Datoteka PDF je v svojem bistvu zbirka objektov, ki kažejo drug na drugaga. Če odstranimo stiskanje, vodenje navzkrižnih sklicev in bajtne odmike, ostane le graf: majhen nabor tipiziranih vrednosti, povezanih z referencami, ki izvirajo iz enega samega objekta, ki ga bralnik zna poiskati. Vse, kar PDF lahko izrazi, od odstavka besedila do vgrajene pisave ali digitalnega podpisa, je zgrajeno iz osmih osnovnih tipov objektov in pravila, ki omogoča, da se en objekt sklicuje na drugega. Ko spoznate te osnove, postane preostali del formata jasen in razumljiv
To je logična plast PDF-ja, opredeljena v poglavju 7.3 standarda ISO 32000-1, in se nahaja en nivo nad fizično postavitvijo datoteke (glava, telo, tabela navzkrižnih sklicev in napovednik, kar je tema v tehničnem pregledu zgradbe datotek PDF). Logični model določa pomen teh bajtov po njihovem razčlenjevanju. Pregledovalnik bere datoteko nazaj, da najde napovednik, mu sledi do korena, od tam pa se dokument razvije kot graf objektov, ki se sklicujejo drug na drugega. To je del, o katerem razmišljate, ko odpravljate napake na poškodovani strani, pišete parser ali uporabljate knjižnico za sestavljanje dokumenta
Osem tipov objektov in nič drugega
PDF opredeljuje natanko osem osnovnih tipov objektov. Vsaka vrednost v dokumentu je eden izmed njih, kar ohranja format obvladljiv kljub njegovemu obsegu
Booleans (logične vrednosti) sta ključni besedi true (pravilno) in false (nepravilno). Uporabljata se za vklop in izklop nastavitev, na primer ali se opomba natisne
Numbers (številke) so dveh vrst, ki jih specifikacija obravnava kot en tip: cela števila (kot je 42) in realna števila (kot sta 3.14 ali -0.002). PDF ne podpira eksponentnega zapisa, zato v skladni datoteki nikoli ne boste videli zapisa 1e6. Koordinate, velikosti pisav in koti vrtenja so vsi predstavljeni s številkami
Strings (nizi) vsebujejo zaporedja bajtov, zapisana bodisi v oklepajih, npr. (Hello), bodisi v lomljenih oklepajih kot heksadecimalne vrednosti, npr. <48656C6C6F>. Obe obliki zapisa kodirata enako vsebino; heksadecimalni zapis je rešitev za bajte, ki jih je težko zapisati v oklepajih. Nizi prenašajo besedilo, vendar so v prvi vrsti zaporedja bajtov, kar je pomembno takoj, ko delate z znaki izven nabora ASCII
Names (imena) so atomski žetoni, ki jih uvede poševnica: /Type, /Pages, /MediaBox. Ime ni niz, temveč identifikator, ki se uporablja kot ključ v slovarju ali kot našteta vrednost. Dve imeni sta enaki le, če se ujemata bajt za bajtom. Poševnica je del sintakse in ne del samostojnega imena. To pogosto zmede začetnike, ki menijo, da sta ime /Times-Roman in niz (Times-Roman) medsebojno zamenljiva; format PDF ju obravnava različno
Arrays (polja) so urejeni, heterogeni seznami v oglatih oklepajih: [0 0 612 792] predstavlja pravokotnik strani, polje pa lahko poljubno meša različne tipe, vključno s sklici na druge objekte. Dictionaries (slovarji) so glavno orodje formata. Zapisani so med << and >> ter preslikujejo imena ključev v vrednosti katerega koli tipa. Skoraj vsaka pomembna struktura v PDF-ju (stran, katalog, pisava, opomba) je slovar s ključem /Type, ki določa, za kakšen objekt gre
Streams (tokovi) so slovarji, ki jim sledijo neobdelani bajti med ključnima besedama stream in endstream. Slovar opisuje bajte (njihovo dolžino in morebitne filtre, kot je FlateDecode, ki jih stisnejo), bajti pa prenašajo obsežno vsebino: navodila za izris strani, vgrajene programe pisav, slike. Tok je mesto, kamor PDF shrani vse, kar je preveliko ali preveč binarno, da bi bilo zapisano neposredno v vrstici
Osmi tip je null object (prazni objekt), ki ga predstavlja ključna beseda null. To je dejanska vrednost, ki se razlikuje od odsotnosti ključa. Slovar, ki ima določen ključ na vrednost null, se obravnava, kot da ta ključ sploh ni prisoten, sklic, ki kaže na neobstoječ objekt, pa prav tako vrne null namesto napake. Ta toleranca je namerna: omogoča, da se poškodovana datoteka delno prikaže, namesto da bi se njeno odpiranje popolnoma zavrnilo. Devetega tipa ni; vse, kar PDF izraža, izhaja iz kombiniranja teh osmih primitivev
Neposredne vrednosti, posredni objekti in reference
Vsak od teh osmih tipov se lahko pojavi na dva načina. *Neposredni* (direct) objekt je zapisan na mestu uporabe, kot na primer številka 612 znotraj polja MediaBox. *Posredni* (indirect) objekt pa dobi svojo identiteto, tako da lahko drugi objekti kažejo nanj. Sestavljata ga dve celi števili (številka objekta in številka generacije), definicija pa je ovita med ključni besedi obj in endobj:
12 0 obj
<< /Type /Font /Subtype /Type1 /BaseFont /Helvetica >>
endobjTo je objekt 12, generacije 0, slovar pisave. Kjer koli drugje v datoteki se drug objekt nanj sklicuje s *posredno referenco* (indirect reference): isti dve številki, ki jima sledi črka R, torej 12 0 R. Referenca deluje kot kazalec. Ko slovar virov strani vsebuje zapis /Font << /F1 12 0 R >>, določi objekt 12 kot pisavo za lokalno ime vira /F1, ne da bi kopiral celotno definicijo pisave na to stran
Številka generacije obstaja zaradi brisanja in ponovne uporabe. Ko se objekt sprosti in se njegovo mesto ponovno uporabi, se generacija poveča. S tem se prepreči, da bi zastarel sklic 12 0 R kazal na novega najemnika na mestu 12. Sveže zapisane datoteke so skoraj izključno generacije 0, medtem ko močno urejane datoteke lahko vsebujejo višje številke, parser, ki ignorira številko generacije, pa bo sčasoma prebral napačen objekt
Posrednost (indirection) je tisto, kar naredi PDF učinkovit in enostaven za urejanje. Ena pisava, slika ali barvni prostor se lahko definira enkrat in nato uporabi na stotih straneh. Manjšo spremembo je mogoče dodati kot novo revizijo, ki nadomesti posamezen objekt, namesto da bi ponovno zapisali celotno datoteko. Tabela navzkrižnih sklicev je kazalo, ki številko objekta pretvori v bajtni odmik, tako da bralnik skoči neposredno na 12 0 obj brez iskanja po celotni datoteki, vendar je to fizična optimizacija. Logično je vse, kar morate vedeti, to, da 12 0 R pomeni "objekt z identifikatorjem 12 0"
Katalog: kje se vsak dokument začne
Razreševanje sklicev se mora nekje začeti in ta začetek je vnos /Root v napovedniku, ki kaže na *katalog dokumenta* (document catalog): koren grafa objektov, to je slovar z vrednostjo /Type /Catalog. Bralnik ga doseže najprej, saj najprej najde napovednik, od tam pa so prek sklicev dosegljivi vsi preostali deli dokumenta
Katalog vsebuje le dva strogo zahtevana vnosa: svojo vrsto /Type in /Pages, ki je posreden sklic na koren drevesa strani. Preostali vnosi so neobvezni in opisujejo obnašanje na ravni celotnega dokumenta ter ne same vsebine: /Outlines kaže na drevo zaznamkov, /Names vsebuje imenska drevesa, /Metadata se sklicuje na tok metapodatkov XMP, lastnosti /PageMode in /PageLayout pa pregledovalniku predlagata, kako naj odpre dokument. Nobeden od teh vnosov ni potreben za sam izris strani; le konfigurirajo uporabniško izkušnjo okoli strani. Strukture zaznamkov, metapodatkov in opomb, ki izhajajo iz kataloga, so podrobneje obravnavane v članku o PDF metapodatkih, zaznamkih in opombah
Spodnji diagram prikazuje, kje se telo z objekti nahaja znotraj celotne datoteke. Katalog in drevo strani živita znotraj telesa kot običajna posredna objekta; glava, tabela navzkrižnih sklicev in napovednik okoli njih pa so fizično ogrodje, ki bralniku omogoča, da jih poišče
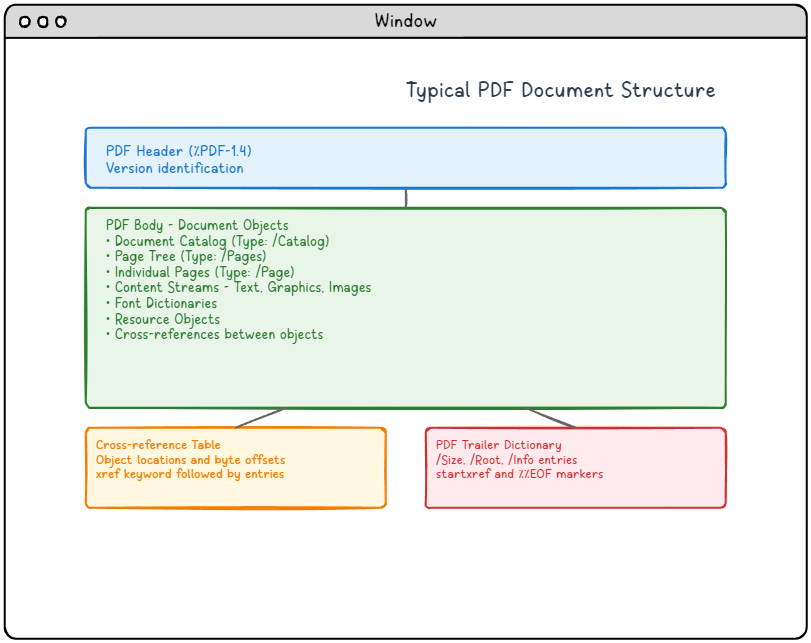
Drevo strani: uravnotežena hierarhija strani
Iz vnosa /Pages se dokument razveji v drevo strani, kjer se pokaže prednost izbire grafa pred navadnim seznamom v PDF-ju. Strani niso shranjene kot preprosto zaporedje, ampak so del drevesa, katerega notranja vozlišča so *vozlišča drevesa strani* (/Type /Pages), listi pa so *objekti strani* (/Type /Page). Notranje vozlišče navaja svoje otroke v polju /Kids in v polju /Count beleži, koliko listnih strani se nahaja pod njim. Vsako vozlišče, razen korenskega, vsebuje sklic /Parent nazaj navzgor, kar omogoča prehajanje drevesa v obe smeri
2 0 obj % root of the page tree
<< /Type /Pages /Kids [3 0 R 4 0 R] /Count 3 >>
endobj
3 0 obj % a leaf page
<< /Type /Page /Parent 2 0 R
/MediaBox [0 0 612 792]
/Resources << /Font << /F1 12 0 R >> >>
/Contents 5 0 R >>
endobj
4 0 obj % an interior node grouping two more pages
<< /Type /Pages /Parent 2 0 R /Kids [6 0 R 7 0 R] /Count 2 >>
endobjTukaj je objekt 2 koren, ki ima pod seboj tri strani: listno stran 3 ter še dve strani, dosegljivi prek notranjega vozlišča 4. Vrednost /Count korenskega objekta (3) se mora ujemati s številom vseh listov pod njim; napačno štetje je pogosta napaka pri ročnem urejanju datotek. Glavni namen drevesa je lokalnost dostopa. Bralnik, ki odpira 900. stran dokumenta s tisoč stranmi, ne pregleduje vseh 900 objektov zaporedno, ampak se spusti skozi le nekaj vozlišč, saj dobro zasnovano drevo ostaja plitko in uravnoteženo. Ročna izdelava takšnega drevesa je zahtevna, celoten proces pa si lahko ogledate v vodniku o gradnji dokumenta PDF od začetka
Drevo strani ima še eno pomembno funkcijo: *dedovanje* (inheritance). Nekaj atributov strani, kot so /Resources, /MediaBox, /CropBox in /Rotate, se lahko nastavi na notranjem vozlišču in izpusti na posameznih straneh, ki nato podedujejo vrednost od najbližjega prednika. Če nastavite /MediaBox enkrat na korenskem vozlišču, bodo vse strani podedovale enako velikost, ne da bi jo morali ponavljati; stran, ki se razlikuje, pa enostavno definira svojo vrednost. To je edino mesto v modelu objektov, kjer je pomen vrednosti odvisen od položaja objekta v drevesu in ne le od njegove lastne vsebine
Kaj dejansko vsebuje listna stran
Objekt strani je stična točka med strukturnim modelom in vidno vsebino. Njen vnos /Contents se sklicuje na enega ali več tokov vsebine (content streams), to so operaterji risanja, ki na stran izrišejo besedilo in grafiko. Njen slovar /Resources (viri) poimenuje pisave, slike in barvne prostore, na katere se ti operaterji zanašajo, pri čemer je vsak vnos posreden sklic na objekt, ki si ga deli več strani. Vnos /MediaBox določa pravokotnik strani v točkah (1/72 palca), vnosa /Rotate in /CropBox pa prilagajata, kako se stran prikaže
Ta delitev dela predstavlja celoten model v malem. Slovar strani je struktura: tipizirani vnosi in reference, ki povedo, kaj stran je in s čim riše. Tok vsebine pa so navodila: ločen, stisljiv binarni blok, ki pove, kako naj se izriše. Pisava za sklicem /F1 je skupni vir, definiran enkrat in uporabljen povsod, kjer je to potrebno. Slovar, tok in referenca sodelujejo pri izrisu ene strani, enaki vzorci pa se prenašajo na celoten dokument. Operaterji toka vsebine znotraj tega bloka so podrobneje opisani v ločenih člankih o besedilu in pisavah ter o grafiki in vizualnih elementih
Zakaj je ta model dobro poznati
Večina razvijalcev spozna model objektov šele takrat, ko gre kaj narobe: stran se izriše prazna zaradi neveljavnega sklica /Contents, besedilo se prikaže kot kvadratki, ker vir pisave ni bil vgrajen, ali pa orodje javi vrednost /Count, ki se ne ujema z dejanskim številom strani. Vsak od teh primerov je neposredno povezan z grafom objektov, zato je branje grafa veliko boljše od ugibanja. Osem tipov in pravilo sklicevanja predstavljajo dovolj preprost nabor izrazov, ki si jih lahko zapomnite. Ko enkrat začnete gledati na PDF kot na objekte, ki kažejo na druge objekte, poškodovane datoteke niso več uganka
Kljub temu pa je ročno zapisovanje tega modela le redko smiselno izven učenja. Ohranjanje pravilnih odmikov tabel navzkrižnih sklicev, številk generacij, števcev drevesa strani in dolžin tokov ob vsakem urejanju je delo, za katero obstajajo knjižnice. V produkcijskem okolju zanesljiva razvojna knjižnica za PDF sama upravlja graf objektov, kar vam omogoča, da razmišljate o straneh in vsebini. Poznavanje modela pa se vseeno izplača: razumete namreč, kaj knjižnica ustvarja v ozadju in zakaj