了解 PDF 的内部结构。
欢迎来到引人入胜的 PDF 内部世界! 您是否曾想过是什么让 PDF 文件正常工作? 在我们每天看到的常见文档背后,隐藏着一种复杂的架构,它彻底改变了数字文档的共享方式。 在这次全面的探索中,我们将揭示 PDF 结构的各个层面,从而了解这些无处不在的文件是如何工作的。
🔍 简介:超越表面。
可移植文档格式 (PDF) 已经成为全球文档交换的事实标准。 从简单的文本文档到复杂的交互式表单,PDF 可以在不同的平台和设备上保持一致的外观。 但是,这种通用兼容性之下隐藏着什么?
在这次深入研究中,我们将探索使 PDF 文件真正具有可移植性的逻辑结构。 我们将研究基本构建块: trailer dictionary (trailer 字典), document catalog (文档目录)以及 页面树——这三者共同协调,控制着每个 PDF 的功能。 我们还将揭示 PDF 中用于文本字符串和日期的专用数据格式的秘密。
🎯 本指南将教您:
- PDF 结构中的四个基本组件
- PDF 如何高效地组织和引用内容
- 字典、目录和页面树的作用
- PDF 在文本编码和日期格式方面的独特方法
- PDF对象结构的实际示例。
- 了解PDF内部的最佳实践。
📋 PDF解剖:高层概述。
在深入细节之前,让我们建立一个关于PDF结构的思维模型。将PDF视为一种复杂的档案系统,其中每条信息都有其特定的位置和用途。
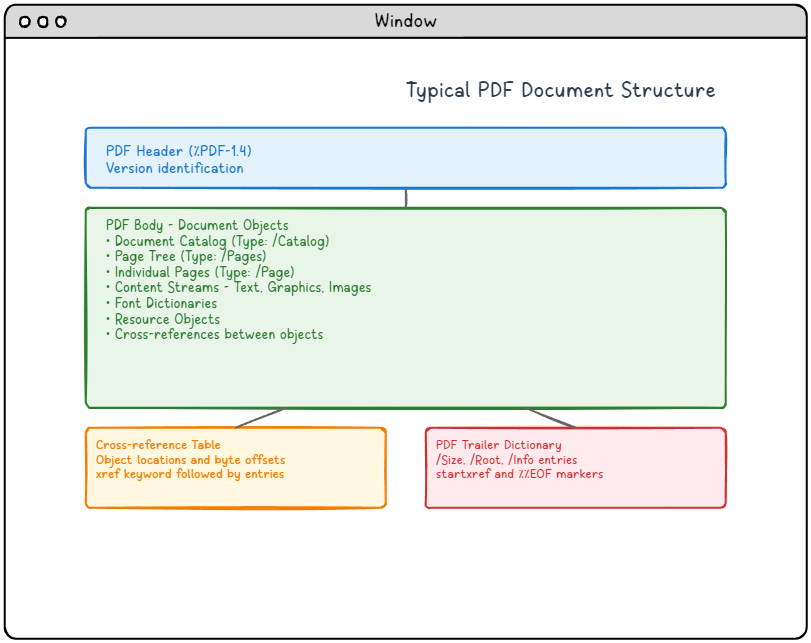
图1: 典型的PDF文档结构,显示了四个主要组件及其关系。
PDF结构图的详细描述:
此图说明了PDF文档的典型结构,其中包含四个主要组件,垂直排列:
-
- PDF 头部(顶部蓝色区域): 包含版本标识(%PDF-1.4),用于指定 PDF 格式版本。
- PDF 主体(中部绿色区域): 最大的区域,包含所有文档对象,包括文档目录、页面树、各个页面、包含文本/图形/图像的内容流、字体字典、资源对象以及对象之间的交叉引用。
- 交叉引用表(左下角橙色区域): 包含对象位置和字节偏移量,以 xref 关键字开头,后跟条目。
- PDF 尾部字典(右下角红色区域): 包含必要的导航信息,包括 /Size、/Root、/Info 条目,并以 startxref 和 %%EOF 标记结尾。
箭头显示了从标题到正文的逻辑流程,然后分支到交叉引用表和尾部字典,说明了 PDF 阅读器如何浏览文档结构。
一个 PDF 文档由四个主要结构元素协同工作组成。
🏗️ PDF 结构的核心支柱:
- 标题 (Header) – 标识 PDF 版本和功能。
- 正文 (Body) – 包含所有文档对象(文本、图像、字体等)。
- 交叉引用表 (Cross-reference Table) – 映射对象位置,以便快速访问。
- 预告片。 – 提供进入文档的入口。
这种结构使 PDF 能够以出色的效率处理各种大小的文档,从简单的单页信件到包含数千页的庞大技术手册。
🗂️ 预告片字典:PDF 的 GPS 系统。
想象一下,在没有目录系统的图书馆里导航,会一片混乱!预告片字典是 PDF 的高级导航系统,它提供了 PDF 阅读器用来理解和显示文档的关键路线图。
预告片字典位于 PDF 文件的末尾,但它却是打开 PDF 时首先处理的内容之一。它包含至关重要的信息,使软件能够定位和解释文档的所有其他组件。
🔑 预告片字典中的重要条目。
| Key | Type | Purpose | Required? |
|---|---|---|---|
/Size |
Integer | Total entries in cross-reference table (usually objects + 1) | ✅ Yes |
/Root |
Indirect Reference | Points to the document catalog—the master control center | ✅ Yes |
/Info |
Indirect Reference | Links to document metadata (title, author, creation date) | ❌ Optional |
/ID |
Array of Strings | Unique document identifier for workflow management | ❌ Optional |
💡 提示:了解 PDF ID。
好的。 /ID 数组包含两个字符串:第一个在文档创建时设置,并且永远不会改变;第二个在文档每次修改时都会更新。这种双标识符系统支持复杂的文档管理工作流程。
📄 实际应用中的预告词典示例:
|
1 2 3 4 5 6 |
<< /Size 421 /Root 377 0 R /Info 375 0 R /ID [<5sazn0fs3tamppia2izf569h281104ae> <6cig0wa61ti593bzuwy41905tr6s5c5a>] >> |
此示例显示了一个包含 421 个对象的文档的预告,其中对象 377 作为文档目录,对象 375 包含文档信息。
📊 文档信息字典:传统的 PDF 元数据。
文档信息字典包含文件的创建和修改日期,以及一些简单的元数据。这是在较旧的 PDF 版本中使用的传统元数据系统,不要与将在未来文章中讨论的更全面的 XMP 元数据混淆。
将此字典视为一个基本的图书馆目录条目。虽然它对于显示文档不是必需的,但它提供了有关文档的来源和历史的基本信息,使用简单的文本字符串。
📋 文档信息字段。
| Key | Data Type | Description | Example |
|---|---|---|---|
/Title |
Text String | Document title (separate from any visible title) | “Annual Report 2024” |
/Subject |
Text String | Document subject or description | “Financial Performance Analysis” |
/Keywords |
Text String | Searchable keywords | “finance, quarterly, revenue” |
/Author |
Text String | Document creator | “Jane Smith” |
/Creator |
Text String | Original application that created the document | “Microsoft Word” |
/Producer |
Text String | Application that converted to PDF | “Adobe Acrobat” |
/CreationDate |
Date String | When the document was originally created | D:20240625132712+08’00’ |
/ModDate |
Date String | Last modification timestamp | D:20240626094530+08’00’ |
⚠️ 重要区分
好的。 /Creator 和 /Producer fields 字段用于不同的目的:Creator 标识原始创建应用程序(例如 Microsoft Word),而 Producer 标识生成最终 PDF 的软件(例如 Adobe Acrobat 或 PDF 打印机驱动程序)。
📋 完整的文档信息字典:
|
1 2 3 4 5 6 7 8 9 10 |
<< /ModDate (D:20060926213913+02'00') /CreationDate (D:20060926213913+02'00') /Title (Product Catalog - UK Edition) /Creator (QuarkXPress: pictwpstops filter 1.0) /Producer (Acrobat Distiller 6.0 for Macintosh) /Author (James Smith) /Subject (Quarterly Product Showcase) /Keywords (products, catalog, prices, specifications) >> |
🏛️ 文档目录:主控制中心
如果 trailer 字典是 PDF 的 GPS 系统,那么文档目录就是它的中央控制中心。作为整个文档图的根对象,目录协调所有其他对象之间的关系,以及文档在查看或打印时的行为。
PDF 文档中的每个对象都可以通过直接或间接引用从文档目录访问。这种集中式方法确保了高效的导航,并维护了文档的完整性。
🎛️ 重要的目录条目
| Key | Type | Purpose | Required? |
|---|---|---|---|
/Type |
Name | Must be /Catalog |
✅ Yes |
/Pages |
Indirect Reference | Root of the page tree structure | ✅ Yes |
/PageLabels |
Number Tree | Enables complex page numbering (i, ii, iii, 1, 2, 3) | ❌ Optional |
/Names |
Dictionary | Name trees for referencing objects by name | ❌ Optional |
/Dests |
Dictionary | Named destinations for hyperlinks | ❌ Optional |
/ViewerPreferences |
Dictionary | Controls PDF viewer behavior | ❌ Optional |
/PageMode |
Name | Default viewing mode (thumbnails, bookmarks, etc.) | ❌ Optional |
/PageLayout |
Name | Page display layout (single, facing pages, etc.) | ❌ Optional |
/Outlines |
Indirect Reference | Document bookmarks/outline structure | ❌ Optional |
/Metadata |
Indirect Reference | XMP metadata stream | ❌ Optional |
🎨 观看器偏好设置:控制用户体验
好的。 /ViewerPreferences dictionary 允许文档作者影响 PDF 阅览器如何显示其文档。这可以包括隐藏工具栏、将页面调整为窗口大小,甚至控制打印设置。
📚 页面模式选项说明
- /UseNone – 仅显示文档,不显示导航面板
- /UseOutlines – 显示书签面板
- /UseThumbs – 显示页面缩略图
- /FullScreen – 进入演示模式
- /UseOC – 显示可选内容(图层)面板
- /UseAttachments – 显示附件面板
🌳 页面和页面树:高效组织内容
PDF 最巧妙的设计之一在于其如何组织页面。 与简单的线性列表不同,PDF 采用树状结构,这在很大程度上提高了性能,尤其是在大型文档中。
想象一下,要在一个 1000 页的文件中找到特定的一页,如果逐页检查,可能需要 1000 次操作!页面树结构将此减少到仅需几次操作,这使得 PDF 阅览器即使在处理大型文档时也能非常快速。
🏗️ 理解页面字典结构
PDF 中的每一页都由一个页面字典表示,该字典汇集了渲染该特定页面的所有元素:内容指令、资源(字体、图像)和布局规范。
| Key | Type | Purpose | Inheritance |
|---|---|---|---|
/Type |
Name | Must be /Page |
❌ |
/Parent |
Indirect Reference | Parent node in page tree | ❌ |
/Resources |
Dictionary | Fonts, images, other resources | ✅ From parent if missing |
/Contents |
Stream/Array | Page content instructions | ❌ |
/MediaBox |
Rectangle | Physical page size | ✅ From parent if missing |
/CropBox |
Rectangle | Visible page area | ✅ Defaults to MediaBox |
/Rotate |
Integer | Page rotation (0, 90, 180, 270) | ✅ From parent if missing |
📐 理解 PDF 坐标系统
PDF 使用一种基于矩形的复杂坐标系统,矩形由四个数字表示对角顶点。理解此系统对于处理页面布局至关重要。
📏 矩形定义示例:
|
1 2 |
/MediaBox [0 0 595 842] # A4 size in points (8.27" × 11.69") /CropBox [50 50 545 792] # A4 with 50-point margins on all sides |
💡 PDF 测量单位
PDF 使用点作为其基本测量单位,其中 1 点 = 1/72 英寸。这使得计算变得简单:72 点 = 1 英寸,144 点 = 2 英寸,以此类推。
🌲 页面树架构
页面树的精髓在于其平衡的结构。优秀的 PDF 应用程序会创建一种树结构,无论文档大小,任何页面都可以在几步之内被找到。
🌳 页面树架构示例
/Type /Pages
/Count 7
/Count 3
/Count 2
/Type /Page
/Type /Page
图 2: 7 页文档的页面树结构,显示出平衡的层次结构,以便高效访问。
🎯 页面树性能优势:
- 对数访问时间 – 在 O(log n) 的操作内找到任何页面。
- 高效的内存使用. – 仅加载大型文档所需的片段.
- 可扩展的架构. – 随着文档的增长,性能保持一致.
- 继承优化. – 页面组之间共享的常用属性.
📝 页面树节点结构.
| Key | Type | Purpose |
|---|---|---|
/Type |
Name | Must be /Pages |
/Kids |
Array | References to child nodes (pages or page trees) |
/Count |
Integer | Total number of leaf pages under this node |
/Parent |
Reference | Parent node (required unless root) |
🏗️ 页面树实现示例:
|
1 2 3 4 5 6 7 8 |
1 0 obj % Root node << /Type /Pages /Kids [2 0 R 3 0 R 4 0 R] /Count 7 >> endobj 2 0 obj % Intermediate node << /Type /Pages /Kids [5 0 R 6 0 R 7 0 R] /Parent 1 0 R /Count 3 >> endobj 5 0 obj % Actual page << /Type /Page /Parent 2 0 R /MediaBox [0 0 612 792] /Resources << >> >> endobj |
🔤 文本字符串:处理多种编码
PDF 的广泛应用需要强大的文本处理能力。该格式支持多种编码方案,以适应不同的语言和字符集,确保文档在任何地区都能正确显示。
了解 PDF 文本编码对于处理国际文档或开发 PDF 处理应用程序的人员至关重要。
📝 两种主要的编码方法
1. PDFDocEncoding
PDFDocEncoding 基于 ISO Latin-1,可以高效地处理大多数西欧语言。它是 PDF 文本字符串的默认编码,并与旧系统具有出色的兼容性。
2. Unicode (UTF-16BE)
对于国际字符和复杂脚本,PDF 使用 Unicode,采用 UTF-16BE 编码。Unicode 字符串以特殊的字节序标记 (BOM) 开头进行标识。
🔍 检测 Unicode 字符串
PDF 阅览器通过检查文本字符串的前两个字节来确定编码。
|
1 2 3 4 |
If bytes[0] == 254 AND bytes[1] == 255: encoding = "UTF-16BE" # Unicode byte-order marker U+FEFF else: encoding = "PDFDocEncoding" # Default PDF encoding |
⚠️ 编码约束
由于 Unicode 检测机制,PDFDocEncoding 字符串不能以字节序列 [254, 255] (þÿ) 开头。但是,此限制很少影响实际文档。
📅 日期格式:精确的时间信息
PDF 使用一种复杂的日期格式,不仅记录事件发生的时间,还考虑了时区,这对于全球文档工作流程和法律要求至关重要。
📋 PDF 日期格式结构
|
1 |
(D:YYYYMMDDHHmmSSOHH'mm') |
| Component | Meaning | Format | Example |
|---|---|---|---|
| YYYY | Year | Four digits | 2025 |
| MM | Month | 01-12 | 06 (June) |
| DD | Day | 01-31 | 25 |
| HH | Hour | 00-23 | 13 (1 PM) |
| mm | Minute | 00-59 | 27 |
| SS | Second | 00-59 | 12 |
| O | UTC Offset | +, -, or Z | + (later than UTC) |
| HH’ | Offset Hours | 00-23 | 08 (8 hours) |
| mm’ | Offset Minutes | 00-59 | 00 (no minutes) |
🌍 时区示例
|
1 2 3 |
(D:20250625132712+08'00') # June 25, 2024, 1:27:12 PM, UTC+8 (Beijing) (D:20250625132712-05'00') # Same moment in Eastern Standard Time (D:20250625132712Z) # Same moment in UTC (Zulu time) |
🕐 灵活的日期精度
PDF 日期支持可变精度。您可以只指定年份, (D:2025)或者包含完整的精度,精确到秒和时区。缺失的组件将默认为合理的值(月份/日期为 01,时间组件为 00)。
🧩 总结:一个完整的示例
让我们查看一个完整的、手动创建的 PDF 示例,它演示了我们讨论的所有概念。此三页文档展示了所有 PDF 结构元素之间的相互作用。
📄 完整的 PDF 结构示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
%PDF-1.0 % Header 1 0 obj % Document catalog << /PageLayout /TwoColumnLeft /Pages 2 0 R /Type /Catalog >> endobj 2 0 obj % Root of page tree << /Kids [3 0 R 4 0 R] /Type /Pages /Count 3 >> endobj 3 0 obj % Page one << /Type /Page /Parent 2 0 R /MediaBox [0 0 612 792] % US Letter size /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [5 0 R] >> endobj 4 0 obj % Intermediate page tree node << /Parent 2 0 R /Kids [6 0 R 7 0 R] /Count 2 /Type /Pages >> endobj 5 0 obj % Content stream for page one << /Length 58 >> stream BT /F0 24 Tf 50 750 Td (Hello, PDF World!) Tj ET endstream endobj 6 0 obj % Page two << /Type /Page /Parent 4 0 R /MediaBox [0 0 612 792] /Rotate 90 % Landscape orientation /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [8 0 R] >> endobj 7 0 obj % Page three << /Type /Page /Parent 4 0 R /MediaBox [0 0 612 792] /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [9 0 R] >> endobj 8 0 obj % Content stream for page two << /Length 72 >> stream BT /F0 18 Tf 50 700 Td (This page is rotated 90 degrees) Tj ET endstream endobj 9 0 obj % Content stream for page three << /Length 45 >> stream BT /F0 24 Tf 50 750 Td (Final page) Tj ET endstream endobj 10 0 obj % Document information dictionary << /Title (PDF Structure Example) /Author (PDF Guide Author) /Producer (Manual Creation) /CreationDate (D:20240625132712+08'00') /ModDate (D:20240625133045+08'00') /Subject (Demonstrating PDF internal structure) /Keywords (PDF, structure, example, tutorial) >> endobj xref % Cross-reference table 0 11 0000000000 65535 f 0000000015 00000 n 0000000074 00000 n 0000000120 00000 n 0000000355 00000 n 0000000415 00000 n 0000000522 00000 n 0000000747 00000 n 0000000958 00000 n 0000001079 00000 n 0000001173 00000 n trailer % Trailer dictionary << /Size 11 /Root 1 0 R /Info 10 0 R /ID [<A1B2C3D4E5F6789012345678901234AB> <A1B2C3D4E5F6789012345678901234AB>] >> startxref 1456 %%EOF |
🗺️ 对象引用图
/Size 11
/Root 1 0 R → Document Catalog
/Info 10 0 R → Document Info
/Type /Catalog
/Pages 2 0 R
/Title /Author
/CreationDate /ModDate
/Type /Pages
/Kids [3 0 R 4 0 R]
/Count 3
/Type /Page
/Contents [5 0 R]
/Kids [6 0 R 7 0 R]
/Count 2
/Contents [8 0 R]
/Rotate 90
/Contents [9 0 R]
图 3: 对象引用图,显示了预告片字典如何连接到所有文档组件。
🔍 示例结构分析。
🎯 关键观察:
- 高效导航。 – 任何页面最多从根目录访问 2 步。
- 资源继承。 – 字体资源可以从父节点继承。
- 灵活布局 – 第二页展示了旋转功能
- 丰富的元数据 – 提供完整的文档信息,用于工作流程管理
- 唯一标识 – ID 数组用于文档跟踪
🚀 高级主题和最佳实践
🔧 优化策略
📈 性能优化技巧:
- 平衡树 – 保持大型文档的对数级访问时间
- 资源共享 – 将常用资源放置在父页面树节点中
- 高效编码 – 对于西文字符,使用 PDFDocEncoding,仅在必要时使用 Unicode
- 适当的继承 – 利用页面树继承来实现常用属性
- 最小化元数据 – 仅包含必要的字典条目
🛡️ 错误预防和验证
⚠️ 常见错误:
- 损坏的引用 – 确保所有间接引用都指向有效的对象
- 不一致的计数 – 页面树计数必须准确反映叶子页面
- 缺少必需字段 – 始终包含强制性字典条目
- 无效的日期格式 – 遵循精确的日期格式规范
- 编码不匹配 – 正确识别 Unicode 与 PDFDocEncoding 字符串
🔮 未来考虑
随着 PDF 的不断发展,理解这些基本结构变得越来越有价值。现代 PDF 功能,如数字签名、辅助功能标签和交互式表单,都建立在我们所探讨的坚实基础之上。
🌟 正在兴起的 PDF 技术:
- PDF/A 标准 – 长期归档格式
- PDF/UA 可访问性 – 通用可访问性合规性
- 交互式表单 – 动态内容和用户交互
- 数字签名 加密文档完整性
- 三维内容 三维模型嵌入
🎯 结论:掌握PDF结构
理解PDF的内部结构,可以为高级文档处理、故障排除和优化打开大门。从目录字典提供的导航功能到页面树的有效组织,每个组件在创建我们每天依赖的强大、可移植文档中都具有特定的作用。
🏆 关键要点:
- 层次结构设计 PDF的基于树的结构,可以实现高效的扩展。
- 智能导航 – 交叉引用表和字典提供快速访问。
- 灵活编码 – 多种文本编码支持全球文档交换。
- 丰富的元数据 – 全面的信息跟踪支持复杂的流程。
- 继承模型 – 资源共享减少冗余和文件大小。
“PDF的魅力不在于其复杂性,而在于这种复杂性是如何优雅地组织起来,以实现文档的通用可移植性这一简单目标。”
这项对 PDF 结构全面深入的探讨旨在揭示世界上最重要的文档格式之一的技术细节。 了解这些内部机制可以帮助开发人员、文档管理员和对技术感兴趣的人员更有效地使用 PDF 技术。 建议使用 成熟的 PDF 开发库 来大大简化您的 PDF 处理任务。