Compreendendo a estrutura interna de arquivos PDF.
Bem-vindo ao fascinante mundo dos detalhes internos de arquivos PDF! Já se perguntou o que faz um arquivo PDF funcionar? Além dos documentos familiares que visualizamos diariamente, existe uma arquitetura sofisticada que revolucionou o compartilhamento de documentos digitais. Nesta exploração abrangente, vamos desvendar as camadas da estrutura de arquivos PDF, revelando os mecanismos intrincados que fazem esses arquivos onipresentes funcionarem.
🔍 Introdução: Além da Superfície
O Portable Document Format (PDF) se tornou o padrão de fato para a troca de documentos em todo o mundo. De documentos de texto simples a formulários interativos complexos, os arquivos PDF mantêm uma aparência consistente em diferentes plataformas e dispositivos. Mas o que está por trás dessa compatibilidade universal?
Nesta análise aprofundada, exploraremos a estrutura lógica que torna os arquivos PDF verdadeiramente portáteis. Examinaremos os blocos de construção fundamentais: trailer dictionary, document cataloge árvore de páginas—o trio que orquestra todas as funcionalidades de um PDF. Também vamos descobrir os segredos dos formatos de dados especializados do PDF para strings de texto e datas.
🎯 O que você aprenderá neste guia:
- Os quatro componentes fundamentais da estrutura do PDF.
- Como o PDF organiza e referencia o conteúdo de forma eficiente.
- O papel dos dicionários, catálogos e árvores de páginas.
- As abordagens únicas do PDF para codificação de texto e formatação de datas.
- Exemplos práticos de estruturas de objetos PDF.
- Melhores práticas para entender o funcionamento interno de arquivos PDF.
📋 A Anatomia de um PDF: Visão Geral.
Antes de nos aprofundarmos nos detalhes, vamos estabelecer um modelo mental da estrutura de um PDF. Pense em um PDF como um sistema de arquivos sofisticado, onde cada informação tem um lugar e um propósito específicos.
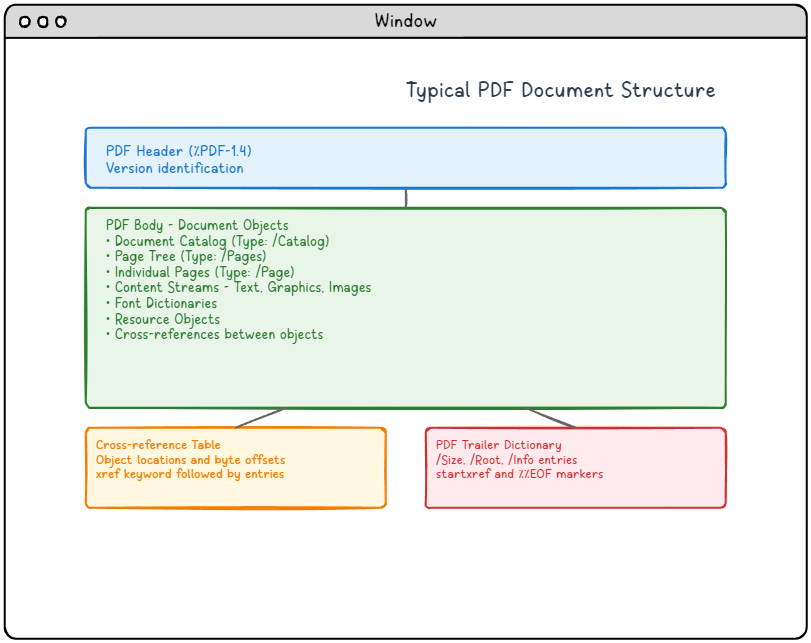
Figura 1: Estrutura típica de um documento PDF, mostrando os quatro componentes principais e suas relações.
Descrição detalhada do diagrama da estrutura do PDF:
Este diagrama ilustra a estrutura típica de um documento PDF, com quatro componentes principais dispostos verticalmente:
-
- Cabeçalho PDF (seção azul na parte superior): Contém a identificação da versão (%PDF-1.4) que especifica a versão do formato PDF.
- Corpo do PDF (seção verde no meio): A seção mais extensa, que contém todos os objetos do documento, incluindo o catálogo do documento, a árvore de páginas, as páginas individuais, os fluxos de conteúdo com texto/gráficos/imagens, os dicionários de fontes, os objetos de recursos e as referências cruzadas entre os objetos.
- Tabela de referências cruzadas (seção laranja na parte inferior esquerda): Contém as localizações dos objetos e os deslocamentos de bytes, marcados com a palavra-chave xref, seguida pelas entradas.
- Dicionário do trailer do PDF (seção vermelha na parte inferior direita): Contém informações de navegação essenciais, incluindo as entradas /Size, /Root e /Info, e termina com os marcadores startxref e %%EOF.
As setas indicam o fluxo lógico do cabeçalho para o corpo, e então ramificam para a tabela de referências cruzadas e o dicionário do rodapé, ilustrando como os leitores de PDF navegam pela estrutura do documento.
Um documento PDF consiste em quatro elementos estruturais principais que funcionam em harmonia:
🏗️ Os Quatro Pilares da Estrutura PDF:
- Cabeçalho – Identifica a versão e as capacidades do PDF.
- Corpo – Contém todos os objetos do documento (texto, imagens, fontes, etc.).
- Tabela de Referências Cruzadas. – Mapeia as localizações dos objetos para acesso rápido.
- Trailer – Fornece o ponto de entrada para navegar no documento.
Esta estrutura permite que o PDF tenha uma eficiência notável no tratamento de documentos de qualquer tamanho, desde simples cartas de uma página até manuais técnicos massivos com milhares de páginas.
🗂️ O Dicionário do Trailer: O Sistema de GPS do seu PDF.
Imagine tentar navegar em uma biblioteca sem um sistema de catálogo – o caos se instalaria! O dicionário do trailer serve como o sofisticado sistema de navegação do PDF, fornecendo o essencial mapa que os leitores de PDF usam para entender e exibir seu documento.
Localizado no final do arquivo PDF, o dicionário do trailer é paradoxalmente uma das primeiras coisas processadas ao abrir um PDF. Ele contém as informações cruciais que permitem que o software localize e interprete todos os outros componentes do documento.
🔑 Entradas Essenciais no Dicionário do Trailer.
| Key | Type | Purpose | Required? |
|---|---|---|---|
/Size |
Integer | Total entries in cross-reference table (usually objects + 1) | ✅ Yes |
/Root |
Indirect Reference | Points to the document catalog—the master control center | ✅ Yes |
/Info |
Indirect Reference | Links to document metadata (title, author, creation date) | ❌ Optional |
/ID |
Array of Strings | Unique document identifier for workflow management | ❌ Optional |
💡 Dica: Entendendo os IDs de PDF.
O /ID O array contém duas strings: a primeira é definida quando o documento é criado e nunca muda, enquanto a segunda é atualizada sempre que o documento é modificado. Este sistema de identificadores duplos permite fluxos de trabalho sofisticados de gerenciamento de documentos.
📄 Exemplo prático de dicionário de trailers:
|
1 2 3 4 5 6 |
<< /Size 421 /Root 377 0 R /Info 375 0 R /ID [<5sazn0fs3tamppia2izf569h281104ae> <6cig0wa61ti593bzuwy41905tr6s5c5a>] >> |
Este exemplo mostra um trailer para um documento com 421 objetos, onde o objeto 377 serve como o catálogo do documento e o objeto 375 contém as informações do documento.
📊 Dicionário de informações do documento: Metadados tradicionais de PDF.
O dicionário de informações do documento contém as datas de criação e modificação do arquivo, juntamente com alguns metadados simples. Este é o sistema de metadados tradicional usado em versões mais antigas de PDF, e não deve ser confundido com os metadados XMP mais abrangentes que serão discutidos em artigos futuros.
Pense neste dicionário como uma entrada básica de catálogo de biblioteca. Embora não seja essencial para exibir o documento, ele fornece informações fundamentais sobre a origem e o histórico do documento, usando strings de texto simples.
📋 Campos de informações do documento.
| Key | Data Type | Description | Example |
|---|---|---|---|
/Title |
Text String | Document title (separate from any visible title) | “Annual Report 2024” |
/Subject |
Text String | Document subject or description | “Financial Performance Analysis” |
/Keywords |
Text String | Searchable keywords | “finance, quarterly, revenue” |
/Author |
Text String | Document creator | “Jane Smith” |
/Creator |
Text String | Original application that created the document | “Microsoft Word” |
/Producer |
Text String | Application that converted to PDF | “Adobe Acrobat” |
/CreationDate |
Date String | When the document was originally created | D:20240625132712+08’00’ |
/ModDate |
Date String | Last modification timestamp | D:20240626094530+08’00’ |
⚠️ Distinção Importante
O /Creator e /Producer Os campos servem a propósitos diferentes: Creator identifica o aplicativo original de criação (como Microsoft Word), enquanto Producer identifica o software que gerou o PDF final (como Adobe Acrobat ou um driver de impressora PDF).
📋 Dicionário de Informações Completas do Documento:
|
1 2 3 4 5 6 7 8 9 10 |
<< /ModDate (D:20060926213913+02'00') /CreationDate (D:20060926213913+02'00') /Title (Product Catalog - UK Edition) /Creator (QuarkXPress: pictwpstops filter 1.0) /Producer (Acrobat Distiller 6.0 for Macintosh) /Author (James Smith) /Subject (Quarterly Product Showcase) /Keywords (products, catalog, prices, specifications) >> |
🏛️ Catálogo de Documentos: O Centro de Controle Principal
Se o dicionário do trailer é o sistema de GPS do PDF, então o catálogo de documentos é seu centro de comando central. Como o objeto raiz de todo o grafo do documento, o catálogo organiza como todos os outros objetos se relacionam entre si e como o documento se comporta quando visualizado ou impresso.
Cada objeto em um documento PDF pode ser acessado por meio de referências diretas ou indiretas, começando pelo catálogo do documento. Essa abordagem centralizada garante uma navegação eficiente e mantém a integridade do documento.
🎛️ Entradas Essenciais do Catálogo
| Key | Type | Purpose | Required? |
|---|---|---|---|
/Type |
Name | Must be /Catalog |
✅ Yes |
/Pages |
Indirect Reference | Root of the page tree structure | ✅ Yes |
/PageLabels |
Number Tree | Enables complex page numbering (i, ii, iii, 1, 2, 3) | ❌ Optional |
/Names |
Dictionary | Name trees for referencing objects by name | ❌ Optional |
/Dests |
Dictionary | Named destinations for hyperlinks | ❌ Optional |
/ViewerPreferences |
Dictionary | Controls PDF viewer behavior | ❌ Optional |
/PageMode |
Name | Default viewing mode (thumbnails, bookmarks, etc.) | ❌ Optional |
/PageLayout |
Name | Page display layout (single, facing pages, etc.) | ❌ Optional |
/Outlines |
Indirect Reference | Document bookmarks/outline structure | ❌ Optional |
/Metadata |
Indirect Reference | XMP metadata stream | ❌ Optional |
🎨 Preferências do Visualizador: Controlando a Experiência do Usuário
O /ViewerPreferences O dicionário permite que os autores de documentos influenciem a forma como os visualizadores de PDF exibem seus documentos. Isso pode incluir ocultar barras de ferramentas, ajustar as páginas às janelas ou até mesmo controlar as configurações de impressão.
📚 Opções de Modo de Página Explicadas
- /UseNone – Apenas documento, sem painéis de navegação
- /UseOutlines – Mostrar painel de marcadores
- /UseThumbs – Exibir miniaturas das páginas
- /FullScreen – Entrar no modo de apresentação
- /UseOC – Mostrar o painel de conteúdo opcional (camadas)
- /UseAttachments – Exibir o painel de anexos
🌳 Páginas e Árvores de Páginas: Organizando o Conteúdo de Forma Eficiente
Uma das decisões de design mais engenhosas do PDF é a forma como organiza as páginas. Em vez de usar uma lista linear simples, o PDF emprega uma estrutura de árvore que melhora significativamente o desempenho, especialmente para documentos grandes.
Imagine tentando encontrar uma página específica em um documento de 1000 páginas verificando cada página sequencialmente; isso pode levar até 1000 operações! A estrutura de árvore de páginas reduz isso para apenas algumas operações, tornando os visualizadores de PDF notavelmente rápidos, mesmo com documentos enormes.
🏗️ Entendendo a Estrutura do Dicionário de Páginas.
Cada página em um PDF é representada por um dicionário de página que reúne todos os elementos necessários para renderizar essa página específica: instruções de conteúdo, recursos (fontes, imagens) e especificações de layout.
| Key | Type | Purpose | Inheritance |
|---|---|---|---|
/Type |
Name | Must be /Page |
❌ |
/Parent |
Indirect Reference | Parent node in page tree | ❌ |
/Resources |
Dictionary | Fonts, images, other resources | ✅ From parent if missing |
/Contents |
Stream/Array | Page content instructions | ❌ |
/MediaBox |
Rectangle | Physical page size | ✅ From parent if missing |
/CropBox |
Rectangle | Visible page area | ✅ Defaults to MediaBox |
/Rotate |
Integer | Page rotation (0, 90, 180, 270) | ✅ From parent if missing |
📐 Entendendo os Sistemas de Coordenadas PDF.
O PDF usa um sistema de coordenadas sofisticado baseado em retângulos definidos por quatro números que representam os cantos diagonais. Entender este sistema é crucial para trabalhar com layouts de página.
📏 Exemplos de Definição de Retângulos:
|
1 2 |
/MediaBox [0 0 595 842] # A4 size in points (8.27" × 11.69") /CropBox [50 50 545 792] # A4 with 50-point margins on all sides |
💡 Unidades de Medida PDF.
O PDF usa pontos como sua unidade básica de medida, onde 1 ponto = 1/72 de polegada. Isso torna os cálculos simples: 72 pontos = 1 polegada, 144 pontos = 2 polegadas, etc.
A Arquitetura de Árvore de Páginas.
A grande vantagem da arquitetura de árvore de páginas está em sua estrutura equilibrada. Boas aplicações PDF criam árvores onde qualquer página pode ser localizada em apenas alguns passos, independentemente do tamanho do documento.
Exemplo de Arquitetura de Árvore de Páginas.
/Type /Pages
/Count 7
/Count 3
/Count 2
/Type /Page
/Type /Page
Figura 2: Estrutura de árvore de páginas para um documento de 7 páginas, mostrando uma hierarquia equilibrada para acesso eficiente.
🎯 Benefícios de desempenho da árvore de páginas:
- Tempo de acesso logarítmico – Encontre qualquer página em O(log n) operações.
- Uso eficiente da memória. – Carregue apenas as partes necessárias de documentos grandes.
- Arquitetura escalável. – O desempenho permanece consistente à medida que os documentos aumentam.
- Otimização de herança. – Propriedades comuns compartilhadas entre grupos de páginas.
📝 Estrutura do nó da árvore de páginas.
| Key | Type | Purpose |
|---|---|---|
/Type |
Name | Must be /Pages |
/Kids |
Array | References to child nodes (pages or page trees) |
/Count |
Integer | Total number of leaf pages under this node |
/Parent |
Reference | Parent node (required unless root) |
🏗️ Exemplo de implementação da árvore de páginas:
|
1 2 3 4 5 6 7 8 |
1 0 obj % Root node << /Type /Pages /Kids [2 0 R 3 0 R 4 0 R] /Count 7 >> endobj 2 0 obj % Intermediate node << /Type /Pages /Kids [5 0 R 6 0 R 7 0 R] /Parent 1 0 R /Count 3 >> endobj 5 0 obj % Actual page << /Type /Page /Parent 2 0 R /MediaBox [0 0 612 792] /Resources << >> >> endobj |
🔤 Text Strings: Manipulação de Múltiplas Codificações.
O alcance global do PDF exige robustas capacidades de manipulação de texto. O formato suporta vários esquemas de codificação para acomodar diferentes idiomas e conjuntos de caracteres, garantindo que os documentos sejam exibidos corretamente, independentemente da localização do visualizador.
Compreender a codificação de texto do PDF é crucial para qualquer pessoa que trabalhe com documentos internacionais ou desenvolva aplicativos de processamento de PDF.
📝 Dois Métodos de Codificação Primários.
1. PDFDocEncoding.
Baseado no ISO Latin-1, o PDFDocEncoding lida com a maioria dos idiomas da Europa Ocidental de forma eficiente. É a codificação padrão para strings de texto do PDF e oferece excelente compatibilidade com sistemas legados.
2. Unicode (UTF-16BE).
Para caracteres internacionais e scripts complexos, o PDF usa Unicode com codificação UTF-16BE. As strings Unicode são identificadas por um marcador de ordem de bytes (BOM) especial no início.
🔍 Detecção de strings Unicode.
Os visualizadores de PDF determinam a codificação examinando os dois primeiros bytes de uma string de texto:
|
1 2 3 4 |
If bytes[0] == 254 AND bytes[1] == 255: encoding = "UTF-16BE" # Unicode byte-order marker U+FEFF else: encoding = "PDFDocEncoding" # Default PDF encoding |
⚠️ Restrição de codificação.
Devido ao mecanismo de detecção de Unicode, as strings PDFDocEncoding não podem começar com a sequência de bytes [254, 255] (þÿ). No entanto, essa limitação raramente afeta documentos do mundo real.
📅 Formatos de data: informações temporais precisas.
O PDF utiliza um formato de data sofisticado que captura não apenas quando algo aconteceu, mas também leva em consideração os fusos horários, o que é crucial para fluxos de trabalho de documentos globais e requisitos legais.
📋 Estrutura do formato de data do PDF.
|
1 |
(D:YYYYMMDDHHmmSSOHH'mm') |
| Component | Meaning | Format | Example |
|---|---|---|---|
| YYYY | Year | Four digits | 2025 |
| MM | Month | 01-12 | 06 (June) |
| DD | Day | 01-31 | 25 |
| HH | Hour | 00-23 | 13 (1 PM) |
| mm | Minute | 00-59 | 27 |
| SS | Second | 00-59 | 12 |
| O | UTC Offset | +, -, or Z | + (later than UTC) |
| HH’ | Offset Hours | 00-23 | 08 (8 hours) |
| mm’ | Offset Minutes | 00-59 | 00 (no minutes) |
🌍 Exemplos de fusos horários.
|
1 2 3 |
(D:20250625132712+08'00') # June 25, 2024, 1:27:12 PM, UTC+8 (Beijing) (D:20250625132712-05'00') # Same moment in Eastern Standard Time (D:20250625132712Z) # Same moment in UTC (Zulu time) |
🕐 Precisão de data flexível.
As datas em PDF suportam precisão variável. Você pode especificar apenas o ano. (D:2025), ou inclua a precisão total, até segundos e fusos horários. Os componentes ausentes assumem valores padrão (01 para mês/dia, 00 para os componentes de tempo).
🧩 Juntando tudo: um exemplo completo.
Vamos examinar um exemplo completo de um arquivo PDF, criado manualmente, que demonstra todos os conceitos que discutimos. Este documento de três páginas mostra a interação entre todos os elementos estruturais do PDF.
📄 Exemplo completo da estrutura de PDF:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
%PDF-1.0 % Header 1 0 obj % Document catalog << /PageLayout /TwoColumnLeft /Pages 2 0 R /Type /Catalog >> endobj 2 0 obj % Root of page tree << /Kids [3 0 R 4 0 R] /Type /Pages /Count 3 >> endobj 3 0 obj % Page one << /Type /Page /Parent 2 0 R /MediaBox [0 0 612 792] % US Letter size /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [5 0 R] >> endobj 4 0 obj % Intermediate page tree node << /Parent 2 0 R /Kids [6 0 R 7 0 R] /Count 2 /Type /Pages >> endobj 5 0 obj % Content stream for page one << /Length 58 >> stream BT /F0 24 Tf 50 750 Td (Hello, PDF World!) Tj ET endstream endobj 6 0 obj % Page two << /Type /Page /Parent 4 0 R /MediaBox [0 0 612 792] /Rotate 90 % Landscape orientation /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [8 0 R] >> endobj 7 0 obj % Page three << /Type /Page /Parent 4 0 R /MediaBox [0 0 612 792] /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [9 0 R] >> endobj 8 0 obj % Content stream for page two << /Length 72 >> stream BT /F0 18 Tf 50 700 Td (This page is rotated 90 degrees) Tj ET endstream endobj 9 0 obj % Content stream for page three << /Length 45 >> stream BT /F0 24 Tf 50 750 Td (Final page) Tj ET endstream endobj 10 0 obj % Document information dictionary << /Title (PDF Structure Example) /Author (PDF Guide Author) /Producer (Manual Creation) /CreationDate (D:20240625132712+08'00') /ModDate (D:20240625133045+08'00') /Subject (Demonstrating PDF internal structure) /Keywords (PDF, structure, example, tutorial) >> endobj xref % Cross-reference table 0 11 0000000000 65535 f 0000000015 00000 n 0000000074 00000 n 0000000120 00000 n 0000000355 00000 n 0000000415 00000 n 0000000522 00000 n 0000000747 00000 n 0000000958 00000 n 0000001079 00000 n 0000001173 00000 n trailer % Trailer dictionary << /Size 11 /Root 1 0 R /Info 10 0 R /ID [<A1B2C3D4E5F6789012345678901234AB> <A1B2C3D4E5F6789012345678901234AB>] >> startxref 1456 %%EOF |
🗺️ Gráfico de Referência de Objetos.
/Size 11
/Root 1 0 R → Document Catalog
/Info 10 0 R → Document Info
/Type /Catalog
/Pages 2 0 R
/Title /Author
/CreationDate /ModDate
/Type /Pages
/Kids [3 0 R 4 0 R]
/Count 3
/Type /Page
/Contents [5 0 R]
/Kids [6 0 R 7 0 R]
/Count 2
/Contents [8 0 R]
/Rotate 90
/Contents [9 0 R]
Figura 3: Gráfico de referências de objetos que mostra como o dicionário do trailer se conecta a todos os componentes do documento.
🔍 Análise da Estrutura do Exemplo.
🎯 Observações Principais:
- Navegação Eficiente. – Qualquer página acessível em no máximo 2 etapas a partir da raiz.
- Herança de Recursos. – Os recursos de fonte podem ser herdados de nós pai.
- Layout flexível. – A página 2 demonstra as capacidades de rotação.
- Metadados ricos. – Informações completas do documento para gerenciamento de fluxo de trabalho.
- Identificação única. – O array de ID permite o rastreamento de documentos.
🚀 Tópicos avançados e melhores práticas.
🔧 Estratégias de otimização.
📈 Dicas de otimização de desempenho:
- Árvores balanceadas. – Mantenha tempos de acesso logarítmicos para documentos grandes.
- Compartilhamento de recursos. – Coloque recursos comuns em nós da árvore de páginas pai.
- Codificação eficiente. – Use PDFDocEncoding para texto ocidental, Unicode apenas quando necessário.
- Herança adequada. – Utilize a herança da árvore de páginas para propriedades comuns.
- Metadados mínimos. – Inclua apenas as entradas de dicionário necessárias.
🛡️ Prevenção e validação de erros.
⚠️ Armadilhas comuns a evitar:
- Referências quebradas. – Certifique-se de que todas as referências indiretas apontam para objetos válidos.
- Contagens inconsistentes. – As contagens da árvore de páginas devem refletir com precisão as páginas folha.
- Campos obrigatórios ausentes. – Sempre inclua as entradas obrigatórias no dicionário.
- Formatos de data inválidos. – Siga as especificações precisas do formato de data.
- Incompatibilidades de codificação. – Identifique corretamente as strings Unicode em relação a PDFDocEncoding.
🔮 Considerações futuras.
À medida que o PDF continua a evoluir, compreender estas estruturas fundamentais torna-se cada vez mais valioso. Recursos modernos do PDF, como assinaturas digitais, tags de acessibilidade e formulários interativos, baseiam-se na sólida base que exploramos.
🌟 Tecnologias emergentes de PDF:
- Padrões PDF/A – Formatos de arquivo para longo prazo
- Acessibilidade PDF/UA – Conformidade com a acessibilidade universal
- Formulários interativos – Conteúdo dinâmico e interação com o usuário
- Assinaturas digitais – Integridade criptográfica de documentos.
- Conteúdo 3D. – Incorporação de modelos tridimensionais.
🎯 Conclusão: Dominando a estrutura do PDF.
Compreender a estrutura interna do PDF abre portas para processamento avançado de documentos, solução de problemas e otimização. Desde as capacidades de navegação do dicionário de trailer até a organização eficiente das árvores de páginas, cada componente tem um propósito específico na criação dos documentos robustos e portáteis em que confiamos diariamente.
🏆 Principais conclusões:
- Design hierárquico. – A estrutura baseada em árvore do PDF permite uma escalabilidade eficiente.
- Navegação inteligente. – Tabelas e dicionários de referência cruzada fornecem acesso rápido.
- Codificação flexível. – Suporte a múltiplas codificações de texto para troca global de documentos.
- Metadados ricos. – Rastreamento abrangente de informações suporta fluxos de trabalho complexos.
- Modelo de herança. – O compartilhamento de recursos reduz a redundância e o tamanho do arquivo.
“A beleza do PDF reside não em sua complexidade, mas em como essa complexidade é elegantemente organizada para atender ao objetivo simples da portabilidade universal de documentos.”
Esta exploração abrangente da estrutura de PDF tem como objetivo desmistificar os aspectos técnicos de um dos formatos de documentos mais importantes do mundo. Compreender esses detalhes internos capacita desenvolvedores, gerentes de documentos e pessoas curiosas a trabalhar de forma mais eficaz com a tecnologia PDF. Recomenda-se usar bibliotecas de desenvolvimento de PDF maduras para simplificar significativamente suas tarefas de processamento de PDF.