PDF'nin İç Yapısını Anlamak
PDF dahili dosyalarının büyüleyici dünyasına hoş geldiniz! Bir PDF dosyasının çalışmasını neyin sağladığını hiç merak ettiniz mi? Her gün gördüğümüz tanıdık belgelerin ötesinde, dijital belge paylaşımında devrim yaratan gelişmiş bir mimari yatıyor. Bu kapsamlı incelemede, PDF yapısının katmanlarını soyarak, her yerde bulunan bu dosyaların çalışmasını sağlayan karmaşık mekanizmaları ortaya çıkaracağız.
🔍 Giriş: Yüzeyin Ötesinde
Taşınabilir Belge Formatı (PDF), dünya çapında belge alışverişinde fiili standart haline geldi. Basit metin belgelerinden karmaşık etkileşimli formlara kadar PDF'ler, farklı platformlarda ve cihazlarda tutarlı görünümü korur. Peki bu evrensel uyumluluğun altında ne yatıyor?
Bu ayrıntılı incelemede, PDF dosyalarını gerçekten taşınabilir kılan mantıksal yapıyı keşfedeceğiz. Temel yapı taşlarını inceleyeceğiz: fragman sözlüğü, belge kataloğuve sayfa ağacı—her PDF'nin işlevselliğini düzenleyen üçlü yönetim. Ayrıca PDF'nin metin dizeleri ve tarihler için özelleştirilmiş veri formatlarının sırlarını da açığa çıkaracağız.
🎯 Bu Kılavuzda Neler Öğreneceksiniz:
- PDF yapısının dört temel bileşeni
- PDF, içeriği nasıl verimli bir şekilde organize eder ve referans verir?
- Sözlüklerin, katalogların ve sayfa ağaçlarının rolü
- PDF'nin metin kodlama ve tarih biçimlendirmeye yönelik benzersiz yaklaşımları
- PDF nesne yapılarının gerçek dünyadaki örnekleri
- PDF'nin içindekileri anlamak için en iyi uygulamalar
📋 PDF'nin Anatomisi: Üst Düzey Genel Bakış
Ayrıntılara dalmadan önce, PDF yapısının zihinsel bir modelini oluşturalım. PDF'yi, her bilgi parçasının belirli bir yeri ve amacı olan gelişmiş bir dosyalama sistemi olarak düşünün.
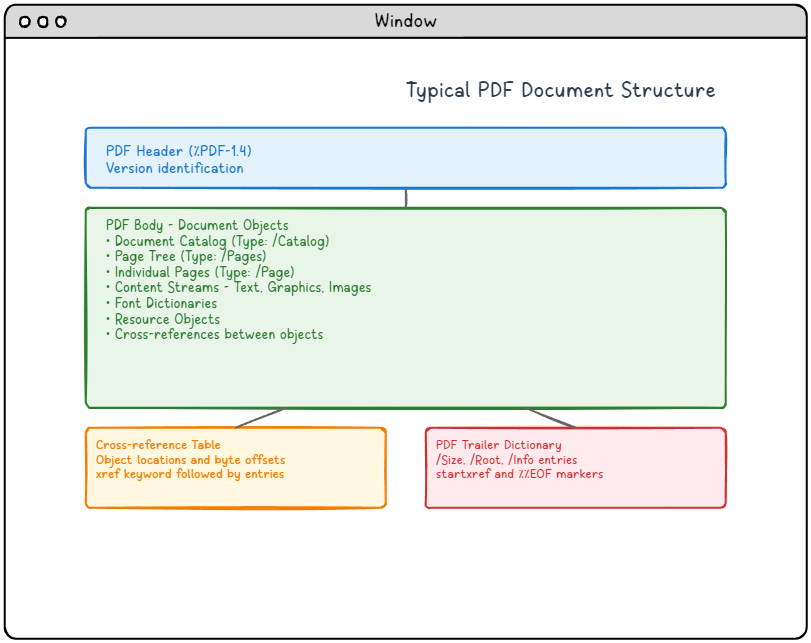
Şekil 1: Dört ana bileşeni ve bunların ilişkilerini gösteren Tipik PDF Belge Yapısı
PDF Yapı Diyagramının Uzun Açıklaması:
Bu şema, dikey olarak düzenlenmiş dört ana bileşenden oluşan bir PDF belgesinin tipik yapısını göstermektedir:
-
- PDF Başlığı (Üstteki Mavi bölüm): PDF formatı sürümünü belirten sürüm kimliğini (%PDF-1.4) içerir
- PDF Gövdesi (Ortadaki yeşil bölüm): Belge Kataloğu, Sayfa Ağacı, Bireysel Sayfalar, metin/grafik/görüntü içeren İçerik Akışları, Yazı Tipi Sözlükleri, Kaynak Nesneleri ve nesneler arasındaki Çapraz referanslar dahil tüm belge nesnelerini içeren en büyük bölüm
- Çapraz Referans Tablosu (Sol altta turuncu bölüm): xref anahtar sözcüğü ve ardından girişlerle işaretlenmiş nesne konumlarını ve bayt uzaklıklarını içerir
- PDF Fragman Sözlüğü (Sağ altta kırmızı bölüm): /Size, /Root, /Info girişleri dahil temel gezinme bilgilerini içerir ve startxref ve %%EOF işaretçileriyle biter
Oklar, başlıktan gövdeye mantıksal akışı, ardından hem çapraz referans tablosuna hem de fragman sözlüğüne dallanarak PDF okuyucularının belge yapısında nasıl gezindiğini gösterir.
Bir PDF belgesi uyum içinde çalışan dört ana yapısal öğeden oluşur:
🏗️ PDF Yapısının Dört Sütunu:
- Başlık – PDF sürümünü ve yeteneklerini tanımlar
- Gövde – Tüm belge nesnelerini (metin, resimler, yazı tipleri vb.) içerir.
- Çapraz Referans Tablosu – Hızlı erişim için nesne konumlarını haritalar
- Fragman – Belgede gezinmek için giriş noktası sağlar
Bu yapı, basit tek sayfalık mektuplardan binlerce sayfalık devasa teknik kılavuzlara kadar her boyuttaki belgenin işlenmesinde PDF'nin dikkate değer verimliliğini sağlar.
🗂️ Fragman Sözlüğü: PDF'nizin GPS Sistemi
Bir kütüphanede katalog sistemi olmadan gezinmeye çalıştığınızı hayal edin; kaos ortaya çıkar! Fragman sözlüğü, PDF'nin gelişmiş gezinme sistemi olarak görev yapar ve PDF okuyucularının belgenizi anlamak ve görüntülemek için kullandığı temel yol haritasını sağlar.
PDF dosyasının en sonunda yer alan fragman sözlüğü, paradoksal olarak, bir PDF açılırken işlenen ilk şeylerden biridir. Yazılımın belgenin diğer tüm bileşenlerini bulmasını ve yorumlamasını sağlayan önemli bilgileri içerir.
🔑 Fragman Sözlüğündeki Temel Girişler
| Key | Type | Purpose | Required? |
|---|---|---|---|
/Size |
Integer | Total entries in cross-reference table (usually objects + 1) | ✅ Yes |
/Root |
Indirect Reference | Points to the document catalog—the master control center | ✅ Yes |
/Info |
Indirect Reference | Links to document metadata (title, author, creation date) | ❌ Optional |
/ID |
Array of Strings | Unique document identifier for workflow management | ❌ Optional |
💡 Profesyonel İpucu: PDF Kimliklerini Anlamak
/ID dizisi iki dize içerir: birincisi belge oluşturulduğunda ayarlanır ve hiçbir zaman değişmez, ikincisi ise belge her değiştirildiğinde güncellenir. Bu çift tanımlayıcı sistem, gelişmiş belge yönetimi iş akışlarına olanak tanır.
📄 Gerçek Dünya Fragman Sözlüğü Örneği:
Urvanov Sözdizimi Vurgulayıcı v2.9.1|
1 2 3 4 5 6 |
<< /Size 421 /Root 377 0 R /Info 375 0 R /ID [<5sazn0fs3tamppia2izf569h281104ae> <6cig0wa61ti593bzuwy41905tr6s5c5a>] >> |
Bu örnek, 421 nesne içeren bir belgenin fragmanını gösterir; burada nesne 377, belge kataloğu olarak hizmet eder ve nesne 375, belge bilgilerini içerir.
📊 Belge Bilgileri Sözlüğü: Geleneksel PDF Meta Verileri
Belge bilgileri sözlüğü, bazı basit meta verilerle birlikte dosyanın oluşturulma ve değiştirilme tarihlerini içerir. Bu, eski PDF sürümlerinde kullanılan geleneksel meta veri sistemidir; gelecekteki makalelerde tartışılacak olan daha kapsamlı XMP meta verileriyle karıştırılmamalıdır.
Bu sözlüğü temel bir kütüphane kartı katalog girişi olarak düşünün. Belgeyi görüntülemek için gerekli olmasa da, basit metin dizilerini kullanarak belgenin kökeni ve geçmişi hakkında temel bilgiler sağlar.
📋 Belge Bilgi Alanları
| Key | Data Type | Description | Example |
|---|---|---|---|
/Title |
Text String | Document title (separate from any visible title) | “Annual Report 2024” |
/Subject |
Text String | Document subject or description | “Financial Performance Analysis” |
/Keywords |
Text String | Searchable keywords | “finance, quarterly, revenue” |
/Author |
Text String | Document creator | “Jane Smith” |
/Creator |
Text String | Original application that created the document | “Microsoft Word” |
/Producer |
Text String | Application that converted to PDF | “Adobe Acrobat” |
/CreationDate |
Date String | When the document was originally created | D:20240625132712+08’00’ |
/ModDate |
Date String | Last modification timestamp | D:20240626094530+08’00’ |
⚠️ Önemli Ayrım
/Creator ve /Producer alanları farklı amaçlara hizmet eder: Oluşturucu, orijinal yazma uygulamasını (Microsoft Word gibi) tanımlarken Yapımcı, son PDF'yi oluşturan yazılımı (Adobe Acrobat veya PDF yazıcı sürücüsü gibi) tanımlar.
📋 Tam Belge Bilgileri Sözlüğü:
Urvanov Sözdizimi Vurgulayıcı v2.9.1|
1 2 3 4 5 6 7 8 9 10 |
<< /ModDate (D:20060926213913+02'00') /CreationDate (D:20060926213913+02'00') /Title (Product Catalog - UK Edition) /Creator (QuarkXPress: pictwpstops filter 1.0) /Producer (Acrobat Distiller 6.0 for Macintosh) /Author (James Smith) /Subject (Quarterly Product Showcase) /Keywords (products, catalog, prices, specifications) >> |
🏛️ Belge Kataloğu: Ana Kontrol Merkezi
Fragman sözlüğü PDF'nin GPS sistemiyse, belge kataloğu da onun merkezi komuta merkezidir. Tüm belge grafiğinin kök nesnesi olan katalog, diğer tüm nesnelerin birbirleriyle nasıl ilişki kurduğunu ve belgenin görüntülendiğinde veya yazdırıldığında nasıl davranacağını düzenler.
Bir PDF belgesindeki her nesneye, belge kataloğundan başlayarak doğrudan veya dolaylı referanslarla ulaşılabilir. Bu merkezi yaklaşım, verimli gezinmeyi sağlar ve belge bütünlüğünü korur.
🎛️ Temel Katalog Girişleri
| Key | Type | Purpose | Required? |
|---|---|---|---|
/Type |
Name | Must be /Catalog |
✅ Yes |
/Pages |
Indirect Reference | Root of the page tree structure | ✅ Yes |
/PageLabels |
Number Tree | Enables complex page numbering (i, ii, iii, 1, 2, 3) | ❌ Optional |
/Names |
Dictionary | Name trees for referencing objects by name | ❌ Optional |
/Dests |
Dictionary | Named destinations for hyperlinks | ❌ Optional |
/ViewerPreferences |
Dictionary | Controls PDF viewer behavior | ❌ Optional |
/PageMode |
Name | Default viewing mode (thumbnails, bookmarks, etc.) | ❌ Optional |
/PageLayout |
Name | Page display layout (single, facing pages, etc.) | ❌ Optional |
/Outlines |
Indirect Reference | Document bookmarks/outline structure | ❌ Optional |
/Metadata |
Indirect Reference | XMP metadata stream | ❌ Optional |
🎨 İzleyici Tercihleri: Kullanıcı Deneyimini Kontrol Etme
/ViewerPreferences sözlük, belge yazarlarının PDF görüntüleyicilerinin belgelerini nasıl görüntülediklerini etkilemesine olanak tanır. Bu, araç çubuklarının gizlenmesini, sayfaları pencerelere sığdırılmasını ve hatta yazdırma ayarlarının kontrol edilmesini içerebilir.
📚 Sayfa Modu Seçenekleri Açıklandı
- /KullanımHiçbiri – Yalnızca belge, gezinme paneli yok
- /UseOutlines – Yer imleri panelini göster
- /UseThumbs – Sayfa küçük resimlerini görüntüle
- /Tam Ekran – Sunum moduna girin
- /UseOC – İsteğe bağlı içerik (katmanlar) panelini göster
- /UseEkler – Ekler panelini görüntüle
🌳 Sayfalar ve Sayfa Ağaçları: İçeriği Verimli Bir Şekilde Düzenleme
PDF'nin en ustaca tasarım kararlarından biri, sayfaların nasıl organize edildiğiyle ilgilidir. PDF, basit bir doğrusal liste kullanmak yerine, özellikle büyük belgelerde performansı önemli ölçüde artıran bir ağaç yapısı kullanır.
1000 sayfalık bir belgede, her sayfayı sırayla kontrol ederek belirli bir sayfayı bulmaya çalıştığınızı hayal edin; bu, 1000'e kadar işlem gerektirebilir! Sayfa ağacı yapısı bunu yalnızca birkaç işleme indirir ve PDF görüntüleyicilerin çok büyük belgelerde bile oldukça hızlı olmasını sağlar.
🏗️ Sayfa Sözlüğü Yapısını Anlamak
PDF'deki her sayfa, söz konusu sayfayı oluşturmak için gereken tüm öğeleri bir araya getiren bir sayfa sözlüğüyle temsil edilir: içerik talimatları, kaynaklar (yazı tipleri, resimler) ve düzen özellikleri.
| Key | Type | Purpose | Inheritance |
|---|---|---|---|
/Type |
Name | Must be /Page |
❌ |
/Parent |
Indirect Reference | Parent node in page tree | ❌ |
/Resources |
Dictionary | Fonts, images, other resources | ✅ From parent if missing |
/Contents |
Stream/Array | Page content instructions | ❌ |
/MediaBox |
Rectangle | Physical page size | ✅ From parent if missing |
/CropBox |
Rectangle | Visible page area | ✅ Defaults to MediaBox |
/Rotate |
Integer | Page rotation (0, 90, 180, 270) | ✅ From parent if missing |
📐 PDF Koordinat Sistemlerini Anlamak
PDF, çapraz köşeleri temsil eden dört sayıyla tanımlanan dikdörtgenlere dayalı karmaşık bir koordinat sistemi kullanır. Bu sistemi anlamak sayfa düzenleriyle çalışmak için çok önemlidir.
📏 Dikdörtgen Tanımı Örnekleri:
Urvanov Sözdizimi Vurgulayıcı v2.9.1|
1 2 |
/MediaBox [0 0 595 842] # A4 size in points (8.27" × 11.69") /CropBox [50 50 545 792] # A4 with 50-point margins on all sides |
💡 PDF Ölçü Birimleri
PDF, temel ölçü birimi olarak noktaları kullanır; burada 1 nokta = 1/72 inçtir. Bu, hesaplamaları basitleştirir: 72 punto = 1 inç, 144 punto = 2 inç, vb.
🌲 Sayfa Ağacı Mimarisi
Sayfa ağacının parlaklığı dengeli yapısında yatıyor. İyi PDF uygulamaları, belge boyutundan bağımsız olarak herhangi bir sayfanın yalnızca birkaç adımda bulunabileceği ağaçlar oluşturur.
🌳 Sayfa Ağacı Mimarisi Örneği
/Tür /Sayfalar
/Say 7
/Say 3
/Sayma 2
/Tür /Sayfa
/Tür /Sayfa
Şekil 2: Verimli erişim için dengeli hiyerarşiyi gösteren 7 sayfalık bir belge için sayfa ağacı yapısı
🎯 Sayfa Ağacı Performansının Avantajları:
- Logaritmik Erişim Süresi – O(log n) işlemlerinde herhangi bir sayfayı bulun
- Verimli Bellek Kullanımı – Büyük belgelerin yalnızca gerekli kısımlarını yükleyin
- Ölçeklenebilir Mimari – Belgeler büyüdükçe performans tutarlı kalır
- Kalıtım Optimizasyonu – Sayfa gruplarında paylaşılan ortak özellikler
📝 Sayfa Ağacı Düğüm Yapısı
| Key | Type | Purpose |
|---|---|---|
/Type |
Name | Must be /Pages |
/Kids |
Array | References to child nodes (pages or page trees) |
/Count |
Integer | Total number of leaf pages under this node |
/Parent |
Reference | Parent node (required unless root) |
🏗️ Sayfa Ağacı Uygulama Örneği:
Urvanov Sözdizimi Vurgulayıcı v2.9.1|
1 2 3 4 5 6 7 8 |
1 0 obj % Root node << /Type /Pages /Kids [2 0 R 3 0 R 4 0 R] /Count 7 >> endobj 2 0 obj % Intermediate node << /Type /Pages /Kids [5 0 R 6 0 R 7 0 R] /Parent 1 0 R /Count 3 >> endobj 5 0 obj % Actual page << /Type /Page /Parent 2 0 R /MediaBox [0 0 612 792] /Resources << >> >> endobj |
🔤 Metin Dizeleri: Birden Fazla Kodlamayı Yönetme
PDF'nin küresel erişimi, güçlü metin işleme yetenekleri gerektirir. Format, farklı dillere ve karakter kümelerine uyum sağlamak için birden fazla kodlama şemasını destekleyerek, izleyicinin yerel ayarına bakılmaksızın belgelerin doğru şekilde görüntülenmesini sağlar.
PDF metin kodlamasını anlamak, uluslararası belgelerle çalışan veya PDF işleme uygulamaları geliştiren herkes için çok önemlidir.
📝 İki Birincil Kodlama Yöntemi
1. PDFDoc Kodlaması
ISO Latin-1'i temel alan PDFDocEncoding, çoğu Batı Avrupa dilini verimli bir şekilde işler. PDF metin dizeleri için varsayılan kodlamadır ve eski sistemlerle mükemmel uyumluluk sağlar.
2. Unicode (UTF-16BE)
Uluslararası karakterler ve karmaşık komut dosyaları için PDF, UTF-16BE kodlamalı Unicode'u kullanır. Unicode dizeleri başlangıçta özel bir bayt sırası işaretçisi (BOM) ile tanımlanır.
🔍 Unicode Dizeleri Algılama
PDF görüntüleyicileri kodlamayı bir metin dizesinin ilk iki baytını inceleyerek belirler:
|
1 2 3 4 |
If bytes[0] == 254 AND bytes[1] == 255: encoding = "UTF-16BE" # Unicode byte-order marker U+FEFF else: encoding = "PDFDocEncoding" # Default PDF encoding |
⚠️ Kodlama Kısıtlaması
Unicode algılama mekanizması nedeniyle, PDFDocEncoding dizeleri bayt dizisi [254, 255] (þÿ) ile başlayamaz. Ancak bu sınırlama gerçek dünyadaki belgeleri nadiren etkiler.
📅 Tarih Formatları: Kesin Zamansal Bilgiler
PDF, yalnızca bir şeyin ne zaman gerçekleştiğini değil, aynı zamanda küresel belge iş akışları ve yasal gereksinimler için hayati önem taşıyan saat dilimlerini de hesaba katan gelişmiş bir tarih formatı kullanır.
📋 PDF Tarih Formatı Yapısı
|
1 |
(D:YYYYMMDDHHmmSSOHH'mm') |
| Component | Meaning | Format | Example |
|---|---|---|---|
| YYYY | Year | Four digits | 2025 |
| MM | Month | 01-12 | 06 (June) |
| DD | Day | 01-31 | 25 |
| HH | Hour | 00-23 | 13 (1 PM) |
| mm | Minute | 00-59 | 27 |
| SS | Second | 00-59 | 12 |
| O | UTC Offset | +, -, or Z | + (later than UTC) |
| HH’ | Offset Hours | 00-23 | 08 (8 hours) |
| mm’ | Offset Minutes | 00-59 | 00 (no minutes) |
🌍 Zaman Dilimi Örnekleri
|
1 2 3 |
(D:20250625132712+08'00') # June 25, 2024, 1:27:12 PM, UTC+8 (Beijing) (D:20250625132712-05'00') # Same moment in Eastern Standard Time (D:20250625132712Z) # Same moment in UTC (Zulu time) |
🕐 Esnek Tarih Hassasiyeti
PDF tarihleri değişken kesinliği destekler. Sadece bir yıl belirtebilirsiniz (D:2025)veya saniyelere ve saat dilimlerine kadar tam hassasiyet ekleyin. Eksik bileşenler varsayılan olarak makul değerlere ayarlanır (ay/gün için 01, zaman bileşenleri için 00).
🧩 Hepsini Bir Araya Getirmek: Tam Bir Örnek
Tartıştığımız tüm kavramları gösteren, manuel olarak hazırlanmış eksiksiz bir PDF örneğini inceleyelim. Bu üç sayfalık belge, tüm PDF yapısal öğeleri arasındaki etkileşimi sergiliyor.
📄 Tam PDF Yapısı Örneği:
Urvanov Sözdizimi Vurgulayıcı v2.9.1|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
%PDF-1.0 % Header 1 0 obj % Document catalog << /PageLayout /TwoColumnLeft /Pages 2 0 R /Type /Catalog >> endobj 2 0 obj % Root of page tree << /Kids [3 0 R 4 0 R] /Type /Pages /Count 3 >> endobj 3 0 obj % Page one << /Type /Page /Parent 2 0 R /MediaBox [0 0 612 792] % US Letter size /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [5 0 R] >> endobj 4 0 obj % Intermediate page tree node << /Parent 2 0 R /Kids [6 0 R 7 0 R] /Count 2 /Type /Pages >> endobj 5 0 obj % Content stream for page one << /Length 58 >> stream BT /F0 24 Tf 50 750 Td (Hello, PDF World!) Tj ET endstream endobj 6 0 obj % Page two << /Type /Page /Parent 4 0 R /MediaBox [0 0 612 792] /Rotate 90 % Landscape orientation /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [8 0 R] >> endobj 7 0 obj % Page three << /Type /Page /Parent 4 0 R /MediaBox [0 0 612 792] /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [9 0 R] >> endobj 8 0 obj % Content stream for page two << /Length 72 >> stream BT /F0 18 Tf 50 700 Td (This page is rotated 90 degrees) Tj ET endstream endobj 9 0 obj % Content stream for page three << /Length 45 >> stream BT /F0 24 Tf 50 750 Td (Final page) Tj ET endstream endobj 10 0 obj % Document information dictionary << /Title (PDF Structure Example) /Author (PDF Guide Author) /Producer (Manual Creation) /CreationDate (D:20240625132712+08'00') /ModDate (D:20240625133045+08'00') /Subject (Demonstrating PDF internal structure) /Keywords (PDF, structure, example, tutorial) >> endobj xref % Cross-reference table 0 11 0000000000 65535 f 0000000015 00000 n 0000000074 00000 n 0000000120 00000 n 0000000355 00000 n 0000000415 00000 n 0000000522 00000 n 0000000747 00000 n 0000000958 00000 n 0000001079 00000 n 0000001173 00000 n trailer % Trailer dictionary << /Size 11 /Root 1 0 R /Info 10 0 R /ID [<A1B2C3D4E5F6789012345678901234AB> <A1B2C3D4E5F6789012345678901234AB>] >> startxref 1456 %%EOF |
🗺️ Nesne Referans Grafiği
/Boyut 11
/Root 1 0 R → Belge Kataloğu
/Bilgi 10 0 R → Belge Bilgisi
/Tür /Katalog
/Sayfa 2 0 R
/Başlık /Yazar
/OluşturulmaTarihi /ModTarihi
/Tür /Sayfalar
/Çocuklar [3 0 R 4 0 R]
/Say 3
/Tür /Sayfa
/İçindekiler [5 0 R]
/Çocuklar [6 0 R 7 0 R]
/Sayma 2
/İçindekiler [8 0 R]
/Döndür 90
/İçindekiler [9 0 R]
Şekil 3: Fragman sözlüğünün tüm belge bileşenlerine nasıl bağlandığını gösteren nesne referans grafiği
🔍 Örnek Yapının Analizi
🎯 Temel Gözlemler:
- Verimli Gezinme – Kökten maksimum 2 adımda erişilebilen herhangi bir sayfa
- Kaynak Mirası – Yazı tipi kaynakları üst düğümlerden devralınabilir
- Esnek Düzen – Sayfa 2'de rotasyon yetenekleri gösterilmektedir
- Zengin Meta Veri – İş akışı yönetimi için eksiksiz belge bilgileri
- Benzersiz Kimlik – Kimlik dizisi belge takibini etkinleştirir
🚀 İleri Konular ve En İyi Uygulamalar
🔧 Optimizasyon Stratejileri
📈 Performans Optimizasyonu İpuçları:
- Dengeli Ağaçlar – Büyük belgeler için logaritmik erişim sürelerini koruyun
- Kaynak Paylaşımı – Ortak kaynakları üst sayfa ağacı düğümlerine yerleştirin
- Verimli Kodlama – Batı metni için PDFDocEncoding'i, yalnızca gerektiğinde Unicode'u kullanın
- Uygun Miras – Ortak özellikler için sayfa ağacı mirasından yararlanın
- Minimum Meta Veri – Yalnızca gerekli bilgi sözlüğü girişlerini içerir
🛡️ Hata Önleme ve Doğrulama
⚠️ Kaçınılması Gereken Yaygın Tuzaklar:
- Bozuk Referanslar – Tüm dolaylı referansların geçerli nesnelere işaret ettiğinden emin olun
- Tutarsız Sayımlar – Sayfa ağacı sayıları yaprak sayfaları doğru şekilde yansıtmalıdır
- Gerekli Alanlar Eksik – Her zaman zorunlu sözlük girişlerini ekle
- Geçersiz Tarih Formatları – Kesin tarih formatı spesifikasyonlarını takip edin
- Kodlama Uyuşmazlıkları – Unicode ve PDFDocEncoding dizelerini doğru şekilde tanımlayın
🔮 Geleceğe Yönelik Düşünceler
PDF gelişmeye devam ettikçe, bu temel yapıları anlamak giderek daha değerli hale geliyor. Dijital imzalar, erişilebilirlik etiketleri ve etkileşimli formlar gibi modern PDF özelliklerinin tümü, araştırdığımız sağlam temel üzerine inşa edilmiştir.
🌟 Gelişen PDF Teknolojileri:
- PDF/A Standartları – Uzun vadeli arşiv formatları
- PDF/UA Erişilebilirliği – Evrensel erişilebilirlik uyumluluğu
- Etkileşimli Formlar – Dinamik içerik ve kullanıcı etkileşimi
- Dijital İmzalar – Kriptografik belge bütünlüğü
- 3D İçerik – Üç boyutlu model yerleştirme
🎯 Sonuç: PDF Yapısında Uzmanlaşmak
PDF'nin iç yapısını anlamak, gelişmiş belge işleme, sorun giderme ve optimizasyona kapı açar. Fragman sözlüğünün gezinme yeteneklerinden sayfa ağaçlarının verimli organizasyonuna kadar her bileşen, günlük olarak güvendiğimiz sağlam, taşınabilir belgelerin oluşturulmasında belirli bir amaca hizmet eder.
🏆 Temel Çıkarımlar:
- Hiyerarşik Tasarım – PDF'nin ağaç tabanlı yapısı verimli ölçeklendirmeye olanak tanır
- Akıllı Gezinme – Çapraz referans tabloları ve sözlükler hızlı erişim sağlar
- Esnek Kodlama – Çoklu metin kodlamaları küresel belge alışverişini destekler
- Zengin Meta Veri – Kapsamlı bilgi takibi karmaşık iş akışlarını destekler
- Miras Modeli – Kaynak paylaşımı yedekliliği ve dosya boyutunu azaltır
"PDF'nin güzelliği karmaşıklığında değil, bu karmaşıklığın evrensel belge taşınabilirliği basit hedefine hizmet edecek şekilde zarif bir şekilde organize edilmesinde yatmaktadır."
PDF yapısının bu kapsamlı incelemesi, dünyanın en önemli belge formatlarından birinin teknik yönlerini açığa çıkarmayı amaçlıyor. Bu iç unsurları anlamak, geliştiricilere, belge yöneticilerine ve meraklı zihinlere PDF teknolojisiyle daha etkili çalışma gücü verir. kullanılması tavsiye edilir olgun PDF geliştirme kitaplıkları PDF işleme görevlerinizi büyük ölçüde basitleştirmek için.