Zrozumienie PDF XML Metadane i zakładki: Przewodnik techniczny
Najważniejsze omówione tematy
📍 Miejsca docelowe
Precyzyjne znaczniki lokalizacji, które definiują określone pozycje w dokumentach PDF. Umożliwiają one dokładną nawigację po zakładkach i hiperłączach, podczas gdy konspekty dokumentów zapewniają funkcjonalność hierarchicznego spisu treści.
📄 XML Metadane
Ustrukturyzowane strumienie XML, które zapewniają kompleksowe metadane dokumentów przy użyciu standardowych formatów XMP, wykraczające poza podstawowe właściwości dokumentu i obejmujące bogate informacje opisowe.
📎 Załączniki plików
Pełna funkcja osadzania plików, która pakuje zasoby zewnętrzne bezpośrednio w dokumentach PDF, tworząc samodzielne pakiety dokumentów podobne do załączników do wiadomości e-mail.
📝 Adnotacje
Interaktywne elementy nakładki, które dodają tekst, grafikę i klikalne funkcje do stron PDF bez modyfikowania podstawowej zawartości. Zawiera hiperłącza umożliwiające płynną nawigację po dokumentach i różne narzędzia do oznaczania zwiększające interakcję czytelnika.
Zakładki i miejsca docelowe

Nawigacja w dokumencie opiera się na hierarchicznych strukturach zakładek, technicznie znanych jako zarys dokumentu. Ten zorganizowany w formie drzewa system przedstawia klikalne wpisy — zwykle tytuły rozdziałów, nagłówki sekcji i nazwy podsekcji — które umożliwiają czytelnikom szybkie przechodzenie do określonych części dokumentu. Każdy wpis zakładki łączy wyświetlany tekst z informacjami o miejscu docelowym, które dokładnie określają, dokąd łącze powinno prowadzić.
Zrozumienie miejsc docelowych
Miejsca docelowe PDF służą jako dokładne znaczniki lokalizacji w dokumencie, określające, która strona ma zostać wyświetlona, gdzie na tej stronie umieścić widok i jaki poziom powiększenia zastosować. Miejsca docelowe możesz tworzyć na dwa sposoby: zdefiniuj je bezpośrednio w tekście (czego użyjemy w naszych przykładach dla przejrzystości) lub odwołuj się do nich według nazwy za pomocą systemu nazewnictwa obejmującego cały dokument. Większość czytników PDF prezentuje zakładki w panelu nawigacyjnym obok głównej treści dokumentu.
Każde miejsce docelowe korzysta ze struktury tablicowej, w której określone elementy różnią się w zależności od pożądanego sposobu oglądania. Oto główne dostępne wzorce miejsc docelowych:
Tabela typów miejsc docelowych
Uwaga: „strona” oznacza pośrednie odniesienie do obiektu strony. Domyślnie te miejsca docelowe współpracują z granicami pola przycinania strony i wracają do pola multimediów, gdy nie zdefiniowano żadnego pola przycinania.
| Tablica | Opis |
|---|---|
| [strona /Dopasuj] | Skaluje stronę tak, aby całkowicie mieściła się w oknie przeglądarki, dostosowując proporcjonalnie szerokość i wysokość. |
| [strona /FitH top] | Pozycjonuje określone pozycje u góry koordynuj na górnej krawędzi okna podczas skalowania w poziomie, aby dopasować się do pełnej szerokości strony. |
| [strona /FitV lewa] | Wyrównuje określone w lewo koordynuj z lewą krawędzią okna podczas skalowania w pionie, aby dopasować się do pełnej wysokości strony. |
| [strona /XYZ lewy górny zoom] | Pozycjonuje współrzędne (w lewo, u góry) w lewym górnym rogu okna i stosuje określony powiększ współczynnik. Wartości null zachowują bieżące ustawienia tych parametrów. |
| [strona /FitR lewy dolny prawy górny] | Powiększa i ustawia widok tak, aby wyświetlić prostokątny obszar zdefiniowany przez w lewo, dół, prawdai u góry współrzędne. |
| [strona /FitB] | Podobny do /Fit, ale skaluje się w oparciu o rzeczywiste granice zawartości, a nie zdefiniowany obszar pola przycinania. |
| [strona /FitBH góra] | Działa jak /FitH, ale używa ramki ograniczającej zawartość zamiast ramki przycinania do obliczeń skalowania poziomego. |
| [strona /FitBV lewa] | Działa jak /FitV, ale skalowanie w pionie oblicza w oparciu o ramkę ograniczającą zawartość, a nie krawędzie ramki przycinania. |
Struktura konspektu dokumentu
Konspekty dokumentów tworzą hierarchiczną strukturę nawigacji, która działa jako interaktywny spis treści dla przeglądających PDF. Ta przypominająca drzewo organizacja pomaga użytkownikom szybko poruszać się po złożonych dokumentach, zapewniając przejrzysty przegląd struktury. System opiera się na dwóch podstawowych typach obiektów:
- Słownik konspektu – Korzeń hierarchii konspektu
- Zarys słowników elementów – Poszczególne wpisy w konspekcie
Tabela struktury słownika konspektu
| Typ wartości | Wartość | |
|---|---|---|
| /Typ | nazwa | Jeśli jest obecny, musi to być /Outlines. |
| /Najpierw | pośrednie odniesienie do słownika | Odnosi się do początkowego wpisu konspektu najwyższego poziomu w hierarchii dokumentu. To pole jest obowiązkowe, jeśli istnieją wpisy konspektu. |
| /Ostatni | pośrednie odniesienie do słownika | Odnosi się do ostatniego wpisu konspektu najwyższego poziomu w hierarchii dokumentu. To pole jest obowiązkowe, jeśli istnieją wpisy konspektu. |
| /Liczba | liczba całkowita | Określa, ile wpisów konspektu jest obecnie rozwiniętych w całym drzewie konspektu. Można pominąć, jeśli żadne wpisy nie są w stanie otwartym. |
Implementacja elementu konspektu
Każdy element konspektu składa się ze słownika, który określa jego tytuł wyświetlany, miejsce docelowe i relacje z innymi elementami w hierarchii.
Przyjrzyjmy się, jak zbudowany jest prosty konspekt dokumentu w składni PDF:
Zakreślacz składni Urvanov v2.9.1|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
8 0 obj <</Type/Outlines/Count 4/First 9 0 R/Last 9 0 R>> endobj 9 0 obj <</Title(Chapter 1: Experiment A)/Count 3/Parent 8 0 R/First 12 0 R/Last 18 0 R>> endobj 12 0 obj <</Title(1: Introduction)/Count 0/Parent 9 0 R/Next 15 0 R>> endobj 15 0 obj <</Title(2: Methodology)/Count 0/Parent 9 0 R/Prev 12 0 R/Next 18 0 R>> endobj 18 0 obj <</Title(3: Result verification)/Count 0/Parent 9 0 R/Prev 15 0 R/>> endobj |
Tabela struktury słownika pozycji konspektu
* oznacza wymagany wpis
| Typ wartości | Wartość | |
|---|---|---|
| /Tytuł* | ciąg tekstowy | Tekst, który będzie wyświetlany dla tego wpisu. |
| /Nadrzędny* | pośrednie odniesienie do słownika | Odwołuje się do elementu nadrzędnego tego elementu w hierarchii konspektu, którym może być inny element konspektu lub główny słownik konspektu. |
| /Poprzednie | pośrednie odniesienie do słownika | Odwołuje się do poprzedzającego elementu rodzeństwa na tym samym poziomie hierarchii, jeśli ma to zastosowanie. |
| /Dalej | pośrednie odniesienie do słownika | Odnosi się do następującego elementu rodzeństwa na tym samym poziomie hierarchii, jeśli ma to zastosowanie. |
| /Najpierw | pośrednie odniesienie do słownika | Odnosi się do początkowego elementu podrzędnego w ramach tego wpisu, jeśli istnieją elementy podrzędne. |
| /Ostatni | pośrednie odniesienie do słownika | Odnosi się do ostatniego elementu podrzędnego w ramach tego wpisu, jeśli istnieją elementy podrzędne. |
| /Liczba | liczba całkowita | Po rozwinięciu wpisu wskazuje liczbę widocznych wpisów potomnych. Po zwinięciu przechowuje wartość ujemną reprezentującą całkowitą liczbę ukrytych elementów podrzędnych, które staną się widoczne po rozwinięciu. |
| /Odc | nazwa, ciąg znaków lub tablica | Miejsce docelowe. Tablice są miejscami docelowymi, nazwy są odniesieniami do wpisów we wpisie /Dests w katalogu dokumentów, ciągi znaków są odniesieniami do wpisów we wpisie /Dests w słowniku nazw dokumentu. |
XML Metadane
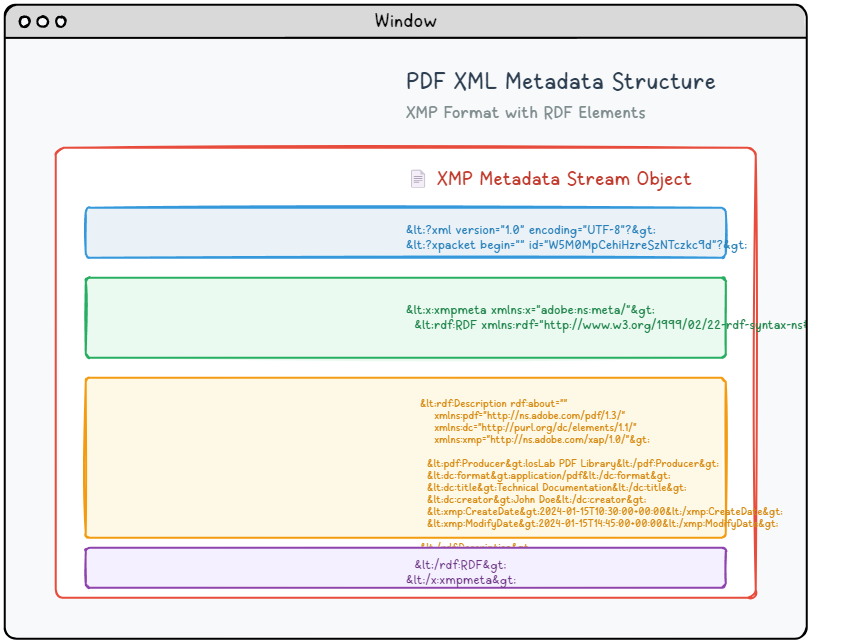
Nowoczesne dokumenty PDF mogą zawierać zaawansowane strumienie metadanych oparte na XML, które oferują znacznie bardziej szczegółowe i uporządkowane informacje niż tradycyjne właściwości dokumentów. Ten zaawansowany system metadanych wykorzystuje specyfikację Adobe XMP (Extensible Metadata Platform), aby zapewnić standardowe, czytelne maszynowo opisy dokumentów, które zwiększają możliwości wyszukiwania, organizacji i automatycznego przetwarzania.
Struktura metadanych XMP
Metadane XMP są spakowane jako dokument XML, który wykorzystuje składnię RDF (Resource Opis Framework) do organizowania i opisywania właściwości dokumentu w ustandaryzowanym formacie. Ta zawartość metadanych jest osadzona w dedykowanym obiekcie strumieniowym, który zawiera odpowiednią identyfikację typu dla procesorów PDF:
Zakreślacz składni Urvanov v2.9.1|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
6 0 obj <</Length 1235/Type/Metadata/Subtype/XML>>stream <?xpacket begin="锘xBF" id="W5M0MpCehiHzreSzNTczkc9d"?> <x:xmpmeta xmlns:x="adobe:ns:meta/" x:xmptk="Adobe XMP Core 5.2-c001 63.139439, 2010/09/27-13:37:26" ><rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" ><rdf:Description rdf:about="" xmlns:pdf="http://ns.adobe.com/pdf/1.3/" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:xmp="http://ns.adobe.com/xap/1.0/" ><pdf:Producer>losLab PDF Library</pdf:Producer> <dc:creator>losLab.com</dc:creator> <dc:title>Delphi PDF SDKs</dc:title> <xmp:CreateDate>2025-06-29T10:46:27+08:00</xmp:CreateDate> <xmp:ModifyDate>2025-06-29T10:58:57+08:00</xmp:ModifyDate> <xmp:MetadataDate>2025-06-29T10:46:27+08:00</xmp:MetadataDate> <dc:description>Delphi Development Library for PDF creation & editing</dc:description> <xmp:CreatorTool>HotPDF Component</xmp:CreatorTool> <dc:subject>PDF Developer Library for RAD Studio></dc:subject> <pdf:Keywords>Delphi, PDF SDK, PDF Component</pdf:Keywords> </rdf:Description>Robust Delphi PDF development library</rdf:RDF> </x:xmpmeta> <?xpacket end="w"?> endstream endobj |
Standardowe schematy metadanych
Struktura XMP organizuje metadane za pomocą dobrze ugruntowanych przestrzeni nazw schematów, z których każda obsługuje określone kategorie informacji:
📋 Dublin Core (dc:)
Podstawowe informacje bibliograficzne
- dc:title – Tytuł dokumentu
- dc:creator – Autor(zy) dokumentu
- dc:subject – Temat dokumentu/słowa kluczowe
- dc:description – Opis dokumentu
- dc:format – typ MIME
🏷️ XMP Podstawowy (xmp:)
Właściwości Core XMP
- xmp:CreateDate – Data utworzenia
- xmp:ModifyDate – Data modyfikacji
- xmp:CreatorTool – Tworzenie aplikacji
- xmp:MetadataDate – Data modyfikacji metadanych
📄 PDF Schemat (pdf:)
Właściwości specyficzne dla PDF
- pdf:Producent – PDF producent
- pdf:Keywords – Słowa kluczowe dokumentu
- pdf:PDFVersion – wersja PDF
Integracja z Katalogiem Dokumentów
Do strumienia metadanych XML odwołuje się katalog dokumentów:
Zakreślacz składni Urvanov v2.9.1|
1 2 3 |
1 0 obj < < Type Catalog Pages 2 0 R Metadata 10 0 R Outlines 1 0 R>> endobj |
🎯 Najlepsze praktyki dotyczące metadanych XML
- Zawsze dołączaj słownik informacji o dokumencie i metadane XMP, aby zapewnić maksymalną kompatybilność
- Upewnij się, że wartości metadanych są spójne w obu lokalizacjach
- Użyj prawidłowego kodowania XML (UTF-8) dla znaków międzynarodowych
- Uwzględnij daty utworzenia i modyfikacji w formacie ISO 8601
- Sprawdź strukturę XML, aby zapobiec błędom analizy
Załączniki plików
Załączniki plików PDF zapewniają wygodną metodę osadzania plików zewnętrznych bezpośrednio w dokumencie PDF, tworząc samodzielne pakiety zawierające wszystkie niezbędne zasoby. Załączniki te można powiązać z całym dokumentem lub powiązać z konkretnymi stronami, w zależności od potrzeb. Większość nowoczesnych przeglądarek PDF prezentuje te osadzone pliki w dedykowanym panelu załączników, co ułatwia użytkownikom dostęp, przeglądanie i zapisywanie dołączonej zawartości. Funkcja ta jest szczególnie cenna przy tworzeniu kompleksowych pakietów dokumentów, takich jak prezentacje zawierające zasoby uzupełniające czy raporty z towarzyszącymi im plikami danych.
Wbudowana struktura plików
W swej istocie plik osadzony składa się z obiektu strumieniowego zawierającego rzeczywiste dane pliku wraz z wpisem słownika strumieniowego określającym /Type /EmbeddedFile. To proste podejście pozwala na przechowywanie dowolnego typu pliku w PDF. Oto jak wygląda podstawowa struktura osadzonych plików:
|
1 2 3 4 5 6 |
8 0 obj < < Type EmbeddedFile Length 35>> stream This is a text file attachment... endstream endobj |
PDF obsługuje dwa różne podejścia do odwoływania się do osadzonych plików, z których każde służy innym przypadkom użycia: załączniki na poziomie dokumentu, które są dostępne globalnie, oraz załączniki na poziomie strony, które pojawiają się jako elementy interaktywne na określonych stronach.
Załączniki na poziomie dokumentu
W przypadku załączników obejmujących cały dokument należy dodać plik /EmbeddedFiles wpis do słownika nazw, do którego dostęp można uzyskać poprzez /Names wpis w katalogu dokumentów. Dzięki takiemu podejściu załącznik jest globalnie dostępny w całym PDF, niezależnie od tego, którą stronę aktualnie przegląda użytkownik:
|
1 2 3 4 5 6 |
9 0 obj < < Names << EmbeddedFiles << Names [ (attachment.txt) << EF << F 8 0 R>> /F (attachment.txt) /Type /Filespec >> ] >> >> /Pages 1 0 R /Type /Catalog >> endobj |
Wyjaśnienie struktury kodu
- /Nazwy – Zawiera słownik nazw dokumentu
- /EmbeddedFiles – W szczególności obsługuje osadzone nazwy plików
- (attachment.txt) – Nazwa pliku widoczna dla użytkowników
- /EF – Wbudowany słownik plików zawierający aktualne odniesienia do pliku
- /F 8 0 R – Odniesienie do osadzonego obiektu strumienia plików
- /Typ /Specyfikacja pliku – Identyfikuje ten słownik jako słownik specyfikacji pliku
Załączniki na poziomie strony
Załączniki specyficzne dla strony wymagają innego podejścia przy użyciu adnotacji załączników do plików. Są one dodawane do /Annots w słowniku strony docelowej, tworząc widoczną ikonę załącznika, z którą użytkownicy mogą wchodzić w interakcję bezpośrednio na stronie:
|
1 2 3 4 5 6 7 8 |
9 0 obj < < Type Page (Other dictionary entries as usual) Annots [ << FS << EF << F 8 0 R>> /F (attachment.txt) /Type /Filespec >> /Subtype /FileAttachment /Contents (attachment.txt) /Rect [ 18 796.88976378 45 823.88976378 ] >> ] >> endobj |
Właściwości załącznika strony
- /FS – Słownik specyfikacji pliku (taki sam jak /EF powyżej)
- /Podtyp /Załącznik pliku – Identyfikuje tę adnotację jako załącznik pliku
- /Spis treści – Tekst podpowiedzi wyświetlany po najechaniu kursorem na ikonę załącznika
- /Prost – Rectangle określenie położenia i rozmiaru ikony załącznika na stronie
Przypadki użycia załączników
📊 Pliki danych
Osadzaj arkusze kalkulacyjne, bazy danych lub pliki nieprzetworzonych danych obok raportów i analiz
🎨 Pliki źródłowe
Dołącz oryginalne pliki projektu, rysunki CAD lub edytowalne szablony
📹 Zasoby multimedialne
Dołącz prezentacje wideo, nagrania audio lub treści interaktywne
📋 Dokumenty uzupełniające
Spakuj powiązane pliki PDF, umowy lub materiały referencyjne
Adnotacje

Adnotacje PDF stanowią skuteczny sposób dodawania elementów interaktywnych i znaczników wizualnych do dokumentów bez zmiany oryginalnej zawartości strony. Te elementy nakładki poprawiają komfort czytania, umożliwiając użytkownikom wyróżnianie tekstu, dodawanie komentarzy lub tworzenie klikalnych linków. Do najbardziej przydatnych typów adnotacji należą hiperłącza, które umożliwiają płynną nawigację pomiędzy różnymi sekcjami dokumentu lub do zasobów zewnętrznych.
Struktura adnotacji
Chociaż różne typy adnotacji służą różnym celom, wszystkie mają spójną strukturę podstawową z dodawanymi w razie potrzeby właściwościami specyficznymi dla typu. Strony PDF mogą zawierać wiele adnotacji, które są zorganizowane w tablicę, do której odwołuje się wpis /Annots w słowniku każdej strony. Każda adnotacja jest implementowana jako własny obiekt słownikowy o określonych właściwościach.
Tabela struktury słownika adnotacji
* oznacza wymagany wpis
| Typ wartości | Wartość | |
|---|---|---|
| /Typ | nazwa | Jeśli jest określony, ta wartość musi być ustawiona na /Annot, aby poprawnie zidentyfikować typ słownika. |
| /Podtyp* | nazwa | Określa konkretną kategorię adnotacji (e.g., Link, Tekst, Podświetlenie). |
| /prosto* | prostokąt | Definiuje położenie i wymiary adnotacji przy użyciu standardowych jednostek współrzędnych PDF. |
| /Spis treści | ciąg tekstowy | Zawiera treść tekstową adnotacji lub zapewnia alternatywną etykietę opisową dla celów dostępności. |
Podstawowy przykład słownika adnotacji:
Zakreślacz składni Urvanov v2.9.1|
1 2 3 |
12 0 obj < < Type Annot Subtype Link Rect [100 200 300 250] Border [0 0 1] C [0.0 0.0 1.0] Dest [5 0 R XYZ null null null]>> endobj |
Typowe typy adnotacji
🔗 Adnotacje linków
Utwórz klikalne obszary prowadzące do miejsc docelowych w dokumencie lub zasobach zewnętrznych.
- /Podtyp /Link – Identyfikuje się jako adnotację łącza
- /Odc – Tablica docelowa lub nazwana tablica docelowa
- /A – Słownik akcji dla bardziej złożonych zachowań
📝 Adnotacje tekstowe
Wyświetl wyskakujące notatki i komentarze, które pojawiają się po kliknięciu.
- /Podtyp /Tekst – Identyfikuje się jako adnotację tekstową
- /Spis treści – Treść tekstowa adnotacji
- /Otwórz – Czy adnotacja jest początkowo otwarta
🖍️ Adnotacje znaczników
Zaznacz, podkreśl lub przekreśl treść tekstową.
- /Podtyp /Podświetlenie – Podświetlanie tekstu
- /Podtyp /Podkreślenie – Podkreślenie tekstu
- /Podtyp /StrikeOut – Przekreślenie tekstu
Zaawansowane działania łącza
Adnotacje linków mogą wykonywać różne działania wykraczające poza prostą nawigację:
Zakreślacz składni Urvanov v2.9.1|
1 2 3 |
13 0 obj < < Type Annot Subtype Link Rect [50 50 200 100] A << Type Action S URI URI (https: www.example.com)>> >> endobj |
Typy akcji
- /S /GoTo – Przejdź do miejsca docelowego w dokumencie
- /S /GoToR – Przejdź do miejsca docelowego w innym dokumencie
- /S /URI – Otwórz adres URL strony internetowej
- /S /Uruchom – Uruchom aplikację zewnętrzną
- /S /JavaScript – Wykonaj kod JavaScript
Wygląd adnotacji
Niestandardową stylizację wizualną adnotacji osiąga się poprzez strumienie wyglądu, co umożliwia precyzyjną kontrolę nad sposobem wyświetlania adnotacji użytkownikom:
Zakreślacz składni Urvanov v2.9.1|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
14 0 obj < < Type Annot Subtype Square Rect [100 100 200 150] C [1.0 0.0 0.0] BS << W 2 S S>> /AP < < N 15 0 R>> >> endobj 15 0 obj < < Type XObject Subtype Form BBox [0 0 100 50] Length 85>> stream q 1.0 0.0 0.0 RG 2 w 10 10 80 30 re S Q endstream endobj |
Praktyczne wytyczne dotyczące wdrożenia
Integracja struktury dokumentu
Pomyślne wdrożenie wymaga zrozumienia, jak te elementy współdziałają w ramach szerszej architektury dokumentu PDF:
Zakreślacz składni Urvanov v2.9.1|
1 2 3 4 |
1 0 obj < < Type Catalog Pages 2 0 R Outlines 3 0 R Names << EmbeddedFiles 4 0 R>> /Metadata 5 0 R >> endobj |
✅ Lista kontrolna wdrożenia
- Konfiguracja katalogu dokumentów – Zapewnij odpowiednie odniesienia do konspektów, nazw i metadanych
- Numeracja obiektów – Zachowaj spójną numerację obiektów i powiązania
- Kodowanie strumienia – Zastosuj odpowiednie filtry i kodowanie dla strumieni
- Walidacja – Zweryfikuj strukturę PDF za pomocą narzędzi walidacyjnych
- Testowanie kompatybilności – Przetestuj na różnych przeglądarkach i wersjach PDF
Typowe problemy i rozwiązania
❌ Zakładki nie są wyświetlane
Rozwiązanie: Sprawdź, czy katalog dokumentów zawiera plik /Outlines i że hierarchia zarysu jest właściwie zorganizowana i zawiera prawidłowe relacje rodzic-dziecko.
❌ Metadane nie zostały rozpoznane
Rozwiązanie: Upewnij się, że strumień metadanych XML jest prawidłowo sformatowany, używa poprawnych przestrzeni nazw i jest wymieniony w katalogu dokumentów za pomocą /Type /Metadata i /Subtype /XML.
❌ Załączniki niedostępne
Rozwiązanie: Sprawdź, czy osadzone pliki mają prawidłowe odniesienia w słowniku nazw na poziomie dokumentu lub w słowniku adnotacji na poziomie strony oraz czy słowniki specyfikacji plików mają prawidłową strukturę.
Wniosek
Opanowanie metadanych PDF i implementacja zakładek ma kluczowe znaczenie dla tworzenia profesjonalnych dokumentów, które zapewniają użytkownikom doskonałą wygodę i funkcjonalność. Te zaawansowane funkcje zapewniają:
- Ulepszona nawigacja – Dzięki dobrze zorganizowanym zakładkom i miejscom docelowym
- Bogate metadane – Umożliwia lepsze zarządzanie dokumentami i możliwość ich wyszukiwania
- Integracja plików – Łączenie powiązanych zasobów w dokumentach
- Elementy interaktywne – Tworzenie angażujących doświadczeń użytkownika za pomocą adnotacji
Prawidłowe wdrożenie tych funkcji umożliwia tworzenie dokumentów PDF, które wykraczają poza zwykły tekst i grafikę i stają się kompleksowymi, interaktywnymi zasobami, które skutecznie służą zarówno czytelnikom, jak i zautomatyzowanym systemom.
🚀 Kolejne kroki
- Przećwicz wdrażanie tych struktur w procesie tworzenia PDF
- Eksperymentuj z różnymi typami adnotacji i hierarchiami zakładek
- Przetestuj swoje implementacje w wielu przeglądarkach PDF
- Poznaj zaawansowane funkcje PDF oparte na tych podstawach