Освоение текста и шрифтов PDF: руководство для разработчиков.
Документы PDF произвели революцию в том, как мы обмениваемся и сохраняем форматированный текст на различных платформах и устройствах. Но за безупречным внешним видом каждого PDF-документа скрыта сложная система рендеринга текста, которая сочетает в себе передовые типографские концепции с точными математическими операциями. Понимание того, как PDF обрабатывает текст и шрифты, имеет решающее значение для разработчиков, работающих с генерацией документов, извлечением текста или манипулированием PDF.
Это подробное руководство проведет вас в мир рендеринга текста PDF, охватывая все: от базового интервала между символами до сложных методов внедрения шрифтов, систем кодирования символов и сложных задач извлечения текста. Независимо от того, являетесь ли вы опытным разработчиком или только начинаете работать с технологиями PDF, вы получите ценные знания о том, как на самом деле работают эти повсеместные документы.
Философия рендеринга текста PDF.
Когда Adobe создала Portable Document Format, она столкнулась с фундаментальной проблемой проектирования, которая определила, как будут отображаться миллиарды документов сегодня. Вопрос заключался в том, как найти баланс между гибкостью и согласованностью в мире, где документы должны выглядеть одинаково на самых разных системах, от высококачественных принтеров до мобильных устройств.
Они могли выбрать один из двух крайних подходов:
- Подход динамической компоновки: Хранить обычный текст с инструкциями по компоновке, аналогично тому, как это работает в программном обеспечении для верстки, что позволяет выполнять расчеты форматирования и отображения текста в режиме реального времени.
- Чисто графический подход: Преобразование всего текста в векторную графику во время создания обеспечивает идеальную визуальную согласованность, но полностью теряет все семантическое значение и текстовую функциональность.
Вместо этого, PDF использует то, что мы можем назвать "золотой серединой" – сложный компромисс, который сочетает в себе лучшие черты обоих подходов, избегая при этом их недостатков. Эта гибридная система сохраняет основные концепции шрифтов и символов, одновременно предварительно рассчитывая большинство решений по компоновке во время создания документа.
Стратегические преимущества подхода PDF:
Полный контроль и предсказуемость компоновки:
Глобальные решения по форматированию, такие как переносы абзацев, межстрочный интервал, ширина столбцов и компоновка страницы, обрабатываются приложением при создании PDF. Это означает, что ваш документ будет выглядеть одинаково, независимо от того, просматривается ли он на смартфоне в Токио, отображается на мониторе 4K в Кремниевой долине или печатается на лазерном принтере в Нью-Йорке. Целостность компоновки сохраняется во всех сценариях просмотра, устраняя непредсказуемые проблемы с переформатированием, которые свойственны другим форматам документов.
Предсказуемая типографика на уровне отдельных элементов:
Операции с текстом на уровне отдельных элементов, такие как позиционирование символов, межсловные интервалы и масштабирование шрифтов, стандартизированы с помощью комплексного набора четко определенных операторов. Это позволяет точно контролировать типографику, сохраняя при этом предсказуемое поведение в различных программах просмотра и обработчиках PDF. Система поддерживает сложные типографические функции, такие как кернинг, лигатуры и контекстная замена символов, обеспечивая при этом стабильные результаты.
Эффективное хранение и управление ресурсами.
Рассматривая шрифты как библиотеки многократно используемых форм символов, файлы PDF остаются относительно компактными, даже для документов с большим количеством текста. Вместо хранения векторного контура каждой буквы по отдельности, документы ссылаются на общие определения шрифтов, которые могут быть повторно использованы на нескольких страницах и даже в нескольких документах. Этот подход значительно уменьшает размер файла, обеспечивая при этом сложные стратегии подмножества и встраивания шрифтов.
Семантическое сохранение для обеспечения доступности.
В отличие от чисто графических подходов, PDF сохраняет важную связь между визуальными глифами и их основными кодами символов. Это сохранение обеспечивает важные функции, такие как поиск текста, операции копирования и вставки, доступность для экранных читалок и автоматический анализ контента. Формат поддерживает сопоставление Unicode, альтернативные текстовые описания и информацию о структуре, которая делает документы доступными для вспомогательных технологий.
Комплексная система текстовых параметров PDF.
Система рендеринга текста в PDF работает с помощью сложного набора параметров состояния, которые взаимодействуют друг с другом для управления каждым аспектом того, как текст отображается на странице. Представьте эти параметры как комплексную панель управления, которая контролирует не только основные аспекты внешнего вида, но и расширенные типографские функции, расчеты позиционирования и оптимизацию рендеринга.
Полная система параметров состояния текста включает в себя:
| Parameter | Operator | Description | Default Value |
|---|---|---|---|
| Character Spacing | Tc | Additional space between characters | 0 |
| Word Spacing | Tw | Additional space between words | 0 |
| Horizontal Scaling | Tz | Horizontal scaling percentage | 100 |
| Leading | TL | Line spacing for T* operator | 0 |
| Font and Size | Tf | Font selection and scaling | N/A |
| Text Rendering Mode | Tr | Fill, stroke, or path mode | 0 (Fill) |
| Text Rise | Ts | Vertical text displacement | 0 |
Интервал между символами (оператор Tc) – точный контроль типографики.
Параметр интервала между символами обеспечивает точный контроль над дополнительным пространством, вставляемым между каждым символом в строке текста. Этот параметр измеряется в единицах текстового пространства, которые обычно составляют 1/1000 от размера шрифта, что позволяет выполнять чрезвычайно точные настройки.
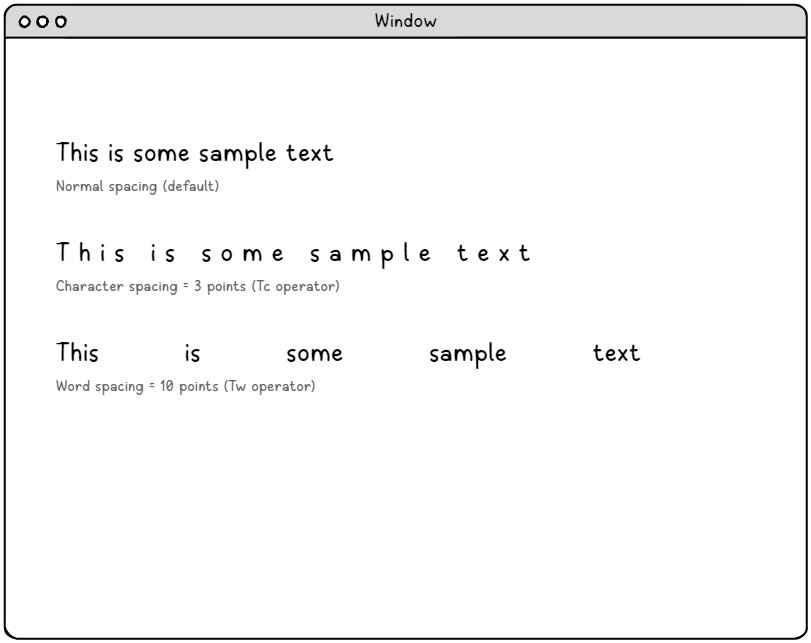
Области применения интервала между символами включают:
- Улучшение типографики: Создание акцентов или повышение читабельности в заголовках и основном тексте.
- Поддержка выравнивания: Тонкая настройка длины строк в выровненных текстовых макетах.
- Соблюдение фирменного стиля: Соответствие конкретным типографическим стилям, требуемым корпоративными руководствами.
- Доступность: Улучшение читаемости для пользователей с дислексией или нарушениями зрения.
|
1 2 3 4 5 6 7 8 9 10 11 |
BT /F0 24 Tf 1 0 0 1 50 700 Tm (Normal text spacing) Tj 0 -30 Td 3 Tc (Character spacing = 3 points) Tj 0 -30 Td -1 Tc (Tight character spacing = -1 point) Tj ET |
Межсловный интервал (Tw Operator) – интеллектуальное управление интервалами.
Межсловный интервал предназначен для работы с символом пробела (ASCII 32) в текстовых строках, обеспечивая точный контроль над интервалами между словами, не затрагивая другие символы пробелов. Такая точность бесценна для алгоритмов выравнивания текста и создания профессиональных макетов документов.
Оператор Tw демонстрирует продвинутый подход PDF к типографике, поскольку он учитывает, что разные типы интервалов служат разным целям. В то время как кернинг влияет на все символы одинаково, межсловный интервал влияет только на границы слов, что дает дизайнерам точный контроль над текстом и его читаемостью.
|
1 2 3 4 5 6 7 8 9 10 11 |
BT /F0 24 Tf 1 0 0 1 50 600 Tm (Normal word spacing) Tj 0 -30 Td 10 Tw (Extended word spacing improves readability) Tj 0 -30 Td -2 Tw (Compressed word spacing saves space) Tj ET |
Горизонтальное масштабирование (Tz Operator) – контроль над типографикой по размерности.
Горизонтальное масштабирование позволяет растягивать или сжимать текст горизонтально, не влияя на его высоту, и выражается в процентах, где 100% соответствует нормальной ширине. Этот параметр обеспечивает адаптивную типографику и специальные типографские эффекты, которые были бы невозможны с использованием традиционных методов набора текста.
Применение горизонтального масштабирования:
- Макеты с ограниченным пространством: Подгонка текста под заданные ширины столбцов или элементы дизайна.
- Стилистические эффекты: Создание сжатого или расширенного текста для заголовков и выделения.
- Эмуляция шрифтов: Имитация сжатых или расширенных вариантов шрифтов при их недоступности.
- Адаптивный дизайн: Адаптация текста к разным размерам страниц при сохранении читаемости.
Однако, горизонтальное масштабирование следует использовать с осторожностью. Чрезмерное масштабирование может ухудшить читаемость и создать неестественный текст, что нарушает процесс чтения. Рекомендуется ограничивать масштабирование диапазоном от 85% до 115% для основного текста, а более значительное масштабирование следует использовать только для целей отображения.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
BT /F0 24 Tf 1 0 0 1 50 500 Tm 100 Tz (Normal horizontal scaling - 100%) Tj 0 -30 Td 80 Tz (Condensed text - 80% scaling) Tj 0 -30 Td 120 Tz (Extended text - 120% scaling) Tj ET |
Междустрочный интервал (TL Operator) – Вертикальный ритм и читаемость.
Междустрочный интервал, произносится "ledding", происходит от традиционной типографики, где тонкие полоски свинца вставлялись между строками текста. В PDF, междустрочный интервал определяет вертикальное пространство между базовыми линиями текста и контролирует, насколько текст перемещается при использовании оператора T*.
Правильный междустрочный интервал имеет решающее значение для обеспечения читаемого вертикального ритма в тексте. Отношение между размером шрифта и междустрочным интервалом значительно влияет на читаемость, скорость понимания и общую эстетику документа. Эксперты в области типографики обычно рекомендуют значения междустрочного интервала от 120% до 145% от размера шрифта для оптимальной читаемости.
Рекомендации по междустрочному интервалу:
- Отношение размера шрифта: Обычно, для шрифтов большего размера требуется пропорционально большее значение междустрочного интервала.
- Влияние длины строки: Более длинные строки лучше воспринимаются при увеличении межстрочного интервала, что помогает читателям следить за началом следующей строки.
- Характеристики шрифта: Шрифты с большой высотой строчных букв или декоративными элементами могут требовать корректировки межстрочного интервала.
- Контекст чтения: Разные типы контента (основной текст, подписи, заголовки) имеют разные требования к межстрочному интервалу.
|
1 2 3 4 5 6 7 8 9 10 |
BT /F0 18 Tf 18 TL 1 0 0 1 50 400 Tm (This text uses 18pt leading) Tj T* (which matches the font size) Tj T* 24 TL (This text uses 24pt leading) Tj T* (providing more generous spacing) Tj T* ET |
Вертикальное смещение текста (оператор Ts) – точность вертикального позиционирования.
Вертикальное смещение текста обеспечивает точную вертикальную настройку, позволяя перемещать текст вверх или вниз от базовой линии, не влияя на общий поток текста. Этот параметр необходим для создания профессиональных типографских элементов, требующих точного вертикального позиционирования.

Области применения вертикального смещения текста включают:
- Математическая нотация: Расположение показателей степени, нижних индексов и математических символов.
- Научный контент: Химические формулы, молекулярные структуры и научные аннотации.
- Элементы редактуры: Символы сносок, символы товарных знаков и уведомления об авторских правах.
- Многоязычная типографика: Корректировка базовых линий для различных систем письма.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
BT /F0 36 Tf 1 0 0 1 140 290 Tm (H) Tj -8 Ts /F0 24 Tf (2) Tj 0 Ts /F0 36 Tf (O represents water with O) Tj 8 Ts /F0 24 Tf (2) Tj 0 Ts /F0 36 Tf ( as oxygen) Tj ET |
Расширенные преобразования текста и матричные операции.
Одной из самых сложных функций PDF является возможность бесшовного объединения преобразований текста с преобразованиями графики с помощью системы двойных матриц. Эта возможность обеспечивает сложные эффекты компоновки, сохраняя при этом математическую точность, необходимую для обеспечения согласованности операций позиционирования текста в различных условиях просмотра.

Система преобразований работает с использованием двух основных матриц:
Текущая матрица преобразований (CTM).
CTM управляет глобальными преобразованиями координат, которые влияют на все графические элементы, включая текст. Она управляет такими операциями, как поворот, масштабирование, перемещение и наклон на уровне страницы. Применение преобразования с помощью операторов, таких как cm (объединение матриц), изменяет CTM.
Матрица текста (TM).
TM специально предназначена для управления позиционированием текста и локальными преобразованиями текста. Она работает в сочетании с CTM, чтобы обеспечить правильную работу операций позиционирования текста, таких как переносы строк, продвижение символов и форматирование абзацев, даже когда весь текстовый блок преобразован.
Последовательность преобразований матриц.
При отрисовке текста в формате PDF используется строгая математическая последовательность.
- Расчет интервала между глифами: Форма каждого символа определяется координатами в пространстве глифов.
- Преобразование пространства текста: Символы располагаются в пространстве текста с использованием параметров размера шрифта и состояния текста.
- Применение текстовой матрицы: Текстовая матрица преобразует координаты из пространства текста в пространство пользователя.
- Применение графической матрицы: Текущая матрица преобразования определяет окончательное положение и ориентацию.
- Преобразование в систему координат устройства: Координаты преобразуются в единицы, специфичные для устройства, для отрисовки.
Этот многоступенчатый процесс обеспечивает математическую точность и визуальную согласованность преобразований текста в различных условиях просмотра, на разных устройствах вывода и при разных коэффициентах масштабирования.
|
1 2 3 4 5 6 7 8 9 10 11 |
% Set up rotation transformation 0.96 0.25 -0.25 0.96 0 0 cm BT /F0 48 Tf 48 TL % Set text matrix for positioning 1 0 0 1 270 240 Tm (Text and graphics) Tj T* (transforms combined) Tj T* (with proper newlines) Tj ET |
Практическое применение преобразований текста.
- Повернутые заголовки и метки: Создание текста под углом для графиков, диаграмм и специализированных макетов.
- Художественная типографика: Реализация креативных текстовых эффектов при сохранении читаемости.
- Документы с многосторонней ориентацией: Поддержка документов, содержащих элементы как книжной, так и альбомной ориентации.
- Выравнивание системы координат: Сопоставление ориентации текста с существующими графическими системами координат.
Комплексный выбор шрифтов и управление ресурсами.
Обработка шрифтов в PDF включает в себя сложную систему управления ресурсами, которая выходит далеко за рамки простого выбора шрифта. Система должна эффективно управлять ресурсами шрифтов, схемами кодирования символов, операциями масштабирования и требованиями совместимости, обеспечивая при этом оптимальную производительность рендеринга в различных средах просмотра.
Система словарей ресурсов шрифтов.
PDF-документы поддерживают иерархическую структуру словарей шрифтов, которая сопоставляет символические имена с фактическими ресурсами шрифтов. Этот уровень косвенности выполняет несколько важных функций в архитектуре документа:
- Оптимизация ресурсов: Несколько страниц и потоков содержимого могут совместно использовать идентичные ресурсы шрифтов без дублирования.
- Управление заменой: Механизмы резервного копирования шрифтов могут быть реализованы на уровне ресурсов без влияния на потоки содержимого.
- Управление кодировкой: Схемы кодировки символов могут быть связаны с конкретными экземплярами шрифтов.
- Повышение производительности: Загрузка и обработка шрифтов могут быть оптимизированы с помощью интеллектуальных стратегий кэширования.
Типы шрифтов и технические характеристики.
Шрифты Type 1 (PostScript).
Шрифты Type 1 представляют собой оригинальную технологию масштабируемых шрифтов от Adobe, использующую кубические кривые Безье для определения контуров символов с математической точностью. Эти шрифты отлично подходят для профессиональных издательских приложений благодаря своим превосходным характеристикам масштабируемости и сложным системам подсказок.
Основные особенности шрифтов Type 1:
- Контуры на основе кривых Безье: Математически точные определения кривых, которые плавно масштабируются до любого размера.
- Подсказки PostScript: Интеллектуальная адаптация контуров для оптимальной отрисовки при небольших размерах.
- Гибкость кодирования: Поддержка пользовательских кодировок символов и специализированных наборов символов.
- Совместимость с встраиваемыми шрифтами: Полная поддержка встраиваемых шрифтов с механизмами соблюдения лицензионных требований.
Шрифты TrueType:
Шрифты TrueType используют квадратичные кривые Безье и содержат сложную информацию для подсказок, специально оптимизированную для отображения на экране и устройствах с низким разрешением. Изначально разработанные компанией Apple, а затем принятые компанией Microsoft, шрифты TrueType обеспечивают отличную кросс-платформенную совместимость.
Преимущества шрифтов TrueType:
- Оптимизация экрана: Продвинутые системы подсказок, оптимизированные для выравнивания по пиксельной сетке.
- Совместимость с платформами: Широкая поддержка различных операционных систем и приложений.
- Компактное хранение: Эффективное представление контуров с использованием квадратичных кривых.
- Поддержка Unicode: Нативная поддержка больших наборов символов и международного текста.
Шрифты OpenType.
OpenType представляет собой эволюцию цифровой типографики, объединяющую лучшие технические характеристики шрифтов Type 1 и TrueType, а также добавляющую революционные типографские возможности, которые меняют способ отображения профессионального текста.
Инновации OpenType:
- Расширенная типографика: Контекстные лигатуры, завитушки, альтернативные символы и стилистические наборы.
- Обширные наборы символов: Поддержка тысяч символов и нескольких систем письма.
- Интеллектуальная компоновка: Сложные правила для контекстной замены и позиционирования символов.
- Согласованность на разных платформах: Идентичное поведение рендеринга в различных системах и приложениях.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
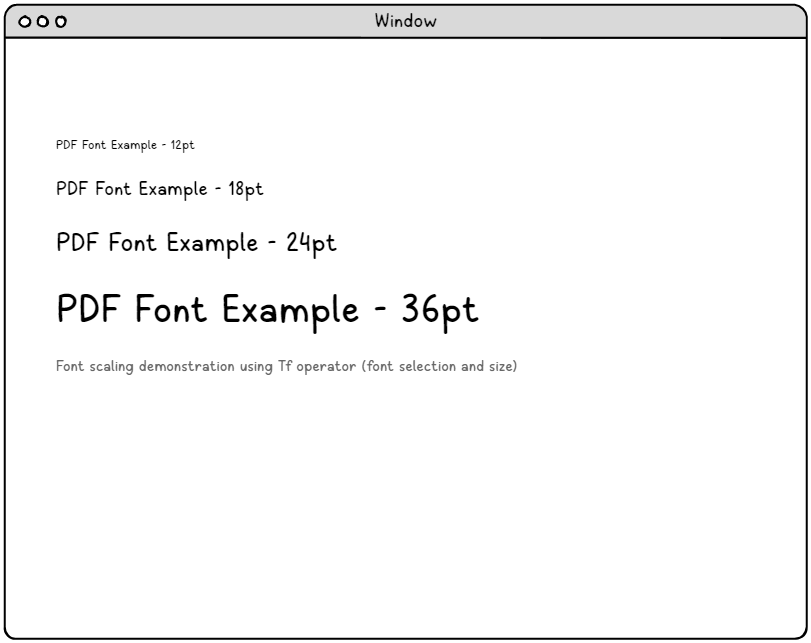
BT % Select font and set initial size /F0 12 Tf 1 0 0 1 50 750 Tm (12-point font example) Tj % Change to larger size, same font /F0 18 Tf 0 -25 Td (18-point font example) Tj % Even larger size /F0 24 Tf 0 -35 Td (24-point font example) Tj % Largest size /F0 36 Tf 0 -50 Td (36-point font example) Tj ET |
Профессиональная настройка кернинга и позиционирования глифов.
Профессиональная типографика требует точного контроля над расстоянием между отдельными символами. Визуальное пространство между различными комбинациями букв значительно варьируется в зависимости от форм символов, и интеллектуальная настройка кернинга необходима для создания визуально привлекательного и легко читаемого текста, соответствующего профессиональным стандартам полиграфии.

Оператор TJ обеспечивает расширенные возможности позиционирования глифов, выходящие за рамки простого контроля за расстоянием между символами и словами. Вместо работы с монолитными текстовыми строками, TJ принимает гетерогенный массив, который обеспечивает точное позиционирование на уровне символов.
Понимание архитектуры массива TJ.
Подход, основанный на массивах, в операторе TJ, революционизирует позиционирование текста, принимая смешанный контент:
- Строковые элементы: Содержат фактическое текстовое содержимое, которое отображается с использованием стандартной кодировки шрифта.
- Числовые элементы: Указывают горизонтальные корректировки, измеряемые тысячными долями единицы текстового пространства.
- Отрицательные значения: Сдвигают последующие символы ближе друг к другу, уменьшая расстояние между символами.
- Положительные значения: Увеличивают расстояние между символами, расширяя компоновку текста.
Этот детальный контроль обеспечивает типографику профессионального качества с точной настройкой кернинга, что было бы невозможно с использованием более простых текстовых операторов. Система позволяет как улучшить эстетику, так и внести технические исправления в параметры шрифта.
|
1 2 3 4 5 6 7 8 9 |
BT /F0 48 Tf 1 0 0 1 100 400 Tm % Standard text rendering (WAVE Type) Tj 0 -60 Td % Kerned text with precise adjustments [(W) -120 (A) -80 (V) -100 (E) 50 (T) -20 (y) -10 (p) -5 (e)] TJ ET |
Продвинутые стратегии кернинга.
Оптический кернинг.
Оптический кернинг регулирует расстояние между символами на основе визуального восприятия комбинаций символов, а не только на основе встроенных параметров шрифта. Этот подход учитывает фактические формы соседних символов и их визуальное взаимодействие.
Кернинг на основе параметров.
Кернинг на основе параметров использует встроенные таблицы кернинга шрифта для регулировки расстояния между определенными парами символов. Профессиональные шрифты содержат обширные таблицы кернинга с тысячами настроек для пар символов.
Ручной кернинг.
Ручной кернинг позволяет выполнять точную настройку для каждого символа, чтобы удовлетворить конкретные требования дизайна или исправить проблемные комбинации символов, которые недостаточно хорошо обрабатываются автоматическими системами кернинга.
Практические применения кернинга.
- Логотип и фирменный стиль: Точный контроль над типографикой корпоративного стиля.
- Типографика заголовков: Оптимизация большого текста для максимального визуального эффекта.
- Тонкая настройка типографики: Достижение качества типографской верстки.
- Поддержка нескольких языков: Корректировка интервалов для различных систем письма и комбинаций символов.
Режимы отображения текста и визуальные эффекты.
PDF предлагает восемь различных режимов отображения текста, которые контролируют визуальное представление текста, обеспечивая широкие возможности для создания разнообразных типографских эффектов. Эти режимы определяют, будет ли текст заполнен, обведен, использоваться для обрезки или отображаться невидимо для специальных целей.
Полная справочная информация по режимам отображения текста.
| Mode | Name | Visual Effect | Common Uses |
|---|---|---|---|
| 0 | Fill | Solid color fill only | Standard body text |
| 1 | Stroke | Outline only, no fill | Decorative headers |
| 2 | Fill and Stroke | Both fill and outline | Emphasized text |
| 3 | Invisible | No visual rendering | Text positioning |
| 4 | Fill and Add to Path | Fill plus path construction | Text-based clipping |
| 5 | Stroke and Add to Path | Stroke plus path construction | Complex path operations |
| 6 | Fill, Stroke, and Add to Path | Complete text with path | Advanced graphics integration |
| 7 | Add to Path Only | Path construction, no rendering | Clipping path creation |
Продвинутые применения режимов отображения.
Режим невидимого текста (режим 3).
Невидимый текст выполняет несколько специализированных функций в документах PDF:
- PDF-изображения с возможностью поиска. Накладывайте невидимый текст на отсканированные документы для обеспечения возможности поиска.
- Позиционирование текста: Перемещайте текст без визуального вывода для сложных макетов.
- Улучшение доступности: Предоставляйте альтернативные текстовые описания без визуальных отвлекающих факторов.
- Системы шаблонов: Создавайте структуры позиционирования для динамической генерации контента.
Режимы построения путей (режимы 4-7).
Эти расширенные режимы обеспечивают сложную интеграцию между системами обработки текста и графики.
- Обрезка на основе текста: Используйте текстовые фигуры для обрезки других графических элементов.
- Сложная маскировка: Создавайте сложные эффекты маскировки с использованием форм символов.
- Художественные эффекты: Объединяйте текст с градиентами, узорами и другими графическими элементами.
- Интерактивные элементы: Создавайте кликабельные области, точно соответствующие границам текста.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
BT /F0 36 Tf 1 0 0 1 100 500 Tm % Standard filled text 0 Tr (Filled Text) Tj 0 -50 Td % Stroked text only 1 Tr 2 w (Stroked Text) Tj 0 -50 Td % Both filled and stroked 2 Tr (Filled and Stroked) Tj ET |
Встраивание шрифтов и оптимизация подмножеств.
Встраивание шрифтов является одним из наиболее важных технических вызовов при создании PDF-документов, поскольку необходимо учитывать баланс между переносимостью документа, оптимизацией размера файла и соблюдением юридических требований. Система встраивания должна обеспечивать одинарное отображение документов на различных системах, соблюдая ограничения лицензий на шрифты и поддерживая разумный размер файла.
Стратегии встраивания шрифтов.
Полное встраивание шрифтов.
Полное встраивание шрифтов включает в себя весь файл шрифта в PDF-документ, обеспечивая идеальную совместимость отображения, но увеличивая размер файла. Этот подход гарантирует, что все символы, информация о кернинге и типографские особенности остаются доступными.
Преимущества:
- Полная совместимость: Все функции шрифта остаются доступными независимо от целевой системы.
- Точность отображения: Идеальная воспроизведение оригинальной типографики и интервалов.
- Сохранение функциональности: Расширенные функции OpenType остаются работоспособными.
- Обеспечение совместимости в будущем: Документы остаются читаемыми даже при изменении доступности шрифтов.
Недостатки:
- Влияние на размер файла: Значительное увеличение размера документа, особенно при использовании нескольких шрифтов.
- Вопросы лицензирования: Может нарушать условия лицензионных соглашений на шрифты, которые ограничивают их встраивание.
- Накладные расходы на обработку: Увеличение использования памяти и времени обработки при загрузке шрифтов.
Подмножество шрифтов:
Подмножество шрифтов встраивает только символы, фактически используемые в документе, что значительно уменьшает размер файла, сохраняя при этом точность отображения для включенного набора символов.
Преимущества использования подмножества:
- Оптимальный размер файла: Минимальное влияние на размер документа при сохранении типографики.
- Соответствие требованиям лицензирования: Снижение юридических рисков, так как используются только необходимые символы.
- Повышение производительности: Более быстрая загрузка шрифтов и снижение использования памяти.
- Эффективность использования полосы пропускания: Меньшие документы передаются быстрее по сети.
Кодировка символов и отображение Unicode.
Система кодировки символов PDF должна обеспечивать связь между кодами символов, специфичными для шрифта, и универсальными системами идентификации символов, такими как Unicode. Этот процесс отображения имеет решающее значение для извлечения текста, поиска и функций доступности.
Механизмы кодирования.
Встроенная кодировка: Использует внутреннее отображение символов шрифта, подходит для стандартных западных наборов символов, но ограничена для международного контента.
Стандартные кодировки PDF: Заранее определенные схемы кодирования, такие как WinAnsiEncoding и MacRomanEncoding, которые обеспечивают согласованное отображение символов на разных платформах.
Пользовательское кодирование: Отображения символов, специфичные для документа, которые обеспечивают поддержку специальных символов или устаревших систем шрифтов.
Системы Unicode (CMap): Современный подход с использованием таблиц отображения символов (CMaps), которые обеспечивают прямое соответствие между кодами символов и значениями Unicode.
Таблицы отображения в Unicode (ToUnicode Mapping Tables).
Таблицы CMaps ToUnicode обеспечивают точное извлечение и поиск текста, предоставляя мост между кодами символов, специфичными для шрифта, и значениями Unicode. Эти таблицы отображения необходимы для обеспечения доступности и анализа контента.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
% Example ToUnicode CMap structure 23 0 obj << /Length 317 >> stream /CIDInit /ProcSet findresource begin 12 dict begin begincmap /CIDSystemInfo << /Registry (Adobe) /Ordering (UCS) /Supplement 0 >> def /CMapName /Adobe-Identity-UCS def 1 begincodespacerange <0001> endcodespacerange 2 beginbfchar <0001> <0041> % Map glyph 1 to Unicode U+0041 (A) <0002> <0042> % Map glyph 2 to Unicode U+0042 (B) endbfchar endcmap CMapName currentdict /CMap defineresource pop end end endstream endobj |
Сложная задача извлечения текста из PDF.
Извлечение текста из документов PDF является одним из наиболее сложных технических аспектов обработки PDF, требующим сложных алгоритмов, которые могут восстановить логический порядок чтения из формата, ориентированного на графику. В отличие от традиционных текстовых форматов, которые сохраняют семантическую структуру, PDF хранит текст в виде последовательности графических элементов, расположенных в определенных позициях, что делает извлечение сложным процессом обратной инженерии.
Основные проблемы извлечения.
Непоследовательное расположение текста.
В PDF-документах элементы текста располагаются на основе визуальной компоновки, а не логического порядка чтения. Один абзац может быть представлен десятками отдельных команд позиционирования текста, разбросанных по всему потоку содержимого, и перемежающихся с графическими операциями и другими нетекстовыми элементами.
Такой подход к позиционированию создает несколько трудностей при извлечении:
- Восстановление порядка чтения: Определение правильной последовательности для элементов текста, расположенных не по порядку.
- Обнаружение колонок: Определение многоколоночной верстки и определение правильного порядка следования колонок.
- Анализ структуры страницы: Различение заголовков, нижних колонтитулов, боковых панелей и основных областей контента.
- Разрешение перекрестных ссылок: Соединение связанных текстовых элементов, разделенных графикой или форматированием.
Проблемы со шрифтами и кодировкой.
Извлечение символов требует точной интерпретации схем кодирования шрифтов, которые могут значительно различаться между разными шрифтами и системами создания документов:
- Отсутствие информации о шрифтах: Документы могут ссылаться на шрифты, недоступные в системе извлечения.
- Варианты кодировки: Различные шрифты могут использовать несовместимые схемы кодирования символов.
- Ограничения шрифтов: Встроенные наборы символов шрифтов могут не содержать полную информацию о сопоставлении символов.
- Ошибки сопоставления Unicode: Неправильные или отсутствующие таблицы ToUnicode могут привести к неправильной интерпретации символов.
Распознавание структуры макета:
Профессиональные документы используют сложные структуры макета, что создает трудности для автоматизированных систем извлечения.
- Распознавание таблиц: Определение табличных данных и сохранение взаимосвязей между строками и столбцами.
- Структура списков: Распознавание маркированных и нумерованных списков с правильной иерархической организацией.
- Плавающие элементы: Обработка текстовых блоков, боковых панелей и сносок, которые нарушают обычный поток текста.
- Непрерывность на нескольких страницах: Сохранение контекста между страницами для абзацев и разделов.
Продвинутые методы извлечения.
Подход, основанный на многоэтапном анализе.
Сложные системы извлечения используют несколько этапов анализа, каждый из которых фокусируется на различных аспектах структуры документа:
- Этап анализа на уровне символов: Извлекаются отдельные позиции символов, шрифты и информация о кодировке.
- Этап формирования слов: Группировка символов в слова на основе интервалов и характеристик шрифта.
- Этап обнаружения строк: Определите текстовые строки с использованием анализа базовой линии и вертикальных интервалов.
- Этап сборки абзацев: Объедините строки в абзацы на основе отступов и интервалов.
- Этап анализа структуры: Обнаружение заголовков, списков, таблиц и других элементов документа.
- Этап организации контента: Организуйте элементы в логическом порядке чтения и иерархической структуре.
Улучшение с помощью машинного обучения.
Современные системы извлечения все чаще используют методы машинного обучения для повышения точности.
- Классификация макета. Обучение моделей для распознавания распространенных шаблонов макета документов.
- Предсказание порядка чтения. Использование нейронных сетей для определения оптимальной последовательности текста.
- Распознавание типа контента. Автоматическая классификация текстовых элементов как заголовков, основного текста, подписей и т.д.
- Обнаружение структуры таблиц. Продвинутые алгоритмы для сложного распознавания структуры таблиц.
Пример кода для извлечения текста.
Следующий пример демонстрирует сложность восстановления текста из команд позиционирования PDF.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
% Complex text positioning that challenges extraction BT /F0 12 Tf 1 0 0 1 72 720 Tm (This text appears) Tj 150 0 Td (out of order) Tj -150 -15 Td (in the content stream) Tj 200 0 Td (but should be) Tj -200 -15 Td (reconstructed properly) Tj 100 0 Td (by extraction algorithms.) Tj ET % Graphics elements that interrupt text flow q 1 0 0 1 100 650 cm 0.5 g 0 0 200 50 re f Q % Continuation of text after graphics BT /F0 12 Tf 1 0 0 1 72 630 Tm (Text continues after graphics elements) Tj ET |
Обеспечение качества и проверка.
Профессиональные системы извлечения данных используют несколько механизмов проверки:
- Лингвистический анализ: Проверка словаря и грамматическая проверка для выявления ошибок извлечения.
- Согласованность формата: Проверка извлеченной структуры на соответствие распространенным шаблонам документов.
- Проверка перекрестных ссылок: Обеспечение целостности внутренних ссылок в документе.
- Проверка кодировки символов: Обнаружение и исправление ошибок кодировки символов.
Оптимизация производительности и лучшие практики.
Эффективная обработка текста PDF требует внимательного учета факторов, влияющих на производительность, которые могут существенно повлиять на скорость рендеринга, использование памяти и общую отзывчивость системы. Современные приложения для работы с PDF должны обрабатывать документы, начиная от простых одностраничных файлов и заканчивая сложными публикациями, содержащими тысячи страниц.
Управление ресурсами шрифтов.
Интеллектуальные стратегии кэширования.
Загрузка и разбор шрифтов – это ресурсоемкие операции, которые значительно выигрывают от стратегического кэширования:
- Кэширование на уровне ресурсов: Кэшируйте объекты шрифтов, разобранные на уровне словаря ресурсов, чтобы избежать избыточного разбора.
- Кэш отрисовки глифов: Сохраняйте отрисованные глифы символов для повторного использования в различных операциях с текстом.
- Кэш вычислений метрик: Кэшируйте вычисления метрик шрифтов, чтобы избежать повторных вычислений.
- Кэширование между документами: Используйте общие ресурсы шрифтов для нескольких PDF-документов, когда это уместно.
Стратегии управления памятью:
Эффективное управление памятью предотвращает снижение производительности в приложениях, работающих с большим объемом текста.
- Отложенная загрузка: Загружайте ресурсы шрифтов только тогда, когда это необходимо для отображения или обработки.
- Объединение ресурсов: Поддерживайте пулы часто используемых объектов шрифтов для снижения накладных расходов на выделение памяти.
- Оптимизация сборки мусора: Реализовать интеллектуальные стратегии очистки для неиспользуемых ресурсов шрифтов.
- Отображение в память: Использовать файлы, отображаемые в память, для больших встроенных шрифтов, чтобы уменьшить использование оперативной памяти.
Оптимизация потоков текста:
Организация потоков контента:
Эффективная организация операций с текстом может значительно повысить производительность рендеринга:
- Пакетная обработка текста: Объединяйте связанные текстовые операции в отдельные блоки BT/ET, чтобы минимизировать изменения состояния.
- Минимизируйте переключение шрифтов: Организуйте контент для уменьшения операций выбора шрифта.
- Стратегическое позиционирование: Используйте относительное позиционирование (Td, TD) вместо абсолютного позиционирования (Tm), когда это уместно.
- Объединение состояний: Объединяйте совместимые изменения состояния текста в отдельные операции.
Оптимизация конвейера рендеринга.
Современные PDF-процессоры используют сложные конвейеры рендеринга:
- Многопоточность: Параллельная обработка независимых текстовых элементов.
- Ускорение на GPU: Аппаратное ускорение растеризации и композиции глифов.
- Постепенная отрисовка: Отображение текстового содержимого во время продолжения фоновой обработки.
- Отсечение области просмотра: Пропускать обработку текстовых элементов, находящихся за пределами видимой области.
Доступность и универсальный дизайн.
Создание доступных PDF-документов требует тщательного внимания к структуре текста, семантической разметке и совместимости с вспомогательными технологиями. Современные стандарты доступности требуют, чтобы PDF-документы бесперебойно работали с программами чтения с экрана, программным обеспечением для распознавания голоса и другими вспомогательными технологиями.
Структура PDF с тегами.
Структура PDF с тегами предоставляет информацию о семантической структуре, которая позволяет вспомогательным технологиям понимать организацию документа.
- Дерево логической структуры: Иерархическая организация элементов документа.
- Разметка на основе ролей. Семантическая идентификация заголовков, абзацев, списков и других элементов.
- Определение порядка чтения: Явное определение правильной последовательности чтения.
- Альтернативные описания: Текстовые альтернативы для графических элементов и сложных структур.
Поддержка интернационализации текста.
Глобальная доступность документов требует всесторонней поддержки интернационализации текста:
- Соответствие стандарту Unicode: Полная поддержка международных наборов символов и систем письма.
- Двунаправленный текст: Правильная обработка смешанного контента, читаемого слева направо и справа налево.
- Сложные скрипты: Поддержка контекстной формовки символов в арабском, индийском и других сложных системах письма.
- Поддержка вертикального текста: Традиционные китайские, японские и монгольские вертикальные макеты текста.
Будущие разработки в области типографики PDF.
Спецификация PDF продолжает развиваться, включая новые возможности, которые решают возникающие задачи в цифровых рабочих процессах, веб-интеграции и приложениях расширенной типографики.
Функции типографики нового поколения.
Технология переменных шрифтов.
Переменные шрифты представляют собой революционный шаг в цифровой типографике, позволяя одним файлам шрифтов содержать несколько вариантов дизайна:
- Вариация толщины: Плавная регулировка от тонкого до жирного начертания.
- Вариация ширины: Динамическая регулировка ширины от сжатой до расширенной.
- Оптимальный размер: Автоматическая оптимизация для различных размеров дисплея.
- Пользовательские оси: Вариации, специфичные для шрифта, такие как контраст, высота строчных букв или стилистические вариации.
Интеграция цветных шрифтов.
Продвинутые цветные шрифты обеспечивают богатые типографские возможности, которые ранее были невозможны с традиционными шрифтами.
- Встроенная графика: Шрифты, содержащие полноцветную растровую или векторную графику.
- Поддержка градиентов: Символы со сложными цветовыми переходами и эффектами.
- Многослойные шрифты: Шрифты с отдельными слоями для теней, контуров и декоративных элементов.
- Анимационная типографика: Типографические эффекты, зависящие от времени, для цифровых презентаций.
Интеграция с веб- и мобильными приложениями.
Поскольку документы PDF все чаще появляются в веб- и мобильных контекстах, новые функции направлены на создание адаптивной и отзывчивой типографики.
- Постепенная загрузка текста: Более быстрая начальная отрисовка с фоновой загрузкой шрифтов.
- Адаптивная типографика: Адаптивная перерисовка текста для различных размеров и ориентаций экрана.
- Оптимизированное взаимодействие для сенсорных устройств: Улучшенный выбор и взаимодействие с текстом для устройств с сенсорным экраном.
- Поддержка высокой плотности пикселей (DPI): Оптимизированная отрисовка для дисплеев с высоким разрешением.
Заключение.
Сложность системы обработки текста в формате PDF отражает десятилетия эволюции в области цифровой типографики и технологий документов. Каждый оператор, параметр и схема кодирования выполняют определенные функции в более широкой экосистеме профессионального создания документов. Стратегии внедрения шрифтов, системы кодирования символов, матрицы преобразований и режимы рендеринга работают вместе, создавая надежную платформу для текстовой коммуникации.
Продолжая работу с текстом и шрифтами в формате PDF, помните, что сложность спецификации служит важным целям: обеспечению долговечности документов, поддержанию визуальной точности, поддержке международного контента и обеспечению доступности. Эти фундаментальные концепции будут полезны вам, поскольку технология PDF продолжает развиваться и адаптироваться к новым вызовам в цифровой коммуникации.