掌握 PDF 文本和字体:开发人员指南
PDF 文档彻底改变了我们在不同平台和设备上共享和保存格式化文本的方式。但在每个 PDF 的精美表面下,隐藏着一个复杂的文本渲染系统,它将高级排版概念与精确的数学运算相结合。了解 PDF 如何处理文本和字体对于从事文档生成、文本提取或 PDF 处理的开发人员至关重要。
本全面的指南将带您深入了解 PDF 文本渲染的世界,探索从基本的字符间距到复杂的字体嵌入技术、字符编码系统以及文本提取的复杂挑战。无论您是经验丰富的开发人员还是刚刚开始使用 PDF 技术,您都将获得对这些无处不在的文档如何实际运作的宝贵见解。
PDF 文本渲染背后的哲学
当 Adobe 创建 PDF 格式时,他们面临着一项根本的设计挑战,这将影响数十亿文档的渲染方式。问题是:如何在灵活性和一致性之间取得平衡,以确保文档在各种不同的系统上看起来完全相同,从高分辨率打印机到移动设备。
他们可以选择两种极端的方法:
- 动态布局方法: 存储纯文本以及布局指令,类似于桌面出版软件的工作方式,从而在查看过程中实现实时文本流程和格式计算。
- 纯图形方法: 在创建过程中,将所有文本转换为矢量图形,以确保完美的视觉一致性,但完全丧失了所有语义信息和基于文本的功能。
另一方面,PDF 采用了一种我们可以称之为“黄金比例”的方法,这是一种复杂的折衷方案,它结合了两者的优点,同时避免了各自的缺点。这种混合系统保留了字体和字符的基本概念,同时在文档创建过程中预先计算了大部分布局决策。
PDF 方法的战略优势
完整的布局控制和可预测性
诸如段落换行、行间距、列宽和页面布局等大规模的格式化决策,由创建应用程序在 PDF 创建过程中处理。这意味着您的文档无论是在东京的智能手机上查看,还是在硅谷的 4K 监视器上显示,或者在纽约的激光打印机上打印,外观都将完全相同。布局的完整性在所有查看场景中都保持不变,从而消除了其他文档格式中常见的不可预测的自动换行问题。
可预测的小规模排版
诸如字符定位、单词间距和字体缩放等小规模的文本操作,通过一套完善且明确定义的运算符进行标准化。这允许对排版进行精细控制,同时在不同的 PDF 查看器和处理器中保持可预测的行为。该系统支持高级排版功能,如字间距、连字和上下文字符替换,同时确保获得一致的结果。
高效的存储和资源管理。
通过将字体视为可重用的字符形状库,即使是文本密集型的PDF文件也能保持相对较小的体积。与其单独存储每个字母的矢量轮廓,文档会引用共享的字体定义,这些定义可以在多个页面甚至多个文档中重用。这种方法在显著减小文件大小的同时,还支持高级的字体子集和嵌入策略。
语义保留,用于辅助功能。
与纯图形方法不同,PDF 保持了视觉符号与其底层字符代码之间的关键联系。这种保留使得重要的功能成为可能,例如文本搜索、复制和粘贴操作、屏幕阅读器辅助功能以及自动内容分析。该格式支持 Unicode 映射、替代文本描述以及标记结构信息,从而使文档能够被辅助技术访问。
完整的 PDF 文本状态系统。
PDF 的文本渲染系统通过一套复杂的参数集合来运行,这些参数协同工作,控制文本在页面上呈现的各个方面。可以将这些参数视为一个全面的控制面板,它不仅控制基本的显示效果,还控制高级的排版特性、定位计算和渲染优化。
完整的文本状态参数系统包括:
| Parameter | Operator | Description | Default Value |
|---|---|---|---|
| Character Spacing | Tc | Additional space between characters | 0 |
| Word Spacing | Tw | Additional space between words | 0 |
| Horizontal Scaling | Tz | Horizontal scaling percentage | 100 |
| Leading | TL | Line spacing for T* operator | 0 |
| Font and Size | Tf | Font selection and scaling | N/A |
| Text Rendering Mode | Tr | Fill, stroke, or path mode | 0 (Fill) |
| Text Rise | Ts | Vertical text displacement | 0 |
字符间距 (Tc Operator) – 精确的排版控制。
字符间距参数提供对文本字符串中每个字符之间额外空格的精细控制。此参数以文本空格单位为单位进行测量,通常为字体大小的 1/1000,从而实现极其精确的调整。
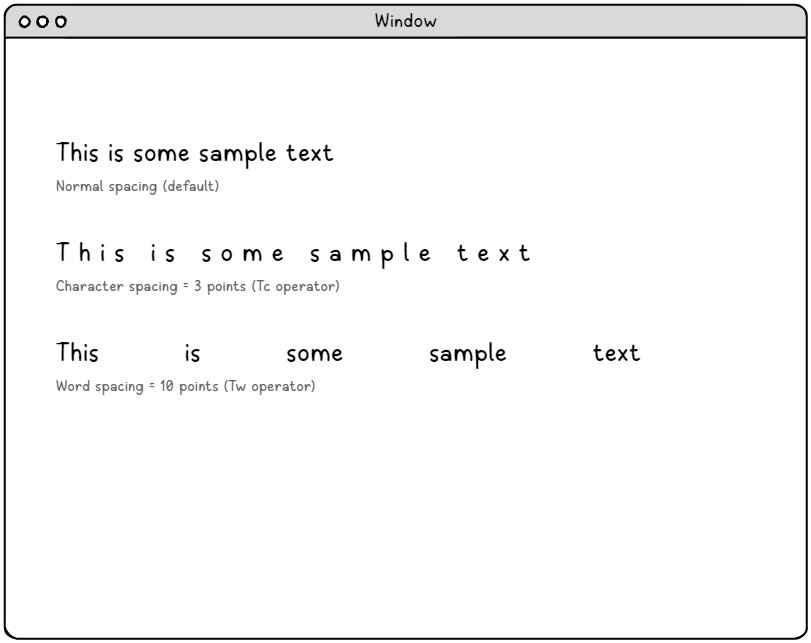
字符间距的应用包括:
- 排版增强: 在标题和正文中创建强调或提高可读性。
- 文本对齐支持: 调整对齐文本布局中的行长度。
- 品牌一致性: 匹配企业指南要求的特定排版风格。
- 可访问性: 提高阅读障碍或视力障碍用户的可读性。
|
1 2 3 4 5 6 7 8 9 10 11 |
BT /F0 24 Tf 1 0 0 1 50 700 Tm (Normal text spacing) Tj 0 -30 Td 3 Tc (Character spacing = 3 points) Tj 0 -30 Td -1 Tc (Tight character spacing = -1 point) Tj ET |
单词间距 (Tw 操作符) – 智能间距管理。
单词间距专门针对文本字符串中的空格字符 (ASCII 32),提供对单词间距的精确控制,而不会影响其他空白字符。 这种精确的控制对于文本对齐算法和创建专业文档布局非常有用。
Tw 操作符展示了 PDF 对排版的精细方法,因为它认识到不同类型的间距具有不同的目的。 虽然字符间距会影响所有字符,但单词间距仅影响实际的单词边界,从而使设计师能够精确控制文本的流程和可读性。
|
1 2 3 4 5 6 7 8 9 10 11 |
BT /F0 24 Tf 1 0 0 1 50 600 Tm (Normal word spacing) Tj 0 -30 Td 10 Tw (Extended word spacing improves readability) Tj 0 -30 Td -2 Tw (Compressed word spacing saves space) Tj ET |
水平缩放 (Tz 操作符) – 维度排版控制。
水平缩放允许您在不影响其高度的情况下,水平拉伸或压缩文本,以百分比表示,其中 100% 表示正常宽度。 此参数支持响应式排版调整和特殊的排版效果,而这些效果在传统的排版方法中是无法实现的。
水平缩放的应用:
- 空间受限的布局: 将文本适配到预定的列宽或设计元素中。
- 样式效果: 为标题和强调文本创建压缩或扩展版本。
- 字体模拟: 在字体不可用时,近似模拟压缩或扩展的字体变体。
- 响应式设计: 在保持可读性的同时,将文本适配到不同的页面尺寸。
然而,水平缩放应谨慎使用。 过度缩放会损害可读性,并产生不自然的文本,从而破坏阅读体验。 最佳实践建议将缩放限制在正文文本的 85-115% 范围内,而更大幅的缩放应保留用于显示目的。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
BT /F0 24 Tf 1 0 0 1 50 500 Tm 100 Tz (Normal horizontal scaling - 100%) Tj 0 -30 Td 80 Tz (Condensed text - 80% scaling) Tj 0 -30 Td 120 Tz (Extended text - 120% scaling) Tj ET |
行高 (TL Operator) – 垂直节奏和可读性
行高,发音为“ledding”,源于传统的排版,其中在行间插入薄的铅条。 在 PDF 中,行高决定了文本基线之间的垂直空间,并控制文本在 T* (移动到下一行) 操作符使用时的位置移动程度。
适当的行高对于建立文本的可读垂直节奏至关重要。 字体大小和行高之间的关系对可读性、理解速度和整体文档美观性有重要影响。 排版专家通常建议行高值在字体大小的 120% 到 145% 之间,以获得最佳的可读性。
行高注意事项:
- 字体大小关系: 通常,较大的字体需要成比例更大的行高。
- 行长影响: 较长的行需要增加行间距,以帮助读者更容易地回到下一行的开头。
- 字体特征: 具有较大字高或装饰性元素的字体可能需要调整行间距。
- 阅读环境: 不同类型的内容(正文、标题、说明)需要不同的行间距。
|
1 2 3 4 5 6 7 8 9 10 |
BT /F0 18 Tf 18 TL 1 0 0 1 50 400 Tm (This text uses 18pt leading) Tj T* (which matches the font size) Tj T* 24 TL (This text uses 24pt leading) Tj T* (providing more generous spacing) Tj T* ET |
文本垂直位置调整 (Ts Operator) – 垂直定位精度
文本垂直位置调整功能提供精细的垂直调整能力,允许您在不影响整体文本流程的情况下,将文本向上或向下移动。此参数对于创建需要精确垂直位置的专业排版元素至关重要。

文本垂直位置调整的应用包括:
- 数学符号: 排列上标、下标和数学符号。
- 科学内容: 化学公式、分子结构和科学注释。
- 编辑元素: 注释标记、商标符号和版权声明。
- 多语言排版: 调整不同书写系统的基线位置。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
BT /F0 36 Tf 1 0 0 1 140 290 Tm (H) Tj -8 Ts /F0 24 Tf (2) Tj 0 Ts /F0 36 Tf (O represents water with O) Tj 8 Ts /F0 24 Tf (2) Tj 0 Ts /F0 36 Tf ( as oxygen) Tj ET |
高级文本变换和矩阵运算。
PDF 最强大的功能之一是其能够通过双矩阵系统无缝地将文本变换与图形变换结合起来。这种能力可以在保持数学精度以确保在不同查看条件下文本位置操作的一致性的同时,实现复杂的布局效果。

变换系统通过两个主要矩阵运行:
当前变换矩阵 (CTM)。
CTM 用于处理影响所有图形元素的全局坐标变换,包括文本。它管理诸如旋转、缩放、平移和倾斜等在页面级别的操作。当您使用诸如 cm (concatenate matrix) 之类的运算符应用变换时,您正在修改 CTM。
文本矩阵 (TM)。
TM 专门处理文本定位和局部文本变换。它与 CTM 协同工作,以确保文本定位操作(如换行、字符前进和段落流程)即使在整个文本块被变换时也能正常工作。
矩阵变换序列。
当 PDF 渲染转换后的文本时,它遵循一个精确的数学序列。
- 字形间距计算: 字符的形状在字形空间坐标系中定义。
- 文本空间变换: 字符的位置使用字体大小和文本状态参数在文本空间中确定。
- 文本矩阵应用: 文本矩阵将坐标从文本空间转换为用户空间。
- 图形矩阵应用: 当前的变换矩阵用于最终的定位和方向调整。
- 设备空间转换: 最终坐标转换为特定于设备的单位,用于渲染。
这个多阶段过程确保文本变换在数学上精确,并且在不同的显示条件、输出设备和缩放因子下,视觉上保持一致。
|
1 2 3 4 5 6 7 8 9 10 11 |
% Set up rotation transformation 0.96 0.25 -0.25 0.96 0 0 cm BT /F0 48 Tf 48 TL % Set text matrix for positioning 1 0 0 1 270 240 Tm (Text and graphics) Tj T* (transforms combined) Tj T* (with proper newlines) Tj ET |
文本变换的实际应用。
- 旋转的标题和标签: 创建倾斜的文本,用于图表、图解和特殊布局。
- 艺术排版: 在保持可读性的同时,实现创意的文本效果。
- 多方向文档: 支持包含混合纵向和横向元素的文档。
- 坐标系统对齐: 将文本方向与现有的图形坐标系统匹配。
完整的字体选择和资源管理。
PDF 中的字体处理涉及一个复杂的资源管理系统,其功能远不止简单的字体选择。该系统必须高效地管理字体资源、字符编码方案、缩放操作以及兼容性要求,同时在各种观看环境中保持最佳的渲染性能。
字体资源字典系统。
PDF 文档维护一种分层字体字典结构,该结构将符号名称映射到实际的字体资源。这一间接层在文档架构中具有多个关键作用:
- 资源优化: 多个页面和内容流可以共享相同的字体资源,而无需重复。
- 替换控制: 可以在资源级别实现字体回退机制,而不会影响内容流。
- 编码管理: 字符编码方案可以与特定的字体实例相关联。
- 性能提升: 字体加载和解析可以通过智能缓存策略进行优化。
字体类型和技术特性。
Type 1 (PostScript) 字体。
Type 1 字体代表 Adobe 最初的可缩放字体技术,使用三次贝塞尔曲线以数学精度定义字符轮廓。由于其出色的可缩放特性和复杂的衬线系统,这些字体在专业出版应用中表现出色。
Type 1 字体的主要特性:
- 三次贝塞尔曲线轮廓: 数学上精确的曲线定义,可以平滑地缩放到任何尺寸。
- PostScript 衬线: 智能轮廓调整,可在小尺寸下实现最佳渲染效果。
- 编码灵活性: 支持自定义字符编码和专用字符集。
- 嵌入兼容性: 完整嵌入支持,并包含遵守许可机制。
TrueType 字体。
TrueType 字体使用二次贝塞尔曲线,并包含专门针对屏幕显示和低分辨率输出设备优化的高级提示信息。TrueType 字体最初由 Apple 开发,后被 Microsoft 采用,具有出色的跨平台兼容性。
TrueType 优势:
- 屏幕优化: 针对像素网格对齐进行了优化的高级提示系统。
- 平台兼容性: 广泛支持各种操作系统和应用程序。
- 紧凑存储: 使用二次曲线实现的有效轮廓表示。
- Unicode 支持: 原生支持大型字符集和国际文本。
OpenType 字体
OpenType 代表着数字排版的演进,它结合了 Type 1 和 TrueType 字体的最佳技术特性,同时增加了革命性的排版功能,从而改变了专业文本的呈现方式。
OpenType 的创新:
- 高级排版: 上下文连字、花体、替代字和风格集
- 庞大的字符集: 支持数千个字符和多种书写系统
- 布局智能: 复杂的上下文字符替换和定位规则。
- 跨平台一致性: 在不同的系统和应用程序中,具有相同的渲染行为。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
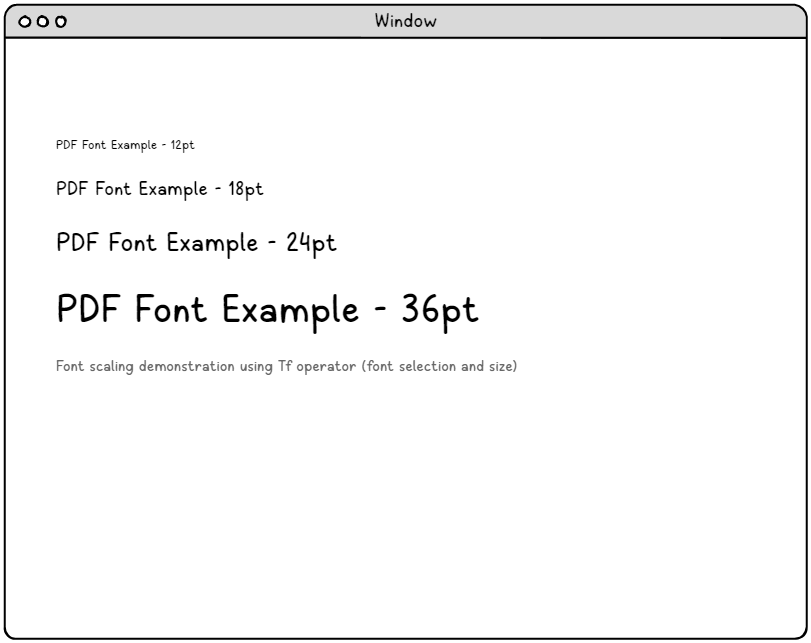
BT % Select font and set initial size /F0 12 Tf 1 0 0 1 50 750 Tm (12-point font example) Tj % Change to larger size, same font /F0 18 Tf 0 -25 Td (18-point font example) Tj % Even larger size /F0 24 Tf 0 -35 Td (24-point font example) Tj % Largest size /F0 36 Tf 0 -50 Td (36-point font example) Tj ET |
专业级的字间距和字形定位。
专业排版对单个字符之间的间距需要精确的控制。不同字母组合之间的视觉空间差异很大,这取决于字符的形状,因此,智能的字间距调整对于创建视觉上吸引人且高度可读的文本至关重要,以满足专业的出版标准。

TJ 操作符提供了先进的字形定位功能,超越了简单的字符和单词间距控制。与处理单一文本字符串不同,TJ 接受一个异构数组,从而可以实现具有数学精度的字符级别的定位控制。
理解 TJ 数组架构。
TJ 操作符的基于数组的方法通过接受混合内容,彻底改变了文本定位:
- 字符串元素: 包含要渲染的实际文本内容,使用标准字体编码。
- 数字元素: 指定水平调整量,以文本空格单位的千分之一为单位。
- 负值: 使后续字符更靠近,减小字符间距。
- 正值: 增加字符之间的间距,扩展文本布局。
这种精细的控制,可以实现专业级的排版效果,通过精确的字间距调整,这是使用更简单的文本操作无法实现的。该系统既可以进行美观方面的改进,也可以对字体的各项参数进行技术性校正。
|
1 2 3 4 5 6 7 8 9 |
BT /F0 48 Tf 1 0 0 1 100 400 Tm % Standard text rendering (WAVE Type) Tj 0 -60 Td % Kerned text with precise adjustments [(W) -120 (A) -80 (V) -100 (E) 50 (T) -20 (y) -10 (p) -5 (e)] TJ ET |
高级字间距调整策略
光学字间距
光学字间距根据字符组合的视觉外观来调整字符间距,而不是仅仅依赖于内置的字体参数。这种方法考虑了相邻字符的实际形状以及它们之间的视觉交互。
参数字间距
参数字间距使用字体的内置字间距表来调整特定字符对之间的间距。专业的字体通常包含大量的字间距表,其中包含数千个字符对的调整。
手动字间距
手动字间距允许对特定字符进行精确的调整,以满足特定的设计要求,或者纠正那些无法通过自动字间距系统充分解决的字符组合问题。
实用字间距调整应用
- 标志和品牌: 精确控制企业形象字体
- 标题字体: 优化大字体的视觉效果
- 精细字体: 实现出版级文本排版
- 多语言支持: 调整不同书写系统和字符组合的间距。
文本渲染模式和视觉效果。
PDF 提供了八种不同的文本渲染模式,用于控制文本的视觉呈现方式,从而提供广泛的灵活性,可以创建各种排版效果。这些模式决定了文本是填充、描边、用于裁剪路径,还是以不可见的方式呈现,以用于特殊目的。
完整的文本渲染模式参考。
| Mode | Name | Visual Effect | Common Uses |
|---|---|---|---|
| 0 | Fill | Solid color fill only | Standard body text |
| 1 | Stroke | Outline only, no fill | Decorative headers |
| 2 | Fill and Stroke | Both fill and outline | Emphasized text |
| 3 | Invisible | No visual rendering | Text positioning |
| 4 | Fill and Add to Path | Fill plus path construction | Text-based clipping |
| 5 | Stroke and Add to Path | Stroke plus path construction | Complex path operations |
| 6 | Fill, Stroke, and Add to Path | Complete text with path | Advanced graphics integration |
| 7 | Add to Path Only | Path construction, no rendering | Clipping path creation |
高级渲染模式应用。
不可见文本模式(模式 3)。
不可见文本在 PDF 文档中具有多种专门用途:
- 可搜索的图像 PDF。 在扫描文档上叠加不可见文本,以实现搜索功能。
- 文本定位: 在复杂布局中,无需视觉输出即可调整文本位置。
- 辅助功能增强: 提供替代文本描述,且不产生视觉干扰。
- 模板系统: 创建定位框架,用于动态内容生成。
路径构建模式(模式 4-7)。
这些高级模式可以实现文本系统和图形系统之间的复杂集成。
- 基于文本的裁剪: 使用文本形状裁剪其他图形元素。
- 复杂蒙版: 使用字符形状创建复杂的蒙版效果。
- 艺术效果: 将文本与渐变、图案和其他图形元素结合使用。
- 交互元素: 创建精确匹配文本边界的可点击区域。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
BT /F0 36 Tf 1 0 0 1 100 500 Tm % Standard filled text 0 Tr (Filled Text) Tj 0 -50 Td % Stroked text only 1 Tr 2 w (Stroked Text) Tj 0 -50 Td % Both filled and stroked 2 Tr (Filled and Stroked) Tj ET |
字体嵌入和子集优化。
字体嵌入是 PDF 创建中最关键的技术挑战之一,需要在文档可移植性、文件大小优化和法律合规性之间取得平衡。嵌入系统必须确保文档在不同系统上的显示一致,同时遵守字体许可限制并保持合理的文件大小。
字体嵌入策略。
完整字体嵌入。
完整字体嵌入将整个字体文件包含在 PDF 文档中,以确保完美的渲染兼容性,但会增加文件大小。这种方法可确保所有字符、字距信息和排版特性都可用。
优点:
- 完整兼容性: 无论目标系统如何,所有字体功能均保持可用。
- 渲染保真度: 完美再现原始的排版和间距。
- 功能保留: 高级 OpenType 功能仍然可用。
- 具有前瞻性: 即使字体可用性发生变化,文档仍然可读。
缺点:
- 文件大小影响: 文档大小显著增加,尤其是在使用多个字体时。
- 授权问题: 可能违反字体授权协议,这些协议限制了字体的嵌入。
- 处理开销: 加大了字体加载所需的内存和处理时间。
字体子集化:
字体子集化仅嵌入文档中实际使用的字符,从而显著减小文件大小,同时保持所包含字符集的渲染准确性。
子集优势:
- 最佳文件大小: 在保留排版的同时,对文档大小的影响最小。
- 许可合规性: 减少法律风险,因为只包含使用的字符。
- 性能提升: 加快字体加载速度并减少内存使用。
- 带宽效率: 较小的文档可以通过网络更快地传输。
字符编码和 Unicode 映射。
PDF 的字符编码系统必须弥合字体特定的字符代码与通用字符识别系统(如 Unicode)之间的差距。这个映射过程对于文本提取、搜索和辅助功能至关重要。
编码机制。
内置编码: 使用字体的内部字符映射,适用于标准的西方字符集,但对于国际内容有限。
标准 PDF 编码: 预定义的编码方案,如 WinAnsiEncoding 和 MacRomanEncoding,可在不同平台上提供一致的字符映射。
自定义编码: 特定于文档的字符映射,用于支持特殊字符或旧字体系统。
Unicode (CMap) 系统: 现代方法,使用字符映射 (CMaps),提供字符代码和 Unicode 值之间的直接映射。
ToUnicode 映射表:
ToUnicode CMaps 通过提供字体特定字符代码和 Unicode 值之间的桥梁,实现准确的文本提取和搜索。这些映射表对于可访问性和内容分析至关重要。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
% Example ToUnicode CMap structure 23 0 obj << /Length 317 >> stream /CIDInit /ProcSet findresource begin 12 dict begin begincmap /CIDSystemInfo << /Registry (Adobe) /Ordering (UCS) /Supplement 0 >> def /CMapName /Adobe-Identity-UCS def 1 begincodespacerange <0001> endcodespacerange 2 beginbfchar <0001> <0041> % Map glyph 1 to Unicode U+0041 (A) <0002> <0042> % Map glyph 2 to Unicode U+0042 (B) endbfchar endcmap CMapName currentdict /CMap defineresource pop end end endstream endobj |
PDF 文本提取的复杂挑战:
从 PDF 文档中提取文本是 PDF 处理中最具技术挑战性的方面之一,需要复杂的算法来从以图形为导向的格式重建逻辑阅读顺序。与传统文本格式不同,PDF 将文本存储为一系列定位的图形元素,这使得提取成为一个复杂的逆向工程过程。
基础提取挑战
非顺序文本定位
PDF 内容流根据视觉布局要求而非逻辑阅读顺序来定位文本元素。一个段落可能由数十个分散在内容流中的文本定位命令表示,这些命令与图形操作和其他非文本元素交织在一起。
这种定位方法会产生以下提取难题:
- 恢复阅读顺序: 确定非按顺序排列的文本元素的正确顺序。
- 柱检测: 识别多栏布局并确定正确的栏布局。
- 页面结构分析: 区分页眉、页脚、侧边栏和主要内容区域。
- 交叉引用解析: 连接由图形或格式分隔的关联文本元素。
字体和编码问题。
字符提取需要准确解释字体编码方案,而这些方案在不同的字体和文档创建系统中可能存在很大差异。
- 缺少字体信息: 文档可能引用提取系统上不可用的字体。
- 编码变体: 不同的字体可能使用不兼容的字符编码方案。
- 字体子集限制: 嵌入的字体子集可能缺乏完整的字符映射信息。
- Unicode 映射错误: 不正确或缺失的 ToUnicode 表格可能导致字符错误解释。
布局结构识别。
专业的文档采用复杂的布局结构,这给自动提取系统带来了挑战。
- 表格识别: 识别表格数据并保持行/列关系。
- 列表结构: 识别带有正确层级结构的无序列表和有序列表。
- 浮动元素: 处理中断正常文本流程的文本框、侧边栏和提示框。
- 多页连续性: 保持段落和章节在分页之间的上下文连贯性。
高级提取方法.
多轮分析方法.
复杂的提取系统采用多轮分析,每轮分析侧重于文档结构的不同方面:
- 字符级别分析: 提取单个字符的位置、字体和编码信息.
- 单词形成分析: 根据空格和字体特征将字符分组为单词.
- 行检测分析: 使用基线分析和垂直间距模式识别文本行。
- 段落组装阶段: 根据缩进和间距提示将行组合成段落。
- 结构分析阶段: 检测标题、列表、表格和其他文档元素。
- 内容组织阶段: 将元素组织成逻辑阅读顺序和层次结构。
机器学习增强。
现代提取系统越来越多地采用机器学习技术来提高准确性。
- 版面分类: 训练模型以识别常见的文档版面模式。
- 阅读顺序预测: 使用神经网络来确定最佳文本序列。
- 内容类型识别: 自动将文本元素分类为标题、正文、标题等。
- 表格结构检测: 高级算法,用于复杂表格布局的识别。
文本提取代码示例。
以下示例演示了从 PDF 定位命令重建文本所涉及的复杂性。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
% Complex text positioning that challenges extraction BT /F0 12 Tf 1 0 0 1 72 720 Tm (This text appears) Tj 150 0 Td (out of order) Tj -150 -15 Td (in the content stream) Tj 200 0 Td (but should be) Tj -200 -15 Td (reconstructed properly) Tj 100 0 Td (by extraction algorithms.) Tj ET % Graphics elements that interrupt text flow q 1 0 0 1 100 650 cm 0.5 g 0 0 200 50 re f Q % Continuation of text after graphics BT /F0 12 Tf 1 0 0 1 72 630 Tm (Text continues after graphics elements) Tj ET |
质量保证与验证。
专业的提取系统实现了多种验证机制。
- 语言分析: 字典检查和语法验证,用于识别提取错误。
- 格式一致性: 验证提取的结构是否符合常见的文档模式。
- 交叉引用验证: 确保内部文档引用保持完整。
- 字符编码验证: 检测和纠正字符编码错误。
性能优化和最佳实践。
高效的 PDF 文本处理需要仔细关注性能因素,这些因素会显著影响渲染速度、内存使用情况以及整体系统响应速度。 现代 PDF 应用程序必须处理从简单的单页文件到复杂的数千页出版物。
字体资源管理。
智能缓存策略
字体加载和解析是耗费资源的操作,可以通过策略性缓存获得显著的性能提升:
- 资源级别缓存: 在资源字典级别缓存解析后的字体对象,以避免重复解析。
- 字形渲染缓存: 存储渲染后的字符字形,以便在多个文本操作中重复使用。
- 度量计算缓存: 缓存字体度量计算结果,以避免重复计算。
- 跨文档缓存: 在适当情况下,在多个 PDF 文档中共享字体资源。
内存管理策略:
有效的内存管理可以防止文本密集型应用程序出现性能下降。
- 延迟加载: 仅在需要进行渲染或处理时才加载字体资源。
- 资源池: 维护常用的字体对象的池,以减少分配开销。
- 垃圾回收优化: 实现智能清理策略,用于未使用的字体资源。
- 内存映射: 使用内存映射文件来存储大型嵌入式字体,以减少 RAM 使用量。
文本流优化。
内容流组织。
高效地组织文本操作可以显著提高渲染性能:
- 批量文本操作: 将相关的文本操作组织在单个开始/结束块 (BT/ET) 中,以减少状态变化。
- 尽量减少字体切换。 组织内容以减少字体选择操作。
- 策略性定位: 在适当情况下,使用相对定位 (Td, TD) 而不是绝对定位 (Tm)。
- 状态合并: 将兼容的文本状态更改合并到单个操作中。
渲染管道优化。
现代 PDF 处理程序采用复杂的渲染流程。
- 多线程: 并行处理独立的文本元素。
- GPU 加速: 硬件加速的字形栅格化和合成。
- 渐进渲染: 在后台处理的同时显示文本内容。
- 视口裁剪: 跳过处理超出可见区域的文本元素。
辅助功能与通用设计。
创建可访问的 PDF 文档需要仔细关注文本结构、语义标记以及辅助技术兼容性。现代辅助功能标准要求 PDF 文档能够与屏幕阅读器、语音识别软件和其他辅助技术无缝协作。
标记的 PDF 结构。
标记的 PDF 提供语义结构信息,使辅助技术能够理解文档的组织方式。
- 逻辑结构树: 文档元素的层次结构组织。
- 基于角色的标记: 语义化识别标题、段落、列表和其他元素。
- 阅读顺序规范: 明确定义正确的阅读顺序。
- 替代描述: 图形元素和复杂结构对应的文本替代内容。
国际文本支持。
全局文档的可访问性需要全面的国际文本支持。
- Unicode 兼容性: 完全支持国际字符集和书写系统。
- 双向文本: 妥善处理混合左向右和右向左内容。
- 复杂文字: 支持对阿拉伯语、印度语和其他复杂书写系统中的上下文字符进行整形。
- 垂直文本支持: 传统中文、日语和蒙古文的垂直文本布局。
PDF排版方面的未来发展。
PDF 规范持续发展,融入了新的功能,以满足数字文档工作流程、Web 集成和高级排版应用中的新兴需求。
新一代排版功能
可变字体技术
可变字体代表着数字排版领域的革命性进步,允许单个字体文件包含多种设计变体:
- 粗细变化: 从细到粗的连续调整
- 宽度变化: 动态的压缩到扩展的宽度调整
- 光学尺寸: 自动优化以适应不同的显示尺寸。
- 自定义轴: 特定字体的变体,例如对比度、x高度或风格变体。
彩色字体集成。
高级彩色字体可以实现以前使用传统字体无法实现的丰富排版效果。
- 嵌入式图形: 包含完整彩色位图或矢量图形的字体。
- 渐变支持: 具有复杂色彩过渡和效果的字符。
- 多层字体: 具有单独图层的字体,用于阴影、轮廓和装饰元素。
- 动画排版: 基于时间的排版效果,适用于数字演示。
Web 和移动端集成。
随着 PDF 文档越来越多地出现在 Web 和移动端环境,新的功能重点在于响应式和自适应排版。
- 渐进式文本加载: 通过后台字体加载,实现更快的初始显示.
- 响应式排版: 针对不同的屏幕尺寸和方向,实现自适应文本重排.
- 触控优化交互: 增强了触摸屏设备的文本选择和交互功能.
- 高 DPI 支持: 针对高分辨率显示器,进行了优化渲染.
结论。
PDF文本系统的复杂性反映了数十年在数字排版和文档技术方面的演进。每个操作符、参数和编码方案在专业文档生产的整个生态系统中都具有特定的用途。字体嵌入策略、字符编码系统、变换矩阵和渲染模式协同工作,共同构建了一个强大的文本通信平台。
在您继续使用PDF文本和字体时,请记住,规范的复杂性具有重要的作用:确保文档的持久性、保持视觉保真度、支持国际内容以及实现可访问性。这些基本概念将在PDF技术不断发展并适应数字通信中的新挑战时为您提供帮助。