 資源級別快取: 在資源字典級別快取解析後的字型物件,以避免重複解析。
- 字形渲染快取: 儲存渲染後的字元字形,以便在多個文本操作中重複使用。
- 度量計算快取: 快取字型度量計算結果,以避免重複計算。
- 跨文件快取: 在適當情況下,在多個 PDF 文件中共享字型資源。
記憶體管理策略:
有效的記憶體管理可以防止文本密集型應用程式出現效能下降。
- 延遲載入: 僅在需要進行渲染或處理時才載入字型資源。
- 資源池: 維護常用的字型物件的池,以減少分配開銷。
- 垃圾回收最佳化: 實現智慧清理策略,用於未使用的字型資源。
- 記憶體對映: 使用記憶體對映檔案來儲存大型嵌入式字型,以減少 RAM 使用量。
文本流最佳化。
內容流組織。
高效地組織文本操作可以顯著提高渲染效能:
- 批次文本操作: 將相關的文本操作組織在單個開始/結束塊 (BT/ET) 中,以減少狀態變化。
- 儘量減少字型切換。 組織內容以減少字型選擇操作。
- 策略性定位: 在適當情況下,使用相對定位 (Td, TD) 而不是絕對定位 (Tm)。
- 狀態合併: 將相容的文本狀態更改合併到單個操作中。
渲染管道最佳化。
現代 PDF 處理程序採用複雜的渲染流程。
- 多執行緒: 並行處理獨立的文本元素。
- GPU 加速: 硬體加速的字形柵格化和合成。
- 漸進渲染: 在後臺處理的同時顯示文本內容。
- 視口裁剪: 跳過處理超出可見區域的文本元素。
輔助功能與通用設計。
建立可訪問的 PDF 文件需要仔細關注文本結構、語義標記以及輔助技術相容性。現代輔助功能標準要求 PDF 文件能夠與螢幕閱讀器、語音識別軟體和其他輔助技術無縫協作。
標記的 PDF 結構。
標記的 PDF 提供語義結構資訊,使輔助技術能夠理解文件的組織方式。
- 邏輯結構樹: 文件元素的層次結構組織。
- 基於角色的標記: 語義化識別標題、段落、列表和其他元素。
- 閱讀順序規範: 明確定義正確的閱讀順序。
- 替代描述: 圖形元素和複雜結構對應的文本替代內容。
國際文本支援。
全域性文件的可訪問性需要全面的國際文本支援。
- Unicode 相容性: 完全支援國際字元集和書寫系統。
- 雙向文本: 妥善處理混合左向右和右向左內容。
- 複雜文字: 支援對阿拉伯語、印度語和其他複雜書寫系統中的上下文字元進行整形。
- 垂直文本支援: 傳統中文、日語和蒙古文的垂直文本佈局。
PDF排版方面的未來發展。
PDF 規範持續發展,融入了新的功能,以滿足數字文件工作流程、Web 整合和高階排版應用中的新興需求。
新一代排版功能
可變字型技術
可變字型代表著數字排版領域的革命性進步,允許單個字型檔案包含多種設計變體:
- 粗細變化: 從細到粗的連續調整
- 寬度變化: 動態的壓縮到擴充套件的寬度調整
- 光學尺寸: 自動最佳化以適應不同的顯示尺寸。
- 自定義軸: 特定字型的變體,例如對比度、x高度或風格變體。
彩色字型整合。
高階彩色字型可以實現以前使用傳統字型無法實現的豐富排版效果。
- 嵌入式圖形: 包含完整彩色點陣圖或向量圖形的字型。
- 漸變支援: 具有複雜色彩過渡和效果的字元。
- 多層字型: 具有單獨圖層的字型,用於陰影、輪廓和裝飾元素。
- 動畫排版: 基於時間的排版效果,適用於數字演示。
Web 和移動端整合。
隨著 PDF 文件越來越多地出現在 Web 和移動端環境,新的功能重點在於響應式和自適應排版。
- 漸進式文本載入: 通過後臺字型載入,實現更快的初始顯示.
- 響應式排版: 針對不同的螢幕尺寸和方向,實現自適應文本重排.
- 觸控最佳化互動: 增強了觸控式螢幕裝置的文本選擇和互動功能.
- 高 DPI 支援: 針對高解析度顯示器,進行了最佳化渲染.
結論。
PDF文本系統的複雜性反映了數十年在數字排版和文件技術方面的演進。每個運算子、引數和編碼方案在專業文件生產的整個生態系統中都具有特定的用途。字型嵌入策略、字元編碼系統、變換矩陣和渲染模式協同工作,共同構建了一個強大的文本通訊平臺。
在您繼續使用PDF文本和字型時,請記住,規範的複雜性具有重要的作用:確保文件的永續性、保持視覺保真度、支援國際內容以及實現可訪問性。這些基本概念將在PDF技術不斷發展並適應數字通訊中的新挑戰時為您提供幫助。