Zrozumienie wewnętrznej struktury PDF
Witamy w fascynującym świecie elementów wewnętrznych PDF! Czy zastanawiałeś się kiedyś, co sprawia, że plik PDF działa? Poza znanymi dokumentami, które przeglądamy codziennie, kryje się wyrafinowana architektura, która zrewolucjonizowała cyfrowe udostępnianie dokumentów. W tej wszechstronnej eksploracji odsłonimy warstwy struktury PDF, odkrywając skomplikowane mechanizmy, które sprawiają, że te wszechobecne pliki działają.
🔍 Wprowadzenie: Poza powierzchnią
Przenośny format dokumentów (PDF) stał się de facto standardem wymiany dokumentów na całym świecie. Od prostych dokumentów tekstowych po złożone, interaktywne formularze — pliki PDF zachowują spójny wygląd na różnych platformach i urządzeniach. Ale co kryje się pod tą uniwersalną kompatybilnością?
Podczas tej szczegółowej analizy przyjrzymy się logicznej strukturze, która sprawia, że pliki PDF są naprawdę przenośne. Przeanalizujemy podstawowe elementy składowe: słownik zwiastunów, katalog dokumentówi drzewo stron— triumwirat, który koordynuje każdą funkcjonalność PDF. Odkryjemy także sekrety wyspecjalizowanych formatów danych PDF dla ciągów tekstowych i dat.
🎯 Czego dowiesz się z tego przewodnika:
- Cztery podstawowe elementy struktury PDF
- Jak PDF skutecznie organizuje treść i odwołuje się do niej
- Rola słowników, katalogów i drzew stron
- Unikalne podejście PDF do kodowania tekstu i formatowania daty
- Rzeczywiste przykłady struktur obiektowych PDF
- Najlepsze praktyki dotyczące zrozumienia elementów wewnętrznych PDF
📋 Anatomia PDF: Omówienie wysokiego poziomu
Zanim zagłębimy się w szczegóły, ustalmy mentalny model struktury PDF. Pomyśl o PDF jako o skomplikowanym systemie archiwizacji, w którym każda informacja ma określone miejsce i cel.
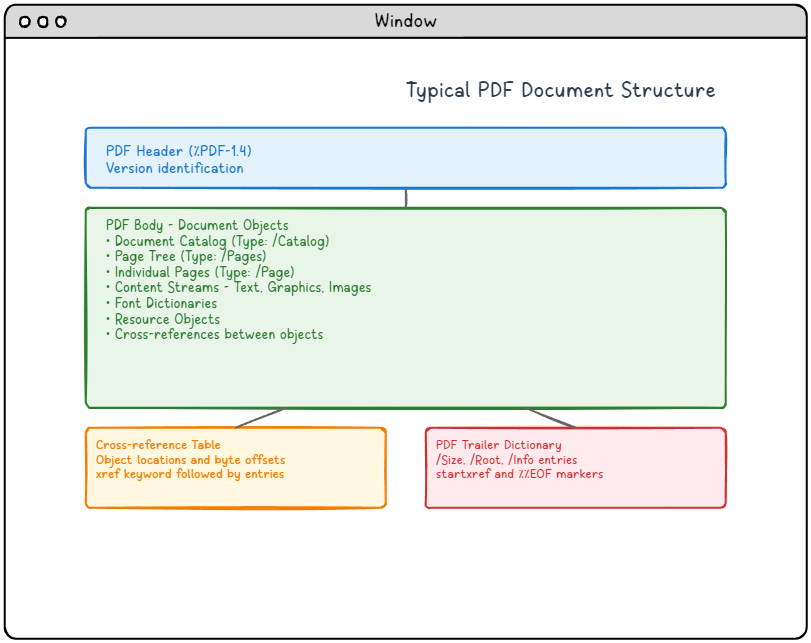
Rysunek 1: Typowa struktura dokumentu PDF przedstawiająca cztery główne elementy i ich relacje
Długi opis PDF Schemat struktury:
Ten diagram ilustruje typową strukturę dokumentu PDF z czterema głównymi elementami ułożonymi pionowo:
-
- PDF Nagłówek (niebieska sekcja u góry): Zawiera identyfikację wersji (%PDF-1.4), która określa wersję formatu PDF
- PDF Korpus (zielona część pośrodku): Największa sekcja zawierająca wszystkie obiekty dokumentu, w tym katalog dokumentów, drzewo stron, pojedyncze strony, strumienie treści z tekstem/grafiką/obrazami, słowniki czcionek, obiekty zasobów i odsyłacze między obiektami
- Tabela powiązań (sekcja pomarańczowa w lewym dolnym rogu): Zawiera lokalizacje obiektów i przesunięcia bajtów oznaczone słowem kluczowym xref, po którym następują wpisy
- PDF Słownik zwiastunów (czerwona sekcja w prawym dolnym rogu): Zawiera istotne informacje nawigacyjne, w tym wpisy /Size, /Root i /Info, a kończy się znacznikami startxref i %%EOF
Strzałki pokazują logiczny przepływ od nagłówka do treści, a następnie rozgałęzienie do tabeli odsyłaczy i słownika końcowego, ilustrując, w jaki sposób czytelnicy PDF poruszają się po strukturze dokumentu.
Dokument PDF składa się z czterech głównych elementów strukturalnych współpracujących w harmonii:
🏗️ Cztery filary struktury PDF:
- Nagłówek – Identyfikuje wersję i możliwości PDF
- Korpus – Zawiera wszystkie obiekty dokumentu (tekst, obrazy, czcionki itp.)
- Tabela powiązań – Mapuje lokalizacje obiektów w celu szybkiego dostępu
- Zwiastun – Zapewnia punkt wejścia do nawigacji po dokumencie
Ta struktura umożliwia PDF niezwykłą wydajność w obsłudze dokumentów dowolnej wielkości, od prostych jednostronicowych listów po ogromne instrukcje techniczne zawierające tysiące stron.
🗂️ Słownik zwiastunów: system GPS Twojego PDF
Wyobraź sobie, że próbujesz poruszać się po bibliotece bez systemu katalogów — nastąpiłby chaos! Słownik zwiastunów służy jako wyrafinowany system nawigacji PDF, dostarczając niezbędnego planu działania, którego czytelnicy PDF używają do zrozumienia i wyświetlenia dokumentu.
Słownik zwiastuna, znajdujący się na samym końcu pliku PDF, jest paradoksalnie jedną z pierwszych rzeczy przetwarzanych podczas otwierania pliku PDF. Zawiera kluczowe informacje, które pozwalają oprogramowaniu zlokalizować i zinterpretować wszystkie pozostałe elementy dokumentu.
🔑 Niezbędne wpisy w słowniku zwiastunów
| Wpisz | Cel | Wymagane? | |
|---|---|---|---|
/Size |
Liczba całkowita | Całkowita liczba wpisów w tabeli powiązań (zwykle obiekty + 1) | ✅Tak |
/Root |
Odniesienie pośrednie | Wskazuje katalog dokumentów — główne centrum kontroli | ✅Tak |
/Info |
Odniesienie pośrednie | Linki do metadanych dokumentu (tytuł, autor, data utworzenia) | ❌ Opcjonalnie |
/ID |
Tablica ciągów znaków | Unikalny identyfikator dokumentu do zarządzania przepływem pracy | ❌ Opcjonalnie |
💡 Wskazówka dla profesjonalistów: zrozumienie identyfikatorów PDF
/ID zawiera dwa ciągi znaków: pierwszy jest ustawiany podczas tworzenia dokumentu i nigdy się nie zmienia, natomiast drugi jest aktualizowany za każdym razem, gdy dokument jest modyfikowany. Ten system podwójnego identyfikatora umożliwia zaawansowany przepływ pracy w zakresie zarządzania dokumentami.
📄 Przykład słownika zwiastunów ze świata rzeczywistego:
Zakreślacz składni Urvanov v2.9.1|
1 2 3 4 5 6 |
<< /Size 421 /Root 377 0 R /Info 375 0 R /ID [<5sazn0fs3tamppia2izf569h281104ae> <6cig0wa61ti593bzuwy41905tr6s5c5a>] >> |
Ten przykład pokazuje zwiastun dokumentu zawierającego 421 obiektów, gdzie obiekt 377 służy jako katalog dokumentów, a obiekt 375 zawiera informacje o dokumencie.
📊 Słownik informacji o dokumencie: Tradycyjny PDF Metadane
Słownik informacji o dokumencie zawiera daty utworzenia i modyfikacji pliku wraz z kilkoma prostymi metadanymi. Jest to tradycyjny system metadanych używany w starszych wersjach PDF, którego nie należy mylić z bardziej wszechstronnymi metadanymi XMP, które zostaną omówione w przyszłych artykułach.
Pomyśl o tym słowniku jak o podstawowym wpisie w katalogu karty bibliotecznej. Chociaż nie jest to niezbędne do wyświetlenia dokumentu, dostarcza podstawowych informacji o pochodzeniu i historii dokumentu za pomocą prostych ciągów tekstowych.
📋 Pola informacji o dokumencie
| Typ danych | Opis | Przykład | |
|---|---|---|---|
/Title |
Ciąg tekstowy | Tytuł dokumentu (oddzielny od widocznego tytułu) | „Raport roczny 2024” |
/Subject |
Ciąg tekstowy | Temat lub opis dokumentu | „Analiza wyników finansowych” |
/Keywords |
Ciąg tekstowy | Wyszukiwalne słowa kluczowe | „finanse, kwartalnie, przychody” |
/Author |
Ciąg tekstowy | Kreator dokumentów | „Jane Smith” |
/Creator |
Ciąg tekstowy | Oryginalna aplikacja, która utworzyła dokument | „Microsoft Word” |
/Producer |
Ciąg tekstowy | Aplikacja przekonwertowana na PDF | „Adobe Acrobat” |
/CreationDate |
Ciąg daty | Kiedy dokument został pierwotnie utworzony | D:20240625132712+08’00’ |
/ModDate |
Ciąg daty | Znacznik czasu ostatniej modyfikacji | D:20240626094530+08’00’ |
⚠️ Ważne wyróżnienie
/Creator i /Producer służą różnym celom: Twórca identyfikuje oryginalną aplikację autorską (np. Microsoft Word), podczas gdy Producent identyfikuje oprogramowanie, które wygenerowało ostateczny PDF (np. Adobe Acrobat lub sterownik drukarki PDF).
📋 Kompletny słownik informacji o dokumencie:
Zakreślacz składni Urvanov v2.9.1|
1 2 3 4 5 6 7 8 9 10 |
<< /ModDate (D:20060926213913+02'00') /CreationDate (D:20060926213913+02'00') /Title (Product Catalog - UK Edition) /Creator (QuarkXPress: pictwpstops filter 1.0) /Producer (Acrobat Distiller 6.0 for Macintosh) /Author (James Smith) /Subject (Quarterly Product Showcase) /Keywords (products, catalog, prices, specifications) >> |
🏛️ Katalog dokumentów: Główne centrum kontroli
Jeśli słownikiem zwiastuna jest system GPS PDF, wówczas katalog dokumentów jest jego centralnym centrum dowodzenia. Jako obiekt główny całego wykresu dokumentu, katalog organizuje wzajemne powiązania wszystkich pozostałych obiektów oraz zachowanie dokumentu podczas przeglądania lub drukowania.
Do każdego obiektu w dokumencie PDF można dotrzeć poprzez bezpośrednie lub pośrednie odniesienia, zaczynając od katalogu dokumentów. To scentralizowane podejście zapewnia efektywną nawigację i zachowanie integralności dokumentów.
🎛️ Niezbędne wpisy do katalogu
| Wpisz | Cel | Wymagane? | |
|---|---|---|---|
/Type |
Nazwa | Musi być /Catalog |
✅Tak |
/Pages |
Odniesienie pośrednie | Korzeń struktury drzewa stron | ✅Tak |
/PageLabels |
Drzewo liczb | Umożliwia złożoną numerację stron (i, ii, iii, 1, 2, 3) | ❌ Opcjonalnie |
/Names |
Słownik | Drzewa nazw do odwoływania się do obiektów według nazwy | ❌ Opcjonalnie |
/Dests |
Słownik | Nazwane miejsca docelowe hiperłączy | ❌ Opcjonalnie |
/ViewerPreferences |
Słownik | Kontroluje zachowanie przeglądarki PDF | ❌ Opcjonalnie |
/PageMode |
Nazwa | Domyślny tryb przeglądania (miniatury, zakładki itp.) | ❌ Opcjonalnie |
/PageLayout |
Nazwa | Układ wyświetlania strony (pojedyncze, sąsiadujące strony itp.) | ❌ Opcjonalnie |
/Outlines |
Odniesienie pośrednie | Zakładki/struktura konspektu dokumentu | ❌ Opcjonalnie |
/Metadata |
Odniesienie pośrednie | Strumień metadanych XMP | ❌ Opcjonalnie |
🎨 Preferencje przeglądającego: kontrolowanie wrażeń użytkownika
/ViewerPreferences pozwala autorom dokumentów wpływać na sposób, w jaki przeglądarki PDF wyświetlają swoje dokumenty. Może to obejmować ukrywanie pasków narzędzi, dopasowywanie stron do okien, a nawet kontrolowanie ustawień drukowania.
📚 Wyjaśnienie opcji trybu strony
- /UseNone – Tylko dokument, bez paneli nawigacyjnych
- /UseOutlines – Pokaż panel zakładek
- /UseThumbs – Wyświetl miniatury stron
- /Pełny ekran – Wejdź w tryb prezentacji
- /Użyj OC – Pokaż opcjonalny panel treści (warstw).
- /UseAttachments – Wyświetl panel załączników
🌳 Strony i drzewa stron: efektywne organizowanie treści
Jedna z najbardziej pomysłowych decyzji projektowych firmy PDF dotyczy sposobu organizacji stron. Zamiast używać prostej listy liniowej, PDF wykorzystuje strukturę drzewa, która znacznie poprawia wydajność, szczególnie w przypadku dużych dokumentów.
Wyobraź sobie, że próbujesz znaleźć konkretną stronę w 1000-stronicowym dokumencie, sprawdzając każdą stronę po kolei — może to zająć do 1000 operacji! Struktura drzewa stron ogranicza to do zaledwie kilku operacji, dzięki czemu przeglądanie PDF jest niezwykle szybkie, nawet w przypadku dużych dokumentów.
🏗️ Zrozumienie struktury słownika strony
Każda strona w PDF jest reprezentowana przez słownik stron, który gromadzi wszystkie elementy potrzebne do wyrenderowania tej konkretnej strony: instrukcje dotyczące treści, zasoby (czcionki, obrazy) i specyfikacje układu.
| Wpisz | Cel | Dziedziczenie | |
|---|---|---|---|
/Type |
Nazwa | Musi być /Page |
❌ |
/Parent |
Odniesienie pośrednie | Węzeł nadrzędny w drzewie stron | ❌ |
/Resources |
Słownik | Czcionki, obrazy i inne zasoby | ✅ Od rodzica, jeśli zaginął |
/Contents |
Strumień/tablica | Instrukcje dotyczące zawartości strony | ❌ |
/MediaBox |
Rectangle | Fizyczny rozmiar strony | ✅ Od rodzica, jeśli zaginął |
/CropBox |
Rectangle | Widoczny obszar strony | ✅ Domyślnie MediaBox |
/Rotate |
Liczba całkowita | Rotacja strony (0, 90, 180, 270) | ✅ Od rodzica, jeśli zaginął |
📐 Zrozumienie PDF Układów współrzędnych
PDF wykorzystuje wyrafinowany układ współrzędnych oparty na prostokątach zdefiniowanych przez cztery liczby reprezentujące ukośne narożniki. Zrozumienie tego systemu ma kluczowe znaczenie przy pracy z układami stron.
📏 Rectangle Przykłady definicji:
Zakreślacz składni Urvanov v2.9.1|
1 2 |
/MediaBox [0 0 595 842] # A4 size in points (8.27" × 11.69") /CropBox [50 50 545 792] # A4 with 50-point margins on all sides |
💡 PDF Jednostki miary
PDF wykorzystuje punkty jako podstawową jednostkę miary, gdzie 1 punkt = 1/72 cala. Dzięki temu obliczenia są proste: 72 punkty = 1 cal, 144 punkty = 2 cale itd.
🌲 Architektura drzewa strony
Genialność drzewa stron leży w jego zrównoważonej strukturze. Dobre aplikacje PDF tworzą drzewa, w których w kilku krokach można zlokalizować dowolną stronę, niezależnie od rozmiaru dokumentu.
🌳 Przykład architektury drzewa strony
/Wpisz /Pages
/Liczba 7
/Liczba 3
/Liczba 2
/Wpisz /Strona
/Wpisz /Strona
Rysunek 2: Struktura drzewa stron dla 7-stronicowego dokumentu przedstawiająca zrównoważoną hierarchię zapewniającą efektywny dostęp
🎯 Korzyści z wydajności drzewa stron:
- Logarytmiczny czas dostępu – Znajdź dowolną stronę w operacjach O(log n).
- Efektywne wykorzystanie pamięci – Załaduj tylko potrzebne fragmenty dużych dokumentów
- Skalowalna architektura – Wydajność pozostaje niezmienna w miarę powiększania się dokumentów
- Optymalizacja dziedziczenia – Wspólne właściwości wspólne dla grup stron
📝 Struktura węzła drzewa strony
| Wpisz | Cel | |
|---|---|---|
/Type |
Nazwa | Musi być /Pages |
/Kids |
Tablica | Odniesienia do węzłów podrzędnych (stron lub drzew stron) |
/Count |
Liczba całkowita | Całkowita liczba stron liści w tym węźle |
/Parent |
Odniesienie | Węzeł nadrzędny (wymagany, chyba że root) |
🏗️ Przykład wdrożenia drzewa stron:
Zakreślacz składni Urvanov v2.9.1|
1 2 3 4 5 6 7 8 |
1 0 obj % Root node << /Type /Pages /Kids [2 0 R 3 0 R 4 0 R] /Count 7 >> endobj 2 0 obj % Intermediate node << /Type /Pages /Kids [5 0 R 6 0 R 7 0 R] /Parent 1 0 R /Count 3 >> endobj 5 0 obj % Actual page << /Type /Page /Parent 2 0 R /MediaBox [0 0 612 792] /Resources << >> >> endobj |
🔤 Ciągi tekstowe: obsługa wielu kodowań
Globalny zasięg PDF wymaga solidnych możliwości obsługi tekstu. Format obsługuje wiele schematów kodowania, aby dostosować się do różnych języków i zestawów znaków, zapewniając prawidłowe wyświetlanie dokumentów niezależnie od ustawień regionalnych przeglądarki.
Zrozumienie kodowania tekstu PDF jest kluczowe dla każdego, kto pracuje z dokumentami międzynarodowymi lub tworzy aplikacje przetwarzające PDF.
📝 Dwie podstawowe metody kodowania
1. Kodowanie PDFDoc
Oparte na ISO Latin-1, PDFDocEncoding skutecznie obsługuje większość języków Europy Zachodniej. Jest to domyślne kodowanie ciągów tekstowych PDF i zapewnia doskonałą kompatybilność ze starszymi systemami.
2. Unicode (UTF-16BE)
W przypadku znaków międzynarodowych i złożonych skryptów PDF używa Unicode z kodowaniem UTF-16BE. Ciągi Unicode są identyfikowane na początku za pomocą specjalnego znacznika kolejności bajtów (BOM).
🔍 Wykrywanie ciągów znaków Unicode
PDF przeglądarki określają kodowanie, sprawdzając pierwsze dwa bajty ciągu tekstowego:
|
1 2 3 4 |
If bytes[0] == 254 AND bytes[1] == 255: encoding = "UTF-16BE" # Unicode byte-order marker U+FEFF else: encoding = "PDFDocEncoding" # Default PDF encoding |
⚠️ Ograniczenie kodowania
Ze względu na mechanizm wykrywania Unicode, ciągi PDFDocEncoding nie mogą zaczynać się od sekwencji bajtów [254, 255] (þÿ). Jednak to ograniczenie rzadko dotyczy dokumentów świata rzeczywistego.
📅 Formaty dat: dokładne informacje czasowe
PDF wykorzystuje wyrafinowany format daty, który rejestruje nie tylko czas, w którym coś się wydarzyło, ale także uwzględnia strefy czasowe – kluczowe dla globalnego obiegu dokumentów i wymogów prawnych.
📋 PDF Struktura formatu daty
|
1 |
(D:YYYYMMDDHHmmSSOHH'mm') |
| Komponent | Znaczenie | Formatuj | Przykład |
|---|---|---|---|
| RRRR | Rok | Cztery cyfry | 2025 |
| MM | Miesiąc | 01-12 | 06 (czerwiec) |
| DD | Dzień | 01-31 | 25 |
| GG | Godzina | 00-23 | 13 (13:00) |
| mm | Minuta | 00-59 | 27 |
| SS | Po drugie | 00-59 | 12 |
| O | Przesunięcie czasu UTC | +, - lub Z | + (później niż UTC) |
| GG” | Przesunięcie godzin | 00-23 | 08 (8 godzin) |
| mm’ | Minuty przesunięcia | 00-59 | 00 (bez minut) |
🌍 Przykłady stref czasowych
|
1 2 3 |
(D:20250625132712+08'00') # June 25, 2024, 1:27:12 PM, UTC+8 (Beijing) (D:20250625132712-05'00') # Same moment in Eastern Standard Time (D:20250625132712Z) # Same moment in UTC (Zulu time) |
🕐 Elastyczna precyzja daty
PDF daty obsługują zmienną precyzję. Możesz podać tylko rok (D:2025)lub uwzględnij pełną precyzję aż do sekund i stref czasowych. Brakujące składniki mają domyślnie rozsądne wartości (01 dla miesiąca/dnia, 00 dla składników czasu).
🧩 Składanie wszystkiego w jedną całość: kompletny przykład
Przeanalizujmy kompletny, ręcznie wykonany przykład PDF, który demonstruje wszystkie omówione przez nas koncepcje. Ten trzystronicowy dokument przedstawia wzajemne oddziaływanie wszystkich elementów konstrukcyjnych PDF.
📄 Kompletny przykład struktury PDF:
Zakreślacz składni Urvanov v2.9.1|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
%PDF-1.0 % Header 1 0 obj % Document catalog << /PageLayout /TwoColumnLeft /Pages 2 0 R /Type /Catalog >> endobj 2 0 obj % Root of page tree << /Kids [3 0 R 4 0 R] /Type /Pages /Count 3 >> endobj 3 0 obj % Page one << /Type /Page /Parent 2 0 R /MediaBox [0 0 612 792] % US Letter size /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [5 0 R] >> endobj 4 0 obj % Intermediate page tree node << /Parent 2 0 R /Kids [6 0 R 7 0 R] /Count 2 /Type /Pages >> endobj 5 0 obj % Content stream for page one << /Length 58 >> stream BT /F0 24 Tf 50 750 Td (Hello, PDF World!) Tj ET endstream endobj 6 0 obj % Page two << /Type /Page /Parent 4 0 R /MediaBox [0 0 612 792] /Rotate 90 % Landscape orientation /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [8 0 R] >> endobj 7 0 obj % Page three << /Type /Page /Parent 4 0 R /MediaBox [0 0 612 792] /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [9 0 R] >> endobj 8 0 obj % Content stream for page two << /Length 72 >> stream BT /F0 18 Tf 50 700 Td (This page is rotated 90 degrees) Tj ET endstream endobj 9 0 obj % Content stream for page three << /Length 45 >> stream BT /F0 24 Tf 50 750 Td (Final page) Tj ET endstream endobj 10 0 obj % Document information dictionary << /Title (PDF Structure Example) /Author (PDF Guide Author) /Producer (Manual Creation) /CreationDate (D:20240625132712+08'00') /ModDate (D:20240625133045+08'00') /Subject (Demonstrating PDF internal structure) /Keywords (PDF, structure, example, tutorial) >> endobj xref % Cross-reference table 0 11 0000000000 65535 f 0000000015 00000 n 0000000074 00000 n 0000000120 00000 n 0000000355 00000 n 0000000415 00000 n 0000000522 00000 n 0000000747 00000 n 0000000958 00000 n 0000001079 00000 n 0000001173 00000 n trailer % Trailer dictionary << /Size 11 /Root 1 0 R /Info 10 0 R /ID [<A1B2C3D4E5F6789012345678901234AB> <A1B2C3D4E5F6789012345678901234AB>] >> startxref 1456 %%EOF |
🗺️ Wykres odniesienia obiektu
/Rozmiar 11
/Root 1 0 R → Katalog dokumentów
/Info 10 0 R → Informacje o dokumencie
/Wpisz /Katalog
/Strony 2 0 R
/Tytuł /Autor
/Data utworzenia /DataModu
/Wpisz /Pages
/Dzieci [3 0 R 4 0 R]
/Liczba 3
/Wpisz /Strona
/Spis treści [5 0 R]
/Dzieci [6 0 R 7 0 R]
/Liczba 2
/Spis treści [8 0 R]
/Obróć o 90
/Spis treści [9 0 R]
Rysunek 3: Wykres odniesienia obiektu pokazujący, w jaki sposób słownik zwiastuna łączy się ze wszystkimi komponentami dokumentu
🔍 Analiza przykładowej struktury
🎯 Kluczowe obserwacje:
- Wydajna nawigacja – Dowolna strona dostępna w maksymalnie 2 krokach od katalogu głównego
- Dziedziczenie zasobów – Zasoby czcionek mogą być dziedziczone z węzłów nadrzędnych
- Elastyczny układ – Strona 2 przedstawia możliwości rotacji
- Bogate metadane – Pełne informacje o dokumencie do zarządzania przepływem pracy
- Unikalna identyfikacja – tablica ID umożliwiająca śledzenie dokumentów
🚀 Zaawansowane tematy i najlepsze praktyki
🔧 Strategie optymalizacji
📈 Wskazówki dotyczące optymalizacji wydajności:
- Drzewa zrównoważone – Zachowaj logarytmiczne czasy dostępu dla dużych dokumentów
- Udostępnianie zasobów – Umieść wspólne zasoby w węzłach drzewa stron nadrzędnych
- Wydajne kodowanie – Używaj PDFDocEncoding dla tekstu zachodniego, Unicode tylko wtedy, gdy jest to konieczne
- Właściwe dziedziczenie – Wykorzystaj dziedziczenie drzewa stron dla wspólnych właściwości
- Minimalne metadane – Uwzględnij tylko niezbędne wpisy słownika informacyjnego
🛡️ Zapobieganie błędom i weryfikacja
⚠️ Typowe pułapki, których należy unikać:
- Uszkodzone odniesienia – Upewnij się, że wszystkie odniesienia pośrednie wskazują na prawidłowe obiekty
- Niespójne liczby – Liczba drzew stron musi dokładnie odzwierciedlać strony liści
- Brak wymaganych pól – Zawsze uwzględniaj obowiązkowe wpisy słownikowe
- Nieprawidłowe formaty daty – Przestrzegaj dokładnych specyfikacji formatu daty
- Niedopasowania kodowania – Prawidłowo identyfikuj ciągi znaków Unicode i PDFDocEncoding
🔮 Rozważania na przyszłość
W miarę ewolucji PDF zrozumienie tych podstawowych struktur staje się coraz cenniejsze. Nowoczesne funkcje PDF, takie jak podpisy cyfrowe, znaczniki dostępności i formularze interaktywne, opierają się na solidnych podstawach, które zbadaliśmy.
🌟 Pojawiające się technologie PDF:
- PDF/A Standardy – Długoterminowe formaty archiwalne
- PDF/UA Dostępność – Zgodność z uniwersalną dostępnością
- Formularze interaktywne – Dynamiczna treść i interakcja użytkownika
- Podpisy cyfrowe – Integralność dokumentu kryptograficznego
- Treść 3D – Osadzanie modelu trójwymiarowego
🎯 Wniosek: Opanowanie struktury PDF
Zrozumienie wewnętrznej struktury PDF otwiera drzwi do zaawansowanego przetwarzania dokumentów, rozwiązywania problemów i optymalizacji. Od możliwości nawigacyjnych słownika zwiastunów po efektywną organizację drzew stron – każdy komponent służy konkretnemu celowi w tworzeniu solidnych, przenośnych dokumentów, z których korzystamy codziennie.
🏆 Kluczowe wnioski:
- Projekt hierarchiczny – drzewiasta struktura PDF umożliwia efektywne skalowanie
- Inteligentna nawigacja – Tabele odsyłaczy i słowniki zapewniają szybki dostęp
- Elastyczne kodowanie – Wiele kodowań tekstu obsługuje globalną wymianę dokumentów
- Bogate metadane – Kompleksowe śledzenie informacji wspiera złożone przepływy pracy
- Model dziedziczenia – Udostępnianie zasobów zmniejsza redundancję i rozmiar pliku
„Piękno PDF nie leży w jego złożoności, ale w tym, jak ta złożoność jest elegancko zorganizowana, aby służyć prostemu celowi, jakim jest uniwersalna przenośność dokumentów”.
Ta wszechstronna analiza struktury PDF ma na celu wyjaśnienie technicznych aspektów jednego z najważniejszych formatów dokumentów na świecie. Zrozumienie tych elementów wewnętrznych umożliwia programistom, menedżerom dokumentów i ciekawskim umysłom efektywniejszą pracę z technologią PDF. Zaleca się stosowanie dojrzałe biblioteki programistyczne PDF , aby znacznie uprościć zadania przetwarzania PDF.