Понимание внутренней структуры PDF.
Добро пожаловать в увлекательный мир внутренней работы PDF! Вы когда-нибудь задумывались, что скрывается внутри файла PDF? За привычными документами, которые мы видим каждый день, стоит сложная архитектура, которая произвела революцию в обмене цифровыми документами. В этом всестороннем исследовании мы раскроем структуру PDF, чтобы понять сложные механизмы, которые делают эти повсеместные файлы такими, какие они есть.
🔍 Введение: За пределами поверхности.
Portable Document Format (PDF) стал де-факто стандартом для обмена документами во всем мире. От простых текстовых документов до сложных интерактивных форм, PDF обеспечивают единообразный внешний вид на различных платформах и устройствах. Но что скрывается за этой универсальной совместимостью?
В этом глубоком анализе мы рассмотрим логическую структуру, которая делает файлы PDF действительно переносимыми. Мы рассмотрим основные строительные блоки: trailer dictionary, document catalogи дерево страниц—трио, которое управляет всеми функциями PDF. Мы также раскроем секреты специализированных форматов данных PDF для текстовых строк и дат.
🎯 Что вы узнаете в этом руководстве:
- Четыре основных компонента структуры PDF.
- Как PDF эффективно организует и ссылается на контент.
- Роль словарей, каталогов и деревьев страниц.
- Уникальные подходы PDF к кодированию текста и форматированию дат.
- Реальные примеры структуры объектов PDF.
- Рекомендации по пониманию внутренней структуры PDF.
📋 Анатомия PDF: Обзор высокого уровня.
Прежде чем углубляться в детали, давайте сформируем общее представление о структуре PDF. Представьте себе PDF как сложную систему хранения файлов, где каждый элемент информации имеет свое определенное место и назначение.
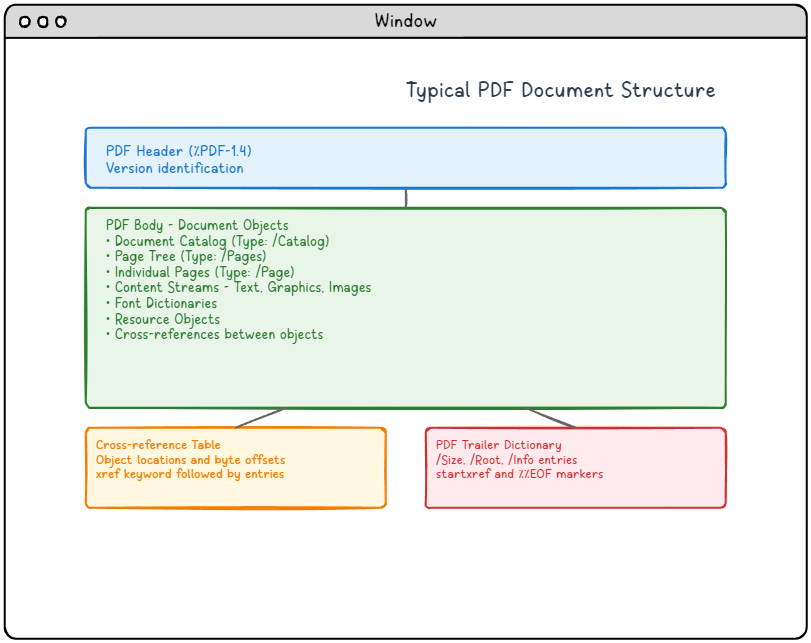
Рисунок 1: Типичная структура PDF-документа, показывающая четыре основных компонента и их взаимосвязи.
Подробное описание схемы структуры PDF:
Эта схема иллюстрирует типичную структуру PDF-документа, состоящую из четырех основных компонентов, расположенных вертикально:
-
- Заголовок PDF (синяя секция вверху): Содержит информацию о версии (например, %PDF-1.4), которая указывает версию формата PDF.
- Тело PDF (зеленая секция в середине): Самая большая секция, содержащая все объекты документа, включая каталог документов, дерево страниц, отдельные страницы, потоки содержимого с текстом/графикой/изображениями, словари шрифтов, объекты ресурсов и перекрестные ссылки между объектами.
- Таблица перекрестных ссылок (оранжевая секция внизу слева): Содержит информацию о местоположении объектов и смещениях в байтах, отмеченную ключевым словом xref, за которым следуют записи.
- Словарь трейлера PDF (красная секция внизу справа): Содержит важную информацию для навигации, включая записи /Size, /Root, /Info, и завершается маркерами startxref и %%EOF.
Стрелки показывают логический поток от заголовка к основному тексту, а затем ветвление к таблице перекрестных ссылок и словаря в конце, иллюстрируя, как программы для чтения PDF-файлов перемещаются по структуре документа.
PDF-документ состоит из четырех основных структурных элементов, работающих в гармонии.
🏗️ Четыре столпа структуры PDF:
- Заголовок – Определяет версию PDF и его возможности.
- Основной текст – Содержит все объекты документа (текст, изображения, шрифты и т.д.).
- Таблица перекрестных ссылок. – Отображает местоположения объектов для быстрого доступа.
- Прицеп. – Предоставляет точку входа для навигации по документу.
Эта структура обеспечивает исключительную эффективность PDF в обработке документов любого размера, от простых одностраничных писем до огромных технических руководств, содержащих тысячи страниц.
🗂️ Словарь "Прицеп": Система GPS для вашего PDF-файла.
Представьте себе, как трудно ориентироваться в библиотеке без системы каталогизации – наступит хаос! Словарь "прицеп" служит сложной системой навигации PDF, предоставляя необходимую карту, которую программы для чтения PDF используют для понимания и отображения вашего документа.
Расположенный в самом конце PDF-файла, словарь "прицеп" парадоксальным образом является одним из первых элементов, обрабатываемых при открытии PDF-файла. Он содержит важную информацию, которая позволяет программному обеспечению находить и интерпретировать все остальные компоненты документа.
🔑 Основные записи в словаре "Прицеп".
| Key | Type | Purpose | Required? |
|---|---|---|---|
/Size |
Integer | Total entries in cross-reference table (usually objects + 1) | ✅ Yes |
/Root |
Indirect Reference | Points to the document catalog—the master control center | ✅ Yes |
/Info |
Indirect Reference | Links to document metadata (title, author, creation date) | ❌ Optional |
/ID |
Array of Strings | Unique document identifier for workflow management | ❌ Optional |
💡 Совет: Понимание идентификаторов PDF.
The /ID Массив содержит две строки: первая устанавливается при создании документа и никогда не меняется, а вторая обновляется при каждом изменении документа. Эта система двойной идентификации обеспечивает сложные рабочие процессы управления документами.
📄 Пример словаря трейлера из реальной жизни:
|
1 2 3 4 5 6 |
<< /Size 421 /Root 377 0 R /Info 375 0 R /ID [<5sazn0fs3tamppia2izf569h281104ae> <6cig0wa61ti593bzuwy41905tr6s5c5a>] >> |
Этот пример показывает трейлер для документа, содержащего 421 объект, где объект 377 является каталогом документа, а объект 375 содержит информацию о документе.
📊 Словарь информации о документе: Традиционные метаданные PDF.
Словарь информации о документе содержит даты создания и изменения файла, а также некоторые простые метаданные. Это традиционная система метаданных, используемая в более старых версиях PDF, которую не следует путать с более полной системой метаданных XMP, которая будет рассмотрена в будущих статьях.
Представьте себе этот словарь как базовую запись в библиотечном каталоге. Хотя он не является необходимым для отображения документа, он предоставляет фундаментальную информацию о происхождении и истории документа с помощью простых текстовых строк.
📋 Поля информации о документе.
| Key | Data Type | Description | Example |
|---|---|---|---|
/Title |
Text String | Document title (separate from any visible title) | “Annual Report 2024” |
/Subject |
Text String | Document subject or description | “Financial Performance Analysis” |
/Keywords |
Text String | Searchable keywords | “finance, quarterly, revenue” |
/Author |
Text String | Document creator | “Jane Smith” |
/Creator |
Text String | Original application that created the document | “Microsoft Word” |
/Producer |
Text String | Application that converted to PDF | “Adobe Acrobat” |
/CreationDate |
Date String | When the document was originally created | D:20240625132712+08’00’ |
/ModDate |
Date String | Last modification timestamp | D:20240626094530+08’00’ |
⚠️ Важное различие.
The /Creator и /Producer поля Creator и Producer имеют разные назначения: Creator определяет приложение, которое изначально создало документ (например, Microsoft Word), а Producer определяет программное обеспечение, которое создало окончательный PDF-файл (например, Adobe Acrobat или драйвер PDF-принтера).
📋 Полный словарь информации о документе:
|
1 2 3 4 5 6 7 8 9 10 |
<< /ModDate (D:20060926213913+02'00') /CreationDate (D:20060926213913+02'00') /Title (Product Catalog - UK Edition) /Creator (QuarkXPress: pictwpstops filter 1.0) /Producer (Acrobat Distiller 6.0 for Macintosh) /Author (James Smith) /Subject (Quarterly Product Showcase) /Keywords (products, catalog, prices, specifications) >> |
🏛️ Каталог документов: Главный центр управления.
Если словарь трейлера - это GPS-система PDF, то каталог документов - это его центральный командный центр. Будучи корневым объектом всей структуры документа, каталог определяет, как все остальные объекты связаны друг с другом и как документ ведет себя при просмотре или печати.
Каждый объект в документе PDF можно получить, используя прямые или косвенные ссылки, начиная с каталога документов. Этот централизованный подход обеспечивает эффективную навигацию и поддерживает целостность документа.
🎛️ Основные записи в каталоге.
| Key | Type | Purpose | Required? |
|---|---|---|---|
/Type |
Name | Must be /Catalog |
✅ Yes |
/Pages |
Indirect Reference | Root of the page tree structure | ✅ Yes |
/PageLabels |
Number Tree | Enables complex page numbering (i, ii, iii, 1, 2, 3) | ❌ Optional |
/Names |
Dictionary | Name trees for referencing objects by name | ❌ Optional |
/Dests |
Dictionary | Named destinations for hyperlinks | ❌ Optional |
/ViewerPreferences |
Dictionary | Controls PDF viewer behavior | ❌ Optional |
/PageMode |
Name | Default viewing mode (thumbnails, bookmarks, etc.) | ❌ Optional |
/PageLayout |
Name | Page display layout (single, facing pages, etc.) | ❌ Optional |
/Outlines |
Indirect Reference | Document bookmarks/outline structure | ❌ Optional |
/Metadata |
Indirect Reference | XMP metadata stream | ❌ Optional |
🎨 Настройки просмотра: Управление пользовательским опытом.
The /ViewerPreferences Словарь позволяет авторам документов влиять на то, как программы просмотра PDF отображают их документы. Это может включать скрытие панелей инструментов, подгонку страниц к окнам или даже управление настройками печати.
📚 Объяснение параметров режима отображения страниц
- /UseNone – Только документ, без панелей навигации
- /UseOutlines – Отображать панель закладок
- /UseThumbs – Отображать миниатюры страниц
- /FullScreen – Войти в режим презентации
- /UseOC – Отобразить панель дополнительных элементов (слоев)
- /UseAttachments – Отобразить панель вложений
🌳 Страницы и древовидные структуры страниц: Эффективная организация контента
Одно из самых гениальных решений в дизайне PDF заключается в том, как он организует страницы. Вместо простого линейного списка, PDF использует древовидную структуру, что значительно повышает производительность, особенно для больших документов.
Представьте, что вам нужно найти конкретную страницу в документе на 1000 страниц, проверяя каждую страницу последовательно – это может занять до 1000 операций! Структура дерева страниц сводит это к нескольким операциям, что делает просмотрщики PDF невероятно быстрыми, даже при работе с огромными документами.
🏗️ Понимание структуры словаря страниц.
Каждая страница в PDF представлена словарем страниц, который объединяет все элементы, необходимые для отрисовки этой конкретной страницы: инструкции по содержимому, ресурсы (шрифты, изображения) и спецификации макета.
| Key | Type | Purpose | Inheritance |
|---|---|---|---|
/Type |
Name | Must be /Page |
❌ |
/Parent |
Indirect Reference | Parent node in page tree | ❌ |
/Resources |
Dictionary | Fonts, images, other resources | ✅ From parent if missing |
/Contents |
Stream/Array | Page content instructions | ❌ |
/MediaBox |
Rectangle | Physical page size | ✅ From parent if missing |
/CropBox |
Rectangle | Visible page area | ✅ Defaults to MediaBox |
/Rotate |
Integer | Page rotation (0, 90, 180, 270) | ✅ From parent if missing |
📐 Понимание системы координат PDF.
PDF использует сложную систему координат, основанную на прямоугольниках, определяемых четырьмя числами, представляющими диагональные углы. Понимание этой системы имеет решающее значение для работы с макетами страниц.
📏 Примеры определения прямоугольников:
|
1 2 |
/MediaBox [0 0 595 842] # A4 size in points (8.27" × 11.69") /CropBox [50 50 545 792] # A4 with 50-point margins on all sides |
💡 Единицы измерения PDF.
PDF использует точки в качестве основной единицы измерения, где 1 точка = 1/72 дюйма. Это упрощает расчеты: 72 точки = 1 дюйм, 144 точки = 2 дюйма и т.д.
🌲 Архитектура дерева страниц.
Преимущество архитектуры дерева страниц заключается в ее сбалансированной структуре. Хорошие приложения для работы с PDF создают деревья, в которых любую страницу можно найти за несколько шагов, независимо от размера документа.
🌳 Пример архитектуры дерева страниц.
/Type /Pages
/Count 7
/Count 3
/Count 2
/Type /Page
/Type /Page
Рисунок 2: Структура дерева страниц для документа из 7 страниц, демонстрирующая сбалансированную иерархию для эффективного доступа.
🎯 Преимущества производительности структуры дерева страниц:
- Время доступа в логарифмическом масштабе – Поиск любой страницы за O(log n) операций.
- Эффективное использование памяти. – Загружайте только необходимые части больших документов.
- Масштабируемая архитектура. – Производительность остается стабильной по мере увеличения размера документов.
- Оптимизация наследования. – Общие свойства, используемые в группах страниц.
📝 Структура узла дерева страниц.
| Key | Type | Purpose |
|---|---|---|
/Type |
Name | Must be /Pages |
/Kids |
Array | References to child nodes (pages or page trees) |
/Count |
Integer | Total number of leaf pages under this node |
/Parent |
Reference | Parent node (required unless root) |
🏗️ Пример реализации дерева страниц:
|
1 2 3 4 5 6 7 8 |
1 0 obj % Root node << /Type /Pages /Kids [2 0 R 3 0 R 4 0 R] /Count 7 >> endobj 2 0 obj % Intermediate node << /Type /Pages /Kids [5 0 R 6 0 R 7 0 R] /Parent 1 0 R /Count 3 >> endobj 5 0 obj % Actual page << /Type /Page /Parent 2 0 R /MediaBox [0 0 612 792] /Resources << >> >> endobj |
🔤 Строки текста: Обработка различных кодировок.
Глобальная распространенность PDF требует надежных возможностей обработки текста. Формат поддерживает различные схемы кодирования для поддержки разных языков и наборов символов, обеспечивая правильное отображение документов независимо от местоположения пользователя.
Понимание кодирования текста в PDF имеет решающее значение для всех, кто работает с документами на разных языках или разрабатывает приложения для обработки PDF.
📝 Два основных метода кодирования.
1. PDFDocEncoding.
Основанный на ISO Latin-1, PDFDocEncoding эффективно обрабатывает большинство западно-европейских языков. Это кодировка по умолчанию для строк текста в PDF и обеспечивает отличную совместимость с устаревшими системами.
2. Unicode (UTF-16BE).
Для международных символов и сложных систем письма PDF использует Unicode с кодировкой UTF-16BE. Строки Unicode идентифицируются специальным маркером порядка байтов (BOM) в начале.
🔍 Обнаружение строк Unicode.
Программы просмотра PDF определяют кодировку, анализируя первые два байта текстовой строки.
|
1 2 3 4 |
If bytes[0] == 254 AND bytes[1] == 255: encoding = "UTF-16BE" # Unicode byte-order marker U+FEFF else: encoding = "PDFDocEncoding" # Default PDF encoding |
⚠️ Ограничение кодировки.
Из-за механизма обнаружения Unicode, строки PDFDocEncoding не могут начинаться с последовательности байтов [254, 255] (þÿ). Однако, это ограничение редко влияет на реальные документы.
📅 Форматы дат: Точная временная информация.
PDF использует сложный формат даты, который не только фиксирует, когда что-то произошло, но и учитывает часовые пояса, что имеет решающее значение для глобальных рабочих процессов и юридических требований.
📋 Структура формата даты PDF.
|
1 |
(D:YYYYMMDDHHmmSSOHH'mm') |
| Component | Meaning | Format | Example |
|---|---|---|---|
| YYYY | Year | Four digits | 2025 |
| MM | Month | 01-12 | 06 (June) |
| DD | Day | 01-31 | 25 |
| HH | Hour | 00-23 | 13 (1 PM) |
| mm | Minute | 00-59 | 27 |
| SS | Second | 00-59 | 12 |
| O | UTC Offset | +, -, or Z | + (later than UTC) |
| HH’ | Offset Hours | 00-23 | 08 (8 hours) |
| mm’ | Offset Minutes | 00-59 | 00 (no minutes) |
🌍 Примеры часовых поясов.
|
1 2 3 |
(D:20250625132712+08'00') # June 25, 2024, 1:27:12 PM, UTC+8 (Beijing) (D:20250625132712-05'00') # Same moment in Eastern Standard Time (D:20250625132712Z) # Same moment in UTC (Zulu time) |
🕐 Гибкая точность выбора даты.
В PDF поддерживается указание дат с различной точностью. Вы можете указать только год. (D:2025)или включайте полную точность, до секунд и часовых поясов. Отсутствующие компоненты по умолчанию принимают разумные значения (01 для месяца/дня, 00 для компонентов времени).
🧩 Объединяя все вместе: полный пример.
Давайте рассмотрим полный пример PDF-файла, созданный вручную, который демонстрирует все концепции, которые мы обсудили. Этот трехстраничный документ демонстрирует взаимодействие всех структурных элементов PDF.
📄 Полный пример структуры PDF-документа:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
%PDF-1.0 % Header 1 0 obj % Document catalog << /PageLayout /TwoColumnLeft /Pages 2 0 R /Type /Catalog >> endobj 2 0 obj % Root of page tree << /Kids [3 0 R 4 0 R] /Type /Pages /Count 3 >> endobj 3 0 obj % Page one << /Type /Page /Parent 2 0 R /MediaBox [0 0 612 792] % US Letter size /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [5 0 R] >> endobj 4 0 obj % Intermediate page tree node << /Parent 2 0 R /Kids [6 0 R 7 0 R] /Count 2 /Type /Pages >> endobj 5 0 obj % Content stream for page one << /Length 58 >> stream BT /F0 24 Tf 50 750 Td (Hello, PDF World!) Tj ET endstream endobj 6 0 obj % Page two << /Type /Page /Parent 4 0 R /MediaBox [0 0 612 792] /Rotate 90 % Landscape orientation /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [8 0 R] >> endobj 7 0 obj % Page three << /Type /Page /Parent 4 0 R /MediaBox [0 0 612 792] /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [9 0 R] >> endobj 8 0 obj % Content stream for page two << /Length 72 >> stream BT /F0 18 Tf 50 700 Td (This page is rotated 90 degrees) Tj ET endstream endobj 9 0 obj % Content stream for page three << /Length 45 >> stream BT /F0 24 Tf 50 750 Td (Final page) Tj ET endstream endobj 10 0 obj % Document information dictionary << /Title (PDF Structure Example) /Author (PDF Guide Author) /Producer (Manual Creation) /CreationDate (D:20240625132712+08'00') /ModDate (D:20240625133045+08'00') /Subject (Demonstrating PDF internal structure) /Keywords (PDF, structure, example, tutorial) >> endobj xref % Cross-reference table 0 11 0000000000 65535 f 0000000015 00000 n 0000000074 00000 n 0000000120 00000 n 0000000355 00000 n 0000000415 00000 n 0000000522 00000 n 0000000747 00000 n 0000000958 00000 n 0000001079 00000 n 0000001173 00000 n trailer % Trailer dictionary << /Size 11 /Root 1 0 R /Info 10 0 R /ID [<A1B2C3D4E5F6789012345678901234AB> <A1B2C3D4E5F6789012345678901234AB>] >> startxref 1456 %%EOF |
🗺️ Объектная ссылка.
/Size 11
/Root 1 0 R → Document Catalog
/Info 10 0 R → Document Info
/Type /Catalog
/Pages 2 0 R
/Title /Author
/CreationDate /ModDate
/Type /Pages
/Kids [3 0 R 4 0 R]
/Count 3
/Type /Page
/Contents [5 0 R]
/Kids [6 0 R 7 0 R]
/Count 2
/Contents [8 0 R]
/Rotate 90
/Contents [9 0 R]
Рисунок 3: Граф ссылок на объекты, показывающий, как словарь трейлера связан со всеми компонентами документа.
🔍 Анализ структуры примера.
🎯 Ключевые наблюдения:
- Эффективная навигация. – Любая страница доступна максимум за 2 шага от корня.
- Наследование ресурсов. – Ресурсы шрифтов могут быть унаследованы от родительских узлов.
- Гибкая компоновка. – Страница 2 демонстрирует возможности поворота.
- Расширенные метаданные. – Полная информация о документе для управления рабочими процессами.
- Уникальная идентификация. – Массив идентификаторов обеспечивает отслеживание документов.
🚀 Продвинутые темы и лучшие практики.
🔧 Стратегии оптимизации.
📈 Советы по оптимизации производительности:
- Сбалансированные деревья. – Обеспечивают логарифмическое время доступа для больших документов.
- Общий доступ к ресурсам. – Размещайте общие ресурсы в узлах дерева страниц родительского уровня.
- Эффективное кодирование. – Используйте PDFDocEncoding для западных текстов, Unicode только при необходимости.
- Правильное наследование. – Используйте наследование дерева страниц для общих свойств.
- Минимальные метаданные. – Включайте только необходимые записи в словаре.
🛡️ Предотвращение ошибок и проверка.
⚠️ Распространенные ошибки, которых следует избегать:
- Некорректные ссылки. – Убедитесь, что все косвенные ссылки указывают на допустимые объекты.
- Несоответствие количества. – Количество элементов в дереве страниц должно точно отражать количество листовых страниц.
- Отсутствуют обязательные поля. – Всегда включайте обязательные записи в словаре.
- Недопустимые форматы дат. – Соблюдайте точные спецификации формата даты.
- Несоответствия кодировки. – Правильно определяйте строки Unicode и PDFDocEncoding.
🔮 Планы на будущее.
По мере дальнейшего развития формата PDF, понимание этих фундаментальных структур становится все более важным. Современные функции PDF, такие как цифровые подписи, теги доступности и интерактивные формы, основаны на надежной основе, которую мы изучили.
🌟 Новые технологии PDF:
- Стандарты PDF/A – Форматы для долгосрочного архивирования
- Доступность PDF/UA – Соответствие требованиям универсальной доступности
- Интерактивные формы – Динамический контент и взаимодействие с пользователем
- Электронные подписи – Криптографическая целостность документов.
- 3D контент. – Встраивание трехмерных моделей.
🎯 Заключение: Освоение структуры PDF.
Понимание внутренней структуры PDF открывает возможности для расширенной обработки документов, устранения неполадок и оптимизации. От возможностей навигации, предоставляемых словарем "trailer", до эффективной организации дерева страниц, каждый компонент выполняет определенную функцию при создании надежных и переносимых документов, которыми мы ежедневно пользуемся.
🏆 Ключевые выводы:
- Иерархическая структура. – Древовидная структура PDF обеспечивает эффективное масштабирование.
- Интеллектуальная навигация. – Перекрестные ссылки и словари обеспечивают быстрый доступ.
- Гибкое кодирование. – Поддержка нескольких текстовых кодировок для глобального обмена документами.
- Расширенные метаданные. – Комплексное отслеживание информации поддерживает сложные рабочие процессы.
- Модель наследования. – Общий доступ к ресурсам снижает избыточность и размер файлов.
«Красота PDF заключается не в его сложности, а в том, как эта сложность элегантно организована для достижения простой цели – универсальной переносимости документов».
Это всестороннее исследование структуры PDF, направленное на то, чтобы сделать технические аспекты одного из самых важных форматов документов в мире более понятными. Понимание этих внутренних механизмов позволяет разработчикам, менеджерам документов и любознательным людям более эффективно работать с технологией PDF. Рекомендуется использовать зрелые библиотеки разработки PDF для значительного упрощения задач обработки PDF.