瞭解 PDF 的內部結構。
歡迎來到引人入勝的 PDF 內部世界! 您是否曾想過是什麼讓 PDF 檔案正常工作? 在我們每天看到的常見文件背後,隱藏著一種複雜的架構,它徹底改變了數字文件的共享方式。 在這次全面的探索中,我們將揭示 PDF 結構的各個層面,從而瞭解這些無處不在的檔案是如何工作的。
🔍 簡介:超越表面。
可移植文件格式 (PDF) 已經成為全球文件交換的事實標準。 從簡單的文本文件到複雜的互動式表單,PDF 可以在不同的平臺和裝置上保持一致的外觀。 但是,這種通用相容性之下隱藏著什麼?
在這次深入研究中,我們將探索使 PDF 檔案真正具有可移植性的邏輯結構。 我們將研究基本構建塊: trailer dictionary (trailer 字典), document catalog (文件目錄)以及 頁面樹——這三者共同協調,控制著每個 PDF 的功能。 我們還將揭示 PDF 中用於文本字串和日期的專用資料格式的秘密。
🎯 本指南將教您:
- PDF 結構中的四個基本元件
- PDF 如何高效地組織和引用內容
- 字典、目錄和頁面樹的作用
- PDF 在文本編碼和日期格式方面的獨特方法
- PDF物件結構的實際示例。
- 瞭解PDF內部的最佳實踐。
📋 PDF解剖:高層概述。
在深入細節之前,讓我們建立一個關於PDF結構的思維模型。將PDF視為一種複雜的檔案系統,其中每條資訊都有其特定的位置和用途。
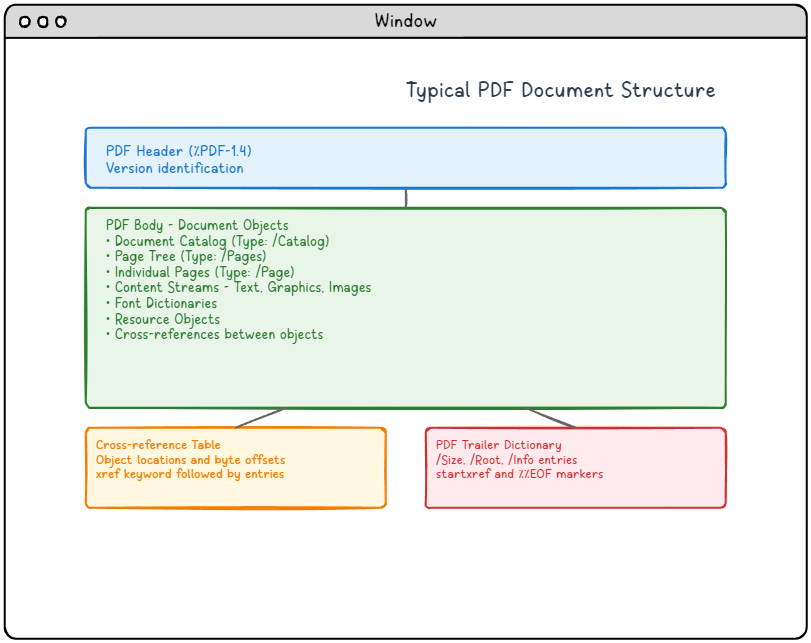
圖1: 典型的PDF文件結構,顯示了四個主要元件及其關係。
PDF結構圖的詳細描述:
此圖說明了PDF文件的典型結構,其中包含四個主要元件,垂直排列:
-
- PDF 頭部(頂部藍色區域): 包含版本標識(%PDF-1.4),用於指定 PDF 格式版本。
- PDF 主體(中部綠色區域): 最大的區域,包含所有文件物件,包括文件目錄、頁面樹、各個頁面、包含文本/圖形/影像的內容流、字型字典、資源物件以及物件之間的交叉引用。
- 交叉引用表(左下角橙色區域): 包含物件位置和位元組偏移量,以 xref 關鍵字開頭,後跟條目。
- PDF 尾部字典(右下角紅色區域): 包含必要的導航資訊,包括 /Size、/Root、/Info 條目,並以 startxref 和 %%EOF 標記結尾。
箭頭顯示了從標題到正文的邏輯流程,然後分支到交叉引用表和尾部字典,說明了 PDF 閱讀器如何瀏覽文件結構。
一個 PDF 文件由四個主要結構元素協同工作組成。
🏗️ PDF 結構的核心支柱:
- 標題 (Header) – 標識 PDF 版本和功能。
- 正文 (Body) – 包含所有文件物件(文本、影像、字型等)。
- 交叉引用表 (Cross-reference Table) – 對映物件位置,以便快速訪問。
- 預告片。 – 提供進入文件的入口。
這種結構使 PDF 能夠以出色的效率處理各種大小的文件,從簡單的單頁信件到包含數千頁的龐大技術手冊。
🗂️ 預告片字典:PDF 的 GPS 系統。
想象一下,在沒有目錄系統的圖書館裡導航,會一片混亂!預告片字典是 PDF 的高階導航系統,它提供了 PDF 閱讀器用來理解和顯示文件的關鍵路線圖。
預告片字典位於 PDF 檔案的末尾,但它卻是開啟 PDF 時首先處理的內容之一。它包含至關重要的資訊,使軟體能夠定位和解釋文件的所有其他元件。
🔑 預告片字典中的重要條目。
| Key | Type | Purpose | Required? |
|---|---|---|---|
/Size |
Integer | Total entries in cross-reference table (usually objects + 1) | ✅ Yes |
/Root |
Indirect Reference | Points to the document catalog—the master control center | ✅ Yes |
/Info |
Indirect Reference | Links to document metadata (title, author, creation date) | ❌ Optional |
/ID |
Array of Strings | Unique document identifier for workflow management | ❌ Optional |
💡 提示:瞭解 PDF ID。
好的。 /ID 陣列包含兩個字串:第一個在文件建立時設定,並且永遠不會改變;第二個在文件每次修改時都會更新。這種雙識別符號系統支援複雜的文件管理工作流程。
📄 實際應用中的預告詞典示例:
|
1 2 3 4 5 6 |
<< /Size 421 /Root 377 0 R /Info 375 0 R /ID [<5sazn0fs3tamppia2izf569h281104ae> <6cig0wa61ti593bzuwy41905tr6s5c5a>] >> |
此示例顯示了一個包含 421 個物件的文件的預告,其中物件 377 作為文件目錄,物件 375 包含文件資訊。
📊 文件資訊字典:傳統的 PDF 後設資料。
文件資訊字典包含檔案的建立和修改日期,以及一些簡單的後設資料。這是在較舊的 PDF 版本中使用的傳統後設資料系統,不要與將在未來文章中討論的更全面的 XMP 後設資料混淆。
將此字典視為一個基本的圖書館目錄條目。雖然它對於顯示文件不是必需的,但它提供了有關文件的來源和歷史的基本資訊,使用簡單的文本字串。
📋 文件資訊欄位。
| Key | Data Type | Description | Example |
|---|---|---|---|
/Title |
Text String | Document title (separate from any visible title) | “Annual Report 2024” |
/Subject |
Text String | Document subject or description | “Financial Performance Analysis” |
/Keywords |
Text String | Searchable keywords | “finance, quarterly, revenue” |
/Author |
Text String | Document creator | “Jane Smith” |
/Creator |
Text String | Original application that created the document | “Microsoft Word” |
/Producer |
Text String | Application that converted to PDF | “Adobe Acrobat” |
/CreationDate |
Date String | When the document was originally created | D:20240625132712+08’00’ |
/ModDate |
Date String | Last modification timestamp | D:20240626094530+08’00’ |
⚠️ 重要區分
好的。 /Creator 和 /Producer fields 欄位用於不同的目的:Creator 標識原始建立應用程式(例如 Microsoft Word),而 Producer 標識生成最終 PDF 的軟體(例如 Adobe Acrobat 或 PDF 印表機驅動程式)。
📋 完整的文件資訊字典:
|
1 2 3 4 5 6 7 8 9 10 |
<< /ModDate (D:20060926213913+02'00') /CreationDate (D:20060926213913+02'00') /Title (Product Catalog - UK Edition) /Creator (QuarkXPress: pictwpstops filter 1.0) /Producer (Acrobat Distiller 6.0 for Macintosh) /Author (James Smith) /Subject (Quarterly Product Showcase) /Keywords (products, catalog, prices, specifications) >> |
🏛️ 文件目錄:主控制中心
如果 trailer 字典是 PDF 的 GPS 系統,那麼文件目錄就是它的中央控制中心。作為整個文件圖的根物件,目錄協調所有其他物件之間的關係,以及文件在檢視或列印時的行為。
PDF 文件中的每個物件都可以通過直接或間接引用從文件目錄訪問。這種集中式方法確保了高效的導航,並維護了文件的完整性。
🎛️ 重要的目錄條目
| Key | Type | Purpose | Required? |
|---|---|---|---|
/Type |
Name | Must be /Catalog |
✅ Yes |
/Pages |
Indirect Reference | Root of the page tree structure | ✅ Yes |
/PageLabels |
Number Tree | Enables complex page numbering (i, ii, iii, 1, 2, 3) | ❌ Optional |
/Names |
Dictionary | Name trees for referencing objects by name | ❌ Optional |
/Dests |
Dictionary | Named destinations for hyperlinks | ❌ Optional |
/ViewerPreferences |
Dictionary | Controls PDF viewer behavior | ❌ Optional |
/PageMode |
Name | Default viewing mode (thumbnails, bookmarks, etc.) | ❌ Optional |
/PageLayout |
Name | Page display layout (single, facing pages, etc.) | ❌ Optional |
/Outlines |
Indirect Reference | Document bookmarks/outline structure | ❌ Optional |
/Metadata |
Indirect Reference | XMP metadata stream | ❌ Optional |
🎨 觀看器偏好設定:控制使用者體驗
好的。 /ViewerPreferences dictionary 允許文件作者影響 PDF 閱覽器如何顯示其文件。這可以包括隱藏工具欄、將頁面調整為視窗大小,甚至控制列印設定。
📚 頁面模式選項說明
- /UseNone – 僅顯示文件,不顯示導航面板
- /UseOutlines – 顯示書籤面板
- /UseThumbs – 顯示頁面縮圖
- /FullScreen – 進入演示模式
- /UseOC – 顯示可選內容(圖層)面板
- /UseAttachments – 顯示附件面板
🌳 頁面和頁面樹:高效組織內容
PDF 最巧妙的設計之一在於其如何組織頁面。 與簡單的線性列表不同,PDF 採用樹狀結構,這在很大程度上提高了效能,尤其是在大型文件中。
想象一下,要在一個 1000 頁的檔案中找到特定的一頁,如果逐頁檢查,可能需要 1000 次操作!頁面樹結構將此減少到僅需幾次操作,這使得 PDF 閱覽器即使在處理大型文件時也能非常快速。
🏗️ 理解頁面字典結構
PDF 中的每一頁都由一個頁面字典表示,該字典彙集了渲染該特定頁面的所有元素:內容指令、資源(字型、影像)和佈局規範。
| Key | Type | Purpose | Inheritance |
|---|---|---|---|
/Type |
Name | Must be /Page |
❌ |
/Parent |
Indirect Reference | Parent node in page tree | ❌ |
/Resources |
Dictionary | Fonts, images, other resources | ✅ From parent if missing |
/Contents |
Stream/Array | Page content instructions | ❌ |
/MediaBox |
Rectangle | Physical page size | ✅ From parent if missing |
/CropBox |
Rectangle | Visible page area | ✅ Defaults to MediaBox |
/Rotate |
Integer | Page rotation (0, 90, 180, 270) | ✅ From parent if missing |
📐 理解 PDF 座標系統
PDF 使用一種基於矩形的複雜座標系統,矩形由四個數字表示對角頂點。理解此係統對於處理頁面佈局至關重要。
📏 矩形定義示例:
|
1 2 |
/MediaBox [0 0 595 842] # A4 size in points (8.27" × 11.69") /CropBox [50 50 545 792] # A4 with 50-point margins on all sides |
💡 PDF 測量單位
PDF 使用點作為其基本測量單位,其中 1 點 = 1/72 英寸。這使得計算變得簡單:72 點 = 1 英寸,144 點 = 2 英寸,以此類推。
🌲 頁面樹架構
頁面樹的精髓在於其平衡的結構。優秀的 PDF 應用程式會建立一種樹結構,無論文件大小,任何頁面都可以在幾步之內被找到。
🌳 頁面樹架構示例
/Type /Pages
/Count 7
/Count 3
/Count 2
/Type /Page
/Type /Page
圖 2: 7 頁文件的頁面樹結構,顯示出平衡的層次結構,以便高效訪問。
🎯 頁面樹效能優勢:
- 對數訪問時間 – 在 O(log n) 的操作內找到任何頁面。
- 高效的記憶體使用. – 僅載入大型文件所需的片段.
- 可擴充套件的架構. – 隨著文件的增長,效能保持一致.
- 繼承最佳化. – 頁面組之間共享的常用屬性.
📝 頁面樹節點結構.
| Key | Type | Purpose |
|---|---|---|
/Type |
Name | Must be /Pages |
/Kids |
Array | References to child nodes (pages or page trees) |
/Count |
Integer | Total number of leaf pages under this node |
/Parent |
Reference | Parent node (required unless root) |
🏗️ 頁面樹實現示例:
|
1 2 3 4 5 6 7 8 |
1 0 obj % Root node << /Type /Pages /Kids [2 0 R 3 0 R 4 0 R] /Count 7 >> endobj 2 0 obj % Intermediate node << /Type /Pages /Kids [5 0 R 6 0 R 7 0 R] /Parent 1 0 R /Count 3 >> endobj 5 0 obj % Actual page << /Type /Page /Parent 2 0 R /MediaBox [0 0 612 792] /Resources << >> >> endobj |
🔤 文本字串:處理多種編碼
PDF 的廣泛應用需要強大的文本處理能力。該格式支援多種編碼方案,以適應不同的語言和字元集,確保文件在任何地區都能正確顯示。
瞭解 PDF 文本編碼對於處理國際文件或開發 PDF 處理應用程式的人員至關重要。
📝 兩種主要的編碼方法
1. PDFDocEncoding
PDFDocEncoding 基於 ISO Latin-1,可以高效地處理大多數西歐語言。它是 PDF 文本字串的預設編碼,並與舊系統具有出色的相容性。
2. Unicode (UTF-16BE)
對於國際字元和複雜指令碼,PDF 使用 Unicode,採用 UTF-16BE 編碼。Unicode 字串以特殊的位元組序標記 (BOM) 開頭進行標識。
🔍 檢測 Unicode 字串
PDF 閱覽器通過檢查文本字串的前兩個位元組來確定編碼。
|
1 2 3 4 |
If bytes[0] == 254 AND bytes[1] == 255: encoding = "UTF-16BE" # Unicode byte-order marker U+FEFF else: encoding = "PDFDocEncoding" # Default PDF encoding |
⚠️ 編碼約束
由於 Unicode 檢測機制,PDFDocEncoding 字串不能以位元組序列 [254, 255] (þÿ) 開頭。但是,此限制很少影響實際文件。
📅 日期格式:精確的時間資訊
PDF 使用一種複雜的日期格式,不僅記錄事件發生的時間,還考慮了時區,這對於全球文件工作流程和法律要求至關重要。
📋 PDF 日期格式結構
|
1 |
(D:YYYYMMDDHHmmSSOHH'mm') |
| Component | Meaning | Format | Example |
|---|---|---|---|
| YYYY | Year | Four digits | 2025 |
| MM | Month | 01-12 | 06 (June) |
| DD | Day | 01-31 | 25 |
| HH | Hour | 00-23 | 13 (1 PM) |
| mm | Minute | 00-59 | 27 |
| SS | Second | 00-59 | 12 |
| O | UTC Offset | +, -, or Z | + (later than UTC) |
| HH’ | Offset Hours | 00-23 | 08 (8 hours) |
| mm’ | Offset Minutes | 00-59 | 00 (no minutes) |
🌍 時區示例
|
1 2 3 |
(D:20250625132712+08'00') # June 25, 2024, 1:27:12 PM, UTC+8 (Beijing) (D:20250625132712-05'00') # Same moment in Eastern Standard Time (D:20250625132712Z) # Same moment in UTC (Zulu time) |
🕐 靈活的日期精度
PDF 日期支援可變精度。您可以只指定年份, (D:2025)或者包含完整的精度,精確到秒和時區。缺失的元件將預設為合理的值(月份/日期為 01,時間元件為 00)。
🧩 總結:一個完整的示例
讓我們檢視一個完整的、手動建立的 PDF 示例,它演示了我們討論的所有概念。此三頁文件展示了所有 PDF 結構元素之間的相互作用。
📄 完整的 PDF 結構示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
%PDF-1.0 % Header 1 0 obj % Document catalog << /PageLayout /TwoColumnLeft /Pages 2 0 R /Type /Catalog >> endobj 2 0 obj % Root of page tree << /Kids [3 0 R 4 0 R] /Type /Pages /Count 3 >> endobj 3 0 obj % Page one << /Type /Page /Parent 2 0 R /MediaBox [0 0 612 792] % US Letter size /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [5 0 R] >> endobj 4 0 obj % Intermediate page tree node << /Parent 2 0 R /Kids [6 0 R 7 0 R] /Count 2 /Type /Pages >> endobj 5 0 obj % Content stream for page one << /Length 58 >> stream BT /F0 24 Tf 50 750 Td (Hello, PDF World!) Tj ET endstream endobj 6 0 obj % Page two << /Type /Page /Parent 4 0 R /MediaBox [0 0 612 792] /Rotate 90 % Landscape orientation /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [8 0 R] >> endobj 7 0 obj % Page three << /Type /Page /Parent 4 0 R /MediaBox [0 0 612 792] /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [9 0 R] >> endobj 8 0 obj % Content stream for page two << /Length 72 >> stream BT /F0 18 Tf 50 700 Td (This page is rotated 90 degrees) Tj ET endstream endobj 9 0 obj % Content stream for page three << /Length 45 >> stream BT /F0 24 Tf 50 750 Td (Final page) Tj ET endstream endobj 10 0 obj % Document information dictionary << /Title (PDF Structure Example) /Author (PDF Guide Author) /Producer (Manual Creation) /CreationDate (D:20240625132712+08'00') /ModDate (D:20240625133045+08'00') /Subject (Demonstrating PDF internal structure) /Keywords (PDF, structure, example, tutorial) >> endobj xref % Cross-reference table 0 11 0000000000 65535 f 0000000015 00000 n 0000000074 00000 n 0000000120 00000 n 0000000355 00000 n 0000000415 00000 n 0000000522 00000 n 0000000747 00000 n 0000000958 00000 n 0000001079 00000 n 0000001173 00000 n trailer % Trailer dictionary << /Size 11 /Root 1 0 R /Info 10 0 R /ID [<A1B2C3D4E5F6789012345678901234AB> <A1B2C3D4E5F6789012345678901234AB>] >> startxref 1456 %%EOF |
🗺️ 物件引用圖
/Size 11
/Root 1 0 R → Document Catalog
/Info 10 0 R → Document Info
/Type /Catalog
/Pages 2 0 R
/Title /Author
/CreationDate /ModDate
/Type /Pages
/Kids [3 0 R 4 0 R]
/Count 3
/Type /Page
/Contents [5 0 R]
/Kids [6 0 R 7 0 R]
/Count 2
/Contents [8 0 R]
/Rotate 90
/Contents [9 0 R]
圖 3: 物件引用圖,顯示了預告片字典如何連線到所有文件元件。
🔍 示例結構分析。
🎯 關鍵觀察:
- 高效導航。 – 任何頁面最多從根目錄訪問 2 步。
- 資源繼承。 – 字型資源可以從父節點繼承。
- 靈活佈局 – 第二頁展示了旋轉功能
- 豐富的後設資料 – 提供完整的文件資訊,用於工作流程管理
- 唯一標識 – ID 陣列用於文件跟蹤
🚀 高階主題和最佳實踐
🔧 最佳化策略
📈 效能最佳化技巧:
- 平衡樹 – 保持大型文件的對數級訪問時間
- 資源共享 – 將常用資源放置在父頁面樹節點中
- 高效編碼 – 對於西文字元,使用 PDFDocEncoding,僅在必要時使用 Unicode
- 適當的繼承 – 利用頁面樹繼承來實現常用屬性
- 最小化後設資料 – 僅包含必要的字典條目
🛡️ 錯誤預防和驗證
⚠️ 常見錯誤:
- 損壞的引用 – 確保所有間接引用都指向有效的物件
- 不一致的計數 – 頁面樹計數必須準確反映葉子頁面
- 缺少必需欄位 – 始終包含強制性字典條目
- 無效的日期格式 – 遵循精確的日期格式規範
- 編碼不匹配 – 正確識別 Unicode 與 PDFDocEncoding 字串
🔮 未來考慮
隨著 PDF 的不斷發展,理解這些基本結構變得越來越有價值。現代 PDF 功能,如數字簽名、輔助功能標籤和互動式表單,都建立在我們所探討的堅實基礎之上。
🌟 正在興起的 PDF 技術:
- PDF/A 標準 – 長期歸檔格式
- PDF/UA 可訪問性 – 通用可訪問性合規性
- 互動式表單 – 動態內容和使用者互動
- 數字簽名 加密文件完整性
- 三維內容 三維模型嵌入
🎯 結論:掌握PDF結構
理解PDF的內部結構,可以為高階文件處理、故障排除和最佳化開啟大門。從目錄字典提供的導航功能到頁面樹的有效組織,每個元件在建立我們每天依賴的強大、可移植文件中都具有特定的作用。
🏆 關鍵要點:
- 層次結構設計 PDF的基於樹的結構,可以實現高效的擴充套件。
- 智慧導航 – 交叉引用表和字典提供快速訪問。
- 靈活編碼 – 多種文本編碼支援全球文件交換。
- 豐富的後設資料 – 全面的資訊跟蹤支援複雜的流程。
- 繼承模型 – 資源共享減少冗餘和檔案大小。
“PDF的魅力不在於其複雜性,而在於這種複雜性是如何優雅地組織起來,以實現文件的通用可移植性這一簡單目標。”
這項對 PDF 結構全面深入的探討旨在揭示世界上最重要的文件格式之一的技術細節。 瞭解這些內部機制可以幫助開發人員、文件管理員和對技術感興趣的人員更有效地使用 PDF 技術。 建議使用 成熟的 PDF 開發庫 來大大簡化您的 PDF 處理任務。