Opanowanie PDF Tekst i czcionki: Przewodnik programisty
Dokumenty PDF zrewolucjonizowały sposób udostępniania i zachowywania sformatowanego tekstu na różnych platformach i urządzeniach. Ale pod dopracowaną powierzchnią każdego PDF kryje się wyrafinowany system renderowania tekstu, który łączy zaawansowane koncepcje typograficzne z precyzyjnymi operacjami matematycznymi. Zrozumienie, w jaki sposób PDF obsługuje tekst i czcionki, ma kluczowe znaczenie dla programistów pracujących nad generowaniem dokumentów, wyodrębnianiem tekstu lub manipulowaniem PDF.
Ten obszerny przewodnik zabierze Cię w głąb świata renderowania tekstu PDF, odkrywając wszystko, od podstawowych odstępów między znakami po złożone techniki osadzania czcionek, systemy kodowania znaków i skomplikowane wyzwania związane z ekstrakcją tekstu. Niezależnie od tego, czy jesteś doświadczonym programistą, czy dopiero zaczynasz z technologiami PDF, zyskasz cenne informacje na temat tego, jak te wszechobecne dokumenty faktycznie działają pod maską.
Filozofia renderowania tekstu PDF
Kiedy firma Adobe tworzyła format Portable Document Format, stanęła przed zasadniczym wyzwaniem projektowym, które miało wpływ na sposób współczesnego renderowania miliardów dokumentów. Pytanie brzmiało: jak zrównoważyć elastyczność i spójność w świecie, w którym dokumenty muszą wyglądać identycznie w bardzo różnych systemach, od drukarek o wysokiej rozdzielczości po urządzenia mobilne.
Mogli wybrać jedno z dwóch skrajnych podejść:
- Podejście do układu dynamicznego: Przechowuj zwykły tekst z instrukcjami dotyczącymi układu, podobnie jak działa oprogramowanie do DTP, umożliwiając przepływ tekstu w czasie rzeczywistym i obliczenia formatowania podczas przeglądania
- Podejście oparte na czystej grafice: Konwertuj cały tekst na grafikę wektorową podczas tworzenia, zapewniając doskonałą spójność wizualną, ale całkowicie tracąc wszelkie znaczenie semantyczne i funkcjonalność tekstową
Zamiast tego PDF przyjmuje coś, co moglibyśmy nazwać „podejściem Złotowłosej” – wyrafinowane rozwiązanie pośrednie, które pozwala uchwycić to, co najlepsze z obu światów, unikając jednocześnie związanych z nimi pułapek. Ten hybrydowy system zachowuje podstawowe pojęcia dotyczące czcionek i znaków, jednocześnie wstępnie obliczając większość decyzji dotyczących układu podczas tworzenia dokumentu.
Strategiczne zalety podejścia PDF
Pełna kontrola układu i przewidywalność
Decyzje dotyczące formatowania na dużą skalę, takie jak podziały akapitów, odstępy między wierszami, szerokość kolumn i układ strony, są podejmowane podczas tworzenia PDF przez aplikację autorską. Oznacza to, że Twój dokument będzie wyglądał identycznie, niezależnie od tego, czy będzie oglądany na smartfonie w Tokio, wyświetlany na monitorze 4K w Dolinie Krzemowej, czy drukowany na drukarce laserowej w Nowym Jorku. Integralność układu pozostaje nienaruszona we wszystkich scenariuszach przeglądania, eliminując nieprzewidywalne problemy z ponownym przepływem, które są plagą innych formatów dokumentów.
Przewidywalna typografia na małą skalę
Operacje tekstowe na małą skalę, takie jak pozycjonowanie znaków, odstępy między wyrazami i skalowanie czcionek, są standaryzowane za pomocą obszernego zestawu dobrze zdefiniowanych operatorów. Pozwala to na precyzyjną kontrolę nad typografią przy jednoczesnym zachowaniu przewidywalnego zachowania w różnych przeglądarkach i procesorach PDF. System obsługuje zaawansowane funkcje typograficzne, takie jak kerning, ligatury i kontekstowe podstawianie znaków, zapewniając jednocześnie spójne wyniki.
Efektywne zarządzanie pamięcią masową i zasobami
Dzięki traktowaniu czcionek jako bibliotek kształtów znaków wielokrotnego użytku pliki PDF pozostają stosunkowo kompaktowe nawet w przypadku dokumentów zawierających dużo tekstu. Zamiast przechowywać indywidualny zarys wektorowy każdej litery, dokumenty odwołują się do wspólnych definicji czcionek, które można ponownie wykorzystać na wielu stronach, a nawet w wielu dokumentach. Takie podejście radykalnie zmniejsza rozmiar pliku, umożliwiając jednocześnie wyrafinowane strategie podzbioru i osadzania czcionek.
Ochrona semantyczna dla dostępności
W odróżnieniu od podejść czysto graficznych, PDF utrzymuje kluczowe powiązanie między glifami wizualnymi a leżącymi u ich podstaw kodami znaków. To zachowanie umożliwia korzystanie z podstawowych funkcji, takich jak wyszukiwanie tekstu, operacje kopiowania i wklejania, dostępność czytnika ekranu i automatyczna analiza treści. Format obsługuje mapowanie Unicode, alternatywne opisy tekstowe i oznakowane informacje o strukturze, dzięki czemu dokumenty są dostępne dla technologii wspomagających.
Kompleksowy system stanu tekstu PDF
System renderowania tekstu PDF działa poprzez wyrafinowany zbiór parametrów stanu, które współdziałają w celu kontrolowania każdego aspektu wyglądu tekstu na stronie. Pomyśl o tych parametrach jak o kompleksowym panelu sterowania, który reguluje nie tylko podstawowy wygląd, ale także zaawansowane funkcje typograficzne, obliczenia pozycjonowania i optymalizacje renderowania.
Kompletny system parametrów stanu tekstu obejmuje:
| Parametr | Operator | Opis | Wartość domyślna |
|---|---|---|---|
| Odstępy między znakami | Tc | Dodatkowa spacja między znakami | 0 |
| Odstępy między wyrazami | Tw | Dodatkowa spacja między słowami | 0 |
| Skalowanie poziome | Tz | Procent skalowania poziomego | 100 |
| Wiodący | TL | Odstępy między wierszami dla operatora T* | 0 |
| Czcionka i rozmiar | Tf | Wybór i skalowanie czcionki | Nie dotyczy |
| Tryb renderowania tekstu | Tr | Tryb wypełnienia, obrysu lub ścieżki | 0 (Wypełnienie) |
| Wzrost tekstu | Tz | Przemieszczenie tekstu w pionie | 0 |
Odstępy między znakami (operator Tc) – precyzyjna kontrola typografii
Parametr odstępów między znakami zapewnia precyzyjną kontrolę nad dodatkowym odstępem wstawianym pomiędzy każdym znakiem w ciągu tekstowym. Parametr ten jest mierzony w jednostkach przestrzeni tekstowej, które zazwyczaj stanowią 1/1000 rozmiaru czcionki, co pozwala na niezwykle precyzyjną regulację.
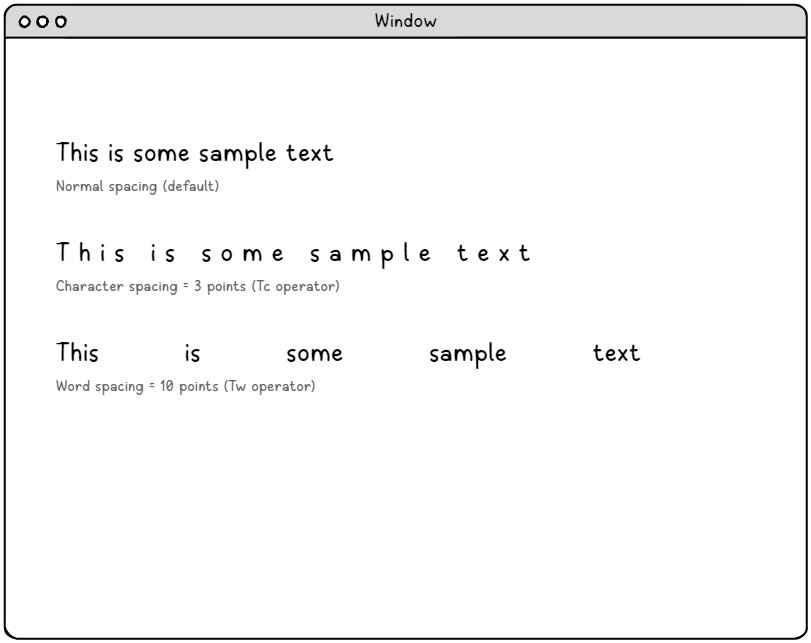
Zastosowania dotyczące odstępów między znakami obejmują:
- Udoskonalenie typografii: Tworzenie podkreśleń lub poprawa czytelności nagłówków i tekstu głównego
- Wsparcie uzasadnienia: Dostosowywanie długości linii w układach tekstu wyjustowanego
- Spójność marki: Dopasowanie określonych stylów typograficznych wymaganych przez wytyczne korporacyjne
- Dostępność: Poprawa czytelności dla użytkowników z dysleksją lub wadami wzroku
|
1 2 3 4 5 6 7 8 9 10 11 |
BT /F0 24 Tf 1 0 0 1 50 700 Tm (Normal text spacing) Tj 0 -30 Td 3 Tc (Character spacing = 3 points) Tj 0 -30 Td -1 Tc (Tight character spacing = -1 point) Tj ET |
Odstępy między słowami (operator Tw) – Inteligentne zarządzanie przestrzenią
Odstępy między wyrazami są specjalnie ukierunkowane na znak spacji (ASCII 32) w ciągu tekstowym, zapewniając ukierunkowaną kontrolę nad odstępami między wyrazami bez wpływu na inne białe znaki. Ta chirurgiczna precyzja jest nieoceniona w przypadku algorytmów justowania tekstu i tworzenia profesjonalnie wyglądających układów dokumentów.
Operator Tw demonstruje wyrafinowane podejście PDF do typografii, uznając, że różne typy odstępów służą różnym celom. Podczas gdy odstępy między znakami wpływają jednakowo na wszystkie znaki, odstępy między wyrazami wpływają tylko na rzeczywiste granice wyrazów, dając projektantom precyzyjną kontrolę nad przepływem tekstu i czytelnością.
Zakreślacz składni Urvanov v2.9.1|
1 2 3 4 5 6 7 8 9 10 11 |
BT /F0 24 Tf 1 0 0 1 50 600 Tm (Normal word spacing) Tj 0 -30 Td 10 Tw (Extended word spacing improves readability) Tj 0 -30 Td -2 Tw (Compressed word spacing saves space) Tj ET |
Skalowanie poziome (operator Tz) – kontrola typografii wymiarowej
Skalowanie poziome umożliwia rozciąganie lub kompresowanie tekstu w poziomie bez wpływu na jego wysokość, wyrażoną procentowo, gdzie 100% oznacza normalną szerokość. Ten parametr umożliwia responsywne dostosowanie typografii i specjalne efekty typograficzne, które nie byłyby możliwe przy użyciu tradycyjnych metod składu.
Zastosowania skalowania poziomego:
- Układy o ograniczonej przestrzeni: Dopasowywanie tekstu do wcześniej określonych szerokości kolumn lub elementów projektu
- Efekty stylistyczne: Tworzenie skondensowanego lub rozszerzonego tekstu dla nagłówków i wyróżnień
- Symulacja czcionki: Przybliżanie skróconych lub rozszerzonych wariantów czcionek, gdy są niedostępne
- Responsywny projekt: Dostosowywanie tekstu do różnych rozmiarów stron przy zachowaniu czytelności
Jednakże skalowanie poziome powinno być stosowane rozsądnie. Nadmierne skalowanie może pogorszyć czytelność i spowodować nienaturalny wygląd tekstu, który zakłóca czytanie. Najlepsze praktyki zalecają ograniczenie skalowania do zakresu 85–115% dla tekstu podstawowego, przy czym bardziej dramatyczne skalowanie jest zarezerwowane na potrzeby wyświetlania.
Zakreślacz składni Urvanov v2.9.1|
1 2 3 4 5 6 7 8 9 10 11 12 |
BT /F0 24 Tf 1 0 0 1 50 500 Tm 100 Tz (Normal horizontal scaling - 100%) Tj 0 -30 Td 80 Tz (Condensed text - 80% scaling) Tj 0 -30 Td 120 Tz (Extended text - 120% scaling) Tj ET |
Wiodący (operator TL) – Rytm pionowy i czytelność
Linia wiodący, wymawiana jako „ledding”, wywodzi się z tradycyjnej typografii, w której pomiędzy liniami pisma umieszczano cienkie paski ołowiu. W PDF interlinia określa odstęp w pionie pomiędzy liniami bazowymi tekstu i kontroluje stopień przesunięcia pozycji tekstu podczas korzystania z operatora T* (przejdź do następnego wiersza).
Właściwa interlinia ma kluczowe znaczenie dla ustalenia czytelnego rytmu pionowego w tekście. Zależność między rozmiarem czcionki a interlinią znacząco wpływa na czytelność, szybkość zrozumienia i ogólną estetykę dokumentu. Eksperci od typografii zazwyczaj zalecają wartości wiodące od 120% do 145% rozmiaru czcionki, aby zapewnić optymalną czytelność.
Główne rozważania:
- Zależność rozmiaru czcionki: Większe czcionki zazwyczaj wymagają proporcjonalnie większej liczby interlinii
- Wpływ długości linii: Dłuższe linie korzystają ze zwiększonego interlinii, aby pomóc czytelnikom prześledzić początek następnej linii
- Charakterystyka czcionki: Czcionki o dużych wysokościach x lub elementy dekoracyjne mogą wymagać dostosowania interlinii
- Kontekst czytania: Różne typy treści (tekst główny, podpisy, nagłówki) mają różne wymagania wiodące
|
1 2 3 4 5 6 7 8 9 10 |
BT /F0 18 Tf 18 TL 1 0 0 1 50 400 Tm (This text uses 18pt leading) Tj T* (which matches the font size) Tj T* 24 TL (This text uses 24pt leading) Tj T* (providing more generous spacing) Tj T* ET |
Wzrost tekstu (operator Ts) – Precyzja pozycjonowania pionowego
Zwiększanie tekstu umożliwia chirurgiczną regulację w pionie, umożliwiając przesuwanie tekstu w górę lub w dół od linii bazowej bez wpływu na ogólny przepływ tekstu. Parametr ten jest niezbędny przy tworzeniu profesjonalnych elementów typograficznych, które wymagają precyzyjnego ustawienia w pionie.

Aplikacje do zwiększania tekstu obejmują:
- Notacja matematyczna: Pozycjonowanie wykładników, indeksów dolnych i symboli matematycznych
- Treść naukowa: Wzory chemiczne, struktury molekularne i adnotacje naukowe
- Elementy redakcyjne: Oznaczenia przypisów, symbole znaków towarowych i informacje o prawach autorskich
- Typografia wielojęzyczna: Dostosowywanie pozycji bazowych dla różnych systemów pisma
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
BT /F0 36 Tf 1 0 0 1 140 290 Tm (H) Tj -8 Ts /F0 24 Tf (2) Tj 0 Ts /F0 36 Tf (O represents water with O) Tj 8 Ts /F0 24 Tf (2) Tj 0 Ts /F0 36 Tf ( as oxygen) Tj ET |
Zaawansowane transformacje tekstu i operacje na macierzach
Jedną z najbardziej wyrafinowanych funkcji PDF jest możliwość płynnego łączenia transformacji tekstu z transformacjami grafiki w systemie podwójnej matrycy. Ta funkcja umożliwia uzyskanie złożonych efektów układu przy jednoczesnym zachowaniu matematycznej precyzji niezbędnej do spójnego pozycjonowania tekstu w różnych warunkach oglądania.

Układ transformacji działa poprzez dwie podstawowe macierze:
Bieżąca macierz transformacji (CTM)
CTM obsługuje globalne transformacje współrzędnych, które wpływają na wszystkie elementy graficzne, w tym tekst. Zarządza operacjami takimi jak obrót, skalowanie, tłumaczenie i pochylanie na poziomie strony. Stosując transformację za pomocą operatorów takich jak cm (macierz konkatenacyjna), modyfikujesz CTM.
Matryca tekstowa (TM)
TM w szczególności obsługuje pozycjonowanie tekstu i lokalne transformacje tekstu. Działa w połączeniu z CTM, aby zapewnić prawidłowe działanie operacji pozycjonowania tekstu, takich jak łamanie wierszy, przesuwanie znaków i układ akapitów, nawet po przekształceniu całego bloku tekstu.
Sekwencja transformacji macierzy
Kiedy PDF renderuje przekształcony tekst, postępuje zgodnie z precyzyjną sekwencją matematyczną:
- Obliczanie przestrzeni glifów: Kształty poszczególnych znaków są zdefiniowane we współrzędnych przestrzeni glifów
- Transformacja przestrzeni tekstowej: Znaki są rozmieszczane w przestrzeni tekstowej przy użyciu parametrów rozmiaru czcionki i stanu tekstu
- Zastosowanie matrycy tekstowej: Macierz tekstowa przekształca współrzędne z przestrzeni tekstowej do przestrzeni użytkownika
- Zastosowanie matrycy graficznej: Bieżąca macierz transformacji stosuje ostateczne pozycjonowanie i orientację
- Konwersja przestrzeni urządzenia: Końcowe współrzędne są konwertowane na jednostki specyficzne dla urządzenia w celu renderowania
Ten wieloetapowy proces zapewnia, że przekształcenia tekstu pozostają matematycznie precyzyjne i wizualnie spójne w różnych warunkach oglądania, urządzeniach wyjściowych i współczynnikach skalowania.
Zakreślacz składni Urvanov v2.9.1|
1 2 3 4 5 6 7 8 9 10 11 |
% Set up rotation transformation 0.96 0.25 -0.25 0.96 0 0 cm BT /F0 48 Tf 48 TL % Set text matrix for positioning 1 0 0 1 270 240 Tm (Text and graphics) Tj T* (transforms combined) Tj T* (with proper newlines) Tj ET |
Praktyczne zastosowania transformacji tekstu
- Obrócone nagłówki i etykiety: Tworzenie tekstu pod kątem dla wykresów, diagramów i specjalistycznych układów
- Typografia artystyczna: Implementacja kreatywnych efektów tekstowych przy zachowaniu czytelności
- Dokumenty wieloorientacyjne: Dokumenty pomocnicze zawierające mieszane elementy pionowe i poziome
- Wyrównanie układu współrzędnych: Dopasowanie orientacji tekstu do istniejących graficznych układów współrzędnych
Kompleksowy wybór czcionek i zarządzanie zasobami
Obsługa czcionek w PDF obejmuje wyrafinowany system zarządzania zasobami, który wykracza daleko poza prosty wybór kroju pisma. System musi efektywnie zarządzać zasobami czcionek, schematami kodowania znaków, operacjami skalowania i wymaganiami dotyczącymi zgodności, zachowując jednocześnie optymalną wydajność renderowania w różnych środowiskach wyświetlania.
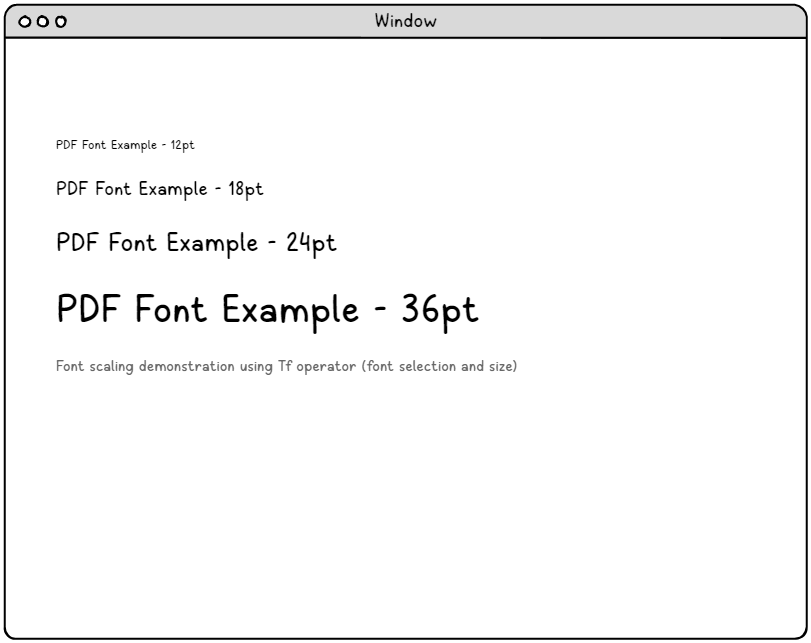
System słownika zasobów czcionek
Dokumenty PDF utrzymują hierarchiczną strukturę słownika czcionek, która odwzorowuje nazwy symboliczne na rzeczywiste zasoby czcionek. Ta warstwa pośrednia służy wielu krytycznym celom w architekturze dokumentu:
- Optymalizacja zasobów: Wiele stron i strumieni treści może współużytkować identyczne zasoby czcionek bez duplikacji
- Kontrola substytucji: Mechanizmy zastępowania czcionek można wdrożyć na poziomie zasobów bez wpływu na strumienie treści
- Zarządzanie kodowaniem: Schematy kodowania znaków można powiązać z określonymi instancjami czcionek
- Zwiększenie wydajności: Ładowanie i analizowanie czcionek można zoptymalizować dzięki inteligentnym strategiom buforowania
Typy czcionek i właściwości techniczne
Czcionki typu 1 (PostScript).
Czcionki Type 1 reprezentują oryginalną technologię skalowalnych czcionek firmy Adobe, wykorzystującą sześcienne krzywe Béziera do definiowania konturów znaków z matematyczną precyzją. Czcionki te wyróżniają się w profesjonalnych zastosowaniach wydawniczych ze względu na ich doskonałą charakterystykę skalowalności i wyrafinowane systemy podpowiedzi.
Cechy klucza typu 1:
- Sześcienne kontury Béziera: Matematycznie precyzyjne definicje krzywych, które płynnie skalują się do dowolnego rozmiaru
- Wskazówka PostScript: Inteligentna regulacja konturu zapewniająca optymalne renderowanie w małych rozmiarach
- Elastyczność kodowania: Obsługa niestandardowego kodowania znaków i specjalistycznych zestawów znaków
- Zgodność osadzania: Pełna obsługa osadzania z mechanizmami przestrzegania licencji
Czcionki TrueType
Czcionki TrueType wykorzystują kwadratowe krzywe Béziera i zawierają zaawansowane informacje podpowiedzi, zoptymalizowane specjalnie pod kątem wyświetlania na ekranie i urządzeń wyjściowych o niskiej rozdzielczości. Czcionki TrueType, pierwotnie opracowane przez firmę Apple, a później przyjęte przez firmę Microsoft, zapewniają doskonałą kompatybilność między platformami.
Zalety TrueType:
- Optymalizacja ekranu: Zaawansowane systemy podpowiedzi zoptymalizowane pod kątem wyrównania siatki pikseli
- Zgodność platformy: Szeroka obsługa różnych systemów operacyjnych i aplikacji
- Kompaktowa pamięć masowa: Efektywna reprezentacja konturu za pomocą krzywych kwadratowych
- Obsługa Unicode: Natywna obsługa dużych zestawów znaków i tekstu międzynarodowego
Czcionki OpenType
OpenType reprezentuje ewolucję typografii cyfrowej, łącząc najlepsze cechy techniczne czcionek Type 1 i TrueType, dodając jednocześnie rewolucyjne możliwości typograficzne, które zmieniają sposób renderowania profesjonalnego tekstu.
Innowacje OpenType:
- Zaawansowana typografia: Ligatury kontekstowe, znaki kaligraficzne, alternatywy i zestawy stylistyczne
- Ogromne zestawy znaków: Obsługa tysięcy znaków i wielu systemów pisma
- Inteligencja układu: Wyrafinowane zasady kontekstowego podstawiania i pozycjonowania znaków
- Spójność między platformami: Identyczne zachowanie renderowania w różnych systemach i aplikacjach
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
BT % Select font and set initial size /F0 12 Tf 1 0 0 1 50 750 Tm (12-point font example) Tj % Change to larger size, same font /F0 18 Tf 0 -25 Td (18-point font example) Tj % Even larger size /F0 24 Tf 0 -35 Td (24-point font example) Tj % Largest size /F0 36 Tf 0 -50 Td (36-point font example) Tj ET |
Profesjonalne kerning i pozycjonowanie glifów
Profesjonalna typografia wymaga precyzyjnej kontroli odstępów pomiędzy poszczególnymi znakami. Przestrzeń wizualna pomiędzy różnymi kombinacjami liter różni się znacznie w zależności od kształtów znaków, a inteligentne dostosowanie kerningu jest niezbędne do tworzenia atrakcyjnego wizualnie i bardzo czytelnego tekstu, który spełnia profesjonalne standardy wydawnicze.

Operator TJ zapewnia zaawansowane możliwości pozycjonowania glifów, które wykraczają poza prostą kontrolę odstępów między znakami i wyrazami. Zamiast pracować z monolitycznymi ciągami tekstowymi, TJ akceptuje heterogeniczną tablicę, która umożliwia kontrolę pozycjonowania na poziomie znaku z matematyczną precyzją.
Zrozumienie architektury tablicy TJ
Podejście oparte na tablicach operatora TJ rewolucjonizuje pozycjonowanie tekstu, akceptując mieszaną treść:
- Elementy ciągu: Zawiera rzeczywistą treść tekstową, która ma być renderowana przy użyciu standardowego kodowania czcionek
- Elementy numeryczne: Określ korekty poziome mierzone w tysięcznych jednostkach przestrzeni tekstowej
- Wartości ujemne: Przesuń kolejne znaki bliżej siebie, zmniejszając odstępy między znakami
- Wartości dodatnie: Zwiększ odstępy między znakami, rozszerzając układ tekstu
Ta szczegółowa kontrola umożliwia typografię profesjonalnej jakości z precyzyjną regulacją kerningu, która byłaby niemożliwa w przypadku prostszych operatorów tekstu. System umożliwia zarówno poprawę estetyki, jak i techniczne poprawki parametrów czcionek.
Zakreślacz składni Urvanov v2.9.1|
1 2 3 4 5 6 7 8 9 |
BT /F0 48 Tf 1 0 0 1 100 400 Tm % Standard text rendering (WAVE Type) Tj 0 -60 Td % Kerned text with precise adjustments [(W) -120 (A) -80 (V) -100 (E) 50 (T) -20 (y) -10 (p) -5 (e)] TJ ET |
Zaawansowane strategie kerningu
Kerning optyczny
Kerning optyczny dostosowuje odstępy między znakami w oparciu o wygląd kombinacji znaków, zamiast polegać wyłącznie na wbudowanych metrykach czcionek. Podejście to uwzględnia rzeczywiste kształty sąsiednich postaci i ich wizualną interakcję.
Kerning metryk
Kerning metryk wykorzystuje wbudowane w czcionkę tabele kerningu w celu dostosowania odstępów między określonymi parami znaków. Profesjonalne czcionki zawierają rozbudowane tabele kerningu z tysiącami korekt par znaków.
Kerning ręczny
Ręczny kerning umożliwia precyzyjne dostosowanie znak po znaku do określonych wymagań projektowych lub poprawienie problematycznych kombinacji znaków, które nie są odpowiednio rozwiązywane przez systemy automatycznego kerningu.
Praktyczne zastosowania kerningu
- Logo i marka: Precyzyjna kontrola nad typografią tożsamości korporacyjnej
- Typografia nagłówka: Optymalizacja dużego tekstu w celu uzyskania maksymalnego efektu wizualnego
- Dobra typografia: Uzyskanie układu tekstu o jakości publikacyjnej
- Wsparcie wielojęzyczne: Dostosowywanie odstępów dla różnych systemów pisma i kombinacji znaków
Tryby renderowania tekstu i efekty wizualne
PDF oferuje osiem różnych trybów renderowania tekstu, które kontrolują wygląd tekstu, zapewniając dużą elastyczność w tworzeniu różnorodnych efektów typograficznych. Tryby te określają, czy tekst jest wypełniany, obrysowywany, używany do ścieżek przycinających, czy też renderowany w sposób niewidoczny do specjalnych celów.
Pełne odniesienie do trybu renderowania tekstu
| Tryb | Nazwa | Efekt wizualny | Typowe zastosowania |
|---|---|---|---|
| 0 | Wypełnij | Tylko wypełnienie w jednolitym kolorze | Standardowy tekst podstawowy |
| 1 | Udar | Tylko kontur, bez wypełnienia | Ozdobne nagłówki |
| 2 | Wypełnienie i obrys | Zarówno wypełnienie, jak i obrys | Wyróżniony tekst |
| 3 | Niewidoczny | Brak renderowania wizualnego | Pozycjonowanie tekstu |
| 4 | Wypełnij i dodaj do ścieżki | Wypełnienie i budowa ścieżki | Wycinek tekstowy |
| 5 | Obrysuj i dodaj do ścieżki | Skok plus konstrukcja ścieżki | Złożone operacje na ścieżkach |
| 6 | Wypełnij, obrysuj i dodaj do ścieżki | Pełny tekst ze ścieżką | Zaawansowana integracja grafiki |
| 7 | Dodaj tylko do ścieżki | Budowa ścieżki, bez renderowania | Tworzenie ścieżki przycinającej |
Zaawansowane aplikacje trybu renderowania
Tryb niewidocznego tekstu (tryb 3)
Niewidoczny tekst służy kilku wyspecjalizowanym celom w dokumentach PDF:
- Pliki PDF z możliwością wyszukiwania obrazów: Nakładaj niewidoczny tekst na zeskanowane dokumenty, aby uzyskać funkcję wyszukiwania
- Pozycjonowanie tekstu: Zaawansowane pozycjonowanie tekstu bez efektów wizualnych w przypadku złożonych układów
- Poprawa dostępności: Podaj alternatywne opisy tekstowe bez rozpraszania wzroku
- Systemy szablonów: Twórz ramy pozycjonowania do dynamicznego generowania treści
Tryby konstrukcji ścieżki (tryby 4-7)
Te zaawansowane tryby umożliwiają zaawansowaną integrację systemów tekstowych i graficznych:
- Przycinanie oparte na tekście: Użyj kształtów tekstowych, aby przyciąć inne elementy graficzne
- Złożone maskowanie: Twórz skomplikowane efekty maskowania, używając kształtów znaków
- Efekty artystyczne: Łącz tekst z gradientami, wzorami i innymi elementami graficznymi
- Elementy interaktywne: Utwórz klikalne regiony, które dokładnie pasują do granic tekstu
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
BT /F0 36 Tf 1 0 0 1 100 500 Tm % Standard filled text 0 Tr (Filled Text) Tj 0 -50 Td % Stroked text only 1 Tr 2 w (Stroked Text) Tj 0 -50 Td % Both filled and stroked 2 Tr (Filled and Stroked) Tj ET |
Osadzanie czcionek i optymalizacja podzbiorów
Osadzanie czcionek stanowi jedno z najważniejszych wyzwań technicznych podczas tworzenia PDF, równoważenia przenośności dokumentów, optymalizacji rozmiaru plików i zgodności z prawem. System osadzania musi zapewniać identyczne renderowanie dokumentów w różnych systemach, przy jednoczesnym przestrzeganiu ograniczeń licencyjnych czcionek i zachowaniu rozsądnych rozmiarów plików.
Strategie osadzania czcionek
Pełne osadzanie czcionek
Pełne osadzanie czcionek obejmuje cały plik czcionki w dokumencie PDF, zapewniając doskonałą zgodność renderowania kosztem zwiększonego rozmiaru pliku. Takie podejście gwarantuje, że wszystkie znaki, informacje o kerningu i cechy typograficzne pozostaną dostępne.
Zalety:
- Pełna kompatybilność: Wszystkie funkcje czcionek pozostają dostępne niezależnie od systemu docelowego
- Wierność renderowania: Idealne odwzorowanie oryginalnej typografii i odstępów
- Zachowanie funkcji: Zaawansowane funkcje OpenType pozostają funkcjonalne
- Zabezpieczenie na przyszłość: Dokumenty pozostają czytelne nawet w przypadku zmiany dostępności czcionek
Wady:
- Wpływ na rozmiar pliku: Znaczące zwiększenie rozmiaru dokumentu, szczególnie w przypadku wielu czcionek
- Obawy dotyczące licencji: Może naruszać umowy licencyjne dotyczące czcionek, które ograniczają osadzanie
- Koszty przetwarzania: Zwiększone zużycie pamięci i czas przetwarzania podczas ładowania czcionek
Podustawienie czcionki
Podzbiór czcionek osadza tylko znaki faktycznie używane w dokumencie, radykalnie zmniejszając rozmiar pliku przy jednoczesnym zachowaniu dokładności renderowania dołączonego zestawu znaków.
Korzyści z podzestawu:
- Optymalny rozmiar pliku: Minimalny wpływ na rozmiar dokumentu przy jednoczesnym zachowaniu typografii
- Zgodność z licencjami: Mniej problemów prawnych, ponieważ uwzględnione są tylko używane znaki
- Zwiększenie wydajności: Szybsze ładowanie czcionek i mniejsze zużycie pamięci
- Wydajność przepustowości: Mniejsze dokumenty są przesyłane szybciej w sieci
Kodowanie znaków i mapowanie Unicode
System kodowania znaków PDF musi wypełnić lukę pomiędzy kodami znaków specyficznymi dla czcionki a uniwersalnymi systemami identyfikacji znaków, takimi jak Unicode. Ten proces mapowania ma kluczowe znaczenie dla funkcji wyodrębniania, wyszukiwania i ułatwień dostępu tekstu.
Mechanizmy kodujące
Wbudowane kodowanie: Wykorzystuje wewnętrzne mapowanie znaków czcionki, odpowiednie dla standardowych zachodnich zestawów znaków, ale ograniczone do treści międzynarodowych.
Standardowe kodowanie PDF: Predefiniowane schematy kodowania, takie jak WinAnsiEncoding i MacRomanEncoding, które zapewniają spójne mapowanie znaków na różnych platformach.
Kodowanie niestandardowe: Mapowania znaków specyficzne dla dokumentu, które umożliwiają obsługę znaków specjalistycznych lub starszych systemów czcionek.
Systemy Unicode (CMap): Nowoczesne podejście wykorzystujące mapy znaków (CMaps), które zapewniają bezpośrednie mapowanie pomiędzy kodami znaków i wartościami Unicode.
Do tabel mapowania Unicode
ToUnicode CMaps umożliwia dokładne wyodrębnianie i wyszukiwanie tekstu, zapewniając pomost pomiędzy kodami znaków specyficznych dla czcionki a wartościami Unicode. Te tabele mapowania są niezbędne do analizy dostępności i treści.
Zakreślacz składni Urvanov v2.9.1|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
% Example ToUnicode CMap structure 23 0 obj << /Length 317 >> stream /CIDInit /ProcSet findresource begin 12 dict begin begincmap /CIDSystemInfo << /Registry (Adobe) /Ordering (UCS) /Supplement 0 >> def /CMapName /Adobe-Identity-UCS def 1 begincodespacerange <0001> endcodespacerange 2 beginbfchar <0001> <0041> % Map glyph 1 to Unicode U+0041 (A) <0002> <0042> % Map glyph 2 to Unicode U+0042 (B) endbfchar endcmap CMapName currentdict /CMap defineresource pop end end endstream endobj |
Złożone wyzwanie związane z ekstrakcją tekstu PDF
Wyodrębnianie tekstu z dokumentów PDF stanowi jeden z najtrudniejszych technicznie aspektów przetwarzania PDF, wymagający zaawansowanych algorytmów, które mogą odtworzyć logiczną kolejność odczytu z formatu zorientowanego na grafikę. W przeciwieństwie do tradycyjnych formatów tekstowych, które zachowują strukturę semantyczną, PDF przechowuje tekst jako serię rozmieszczonych elementów graficznych, co sprawia, że wyodrębnianie jest złożonym procesem inżynierii wstecznej.
Podstawowe wyzwania związane z ekstrakcją
Niesekwencyjne pozycjonowanie tekstu
Strumienie treści PDF pozycjonują elementy tekstowe w oparciu o wymagania układu wizualnego, a nie logiczną kolejność czytania. Pojedynczy akapit może być reprezentowany przez dziesiątki oddzielnych poleceń pozycjonowania tekstu rozproszonych w strumieniu treści, zmieszanych z operacjami graficznymi i innymi elementami nietekstowymi.
Takie podejście do pozycjonowania stwarza kilka trudności w ekstrakcji:
- Rekonstrukcja kolejności odczytu: Ustalanie prawidłowej kolejności elementów tekstowych umieszczonych w niewłaściwej kolejności
- Wykrywanie kolumny: Identyfikacja układów wielokolumnowych i określanie prawidłowego przepływu kolumn
- Analiza struktury strony: Rozróżnianie nagłówków, stopek, pasków bocznych i głównych obszarów treści
- Rozdzielczość odsyłaczy: Łączenie powiązanych elementów tekstowych oddzielonych grafiką lub formatowaniem
Komplikacje dotyczące czcionek i kodowania
Ekstrakcja znaków wymaga dokładnej interpretacji schematów kodowania czcionek, które mogą znacznie się różnić w zależności od różnych czcionek i systemów tworzenia dokumentów:
- Brakujące informacje o czcionce: Dokumenty mogą odwoływać się do czcionek niedostępnych w systemie ekstrakcji
- Odmiany kodowania: Różne czcionki mogą wykorzystywać niezgodne schematy kodowania znaków
- Ograniczenia podzbioru czcionek: W podzestawach czcionek osadzonych może brakować pełnych informacji o mapowaniu znaków
- Błędy mapowania Unicode: Nieprawidłowe lub brakujące tabele ToUnicode mogą powodować błędną interpretację znaków
Rozpoznawanie struktury układu
Profesjonalne dokumenty wykorzystują złożone struktury układu, które stanowią wyzwanie dla zautomatyzowanych systemów ekstrakcji:
- Rozpoznawanie tabeli: Identyfikacja danych tabelarycznych i utrzymywanie relacji wiersz/kolumna
- Struktura listy: Rozpoznawanie list punktowanych i numerowanych z odpowiednią organizacją hierarchiczną
- Elementy pływające: Obsługa pól tekstowych, pasków bocznych i objaśnień zakłócających normalny przepływ tekstu
- Ciągłość wielu stron: Utrzymywanie kontekstu ponad granicami strony dla akapitów i sekcji
Zaawansowane metodologie ekstrakcji
Podejście do analizy wieloprzebiegowej
Wyrafinowane systemy ekstrakcji wykorzystują wiele przebiegów analizy, każdy skupiający się na różnych aspektach struktury dokumentu:
- Przepustka na poziomie postaci: Wyodrębnij poszczególne pozycje znaków, czcionki i informacje o kodowaniu
- Karta tworzenia słów: Grupuj znaki w słowa na podstawie odstępów i charakterystyki czcionki
- Przejście wykrywania linii: Identyfikuj linie tekstu za pomocą analizy linii bazowych i wzorców odstępów pionowych
- Przepustka do montażu akapitu: Łącz linie w akapity na podstawie wskazówek dotyczących wcięć i odstępów
- Zaliczenie analizy konstrukcji: Wykrywaj nagłówki, listy, tabele i inne elementy dokumentu
- Przepustka organizacji treści: Organizuj elementy w logiczną kolejność czytania i strukturę hierarchiczną
Ulepszenie uczenia maszynowego
Nowoczesne systemy ekstrakcji coraz częściej wykorzystują techniki uczenia maszynowego w celu poprawy dokładności:
- Klasyfikacja układu: Modele szkoleniowe w celu rozpoznawania typowych wzorców układu dokumentu
- Przewidywanie kolejności odczytu: Wykorzystanie sieci neuronowych do określenia optymalnej sekwencji tekstu
- Rozpoznawanie typu zawartości: Automatyczna klasyfikacja elementów tekstowych jako nagłówków, treści, podpisów itp.
- Wykrywanie struktury tabeli: Zaawansowane algorytmy rozpoznawania złożonego układu tabeli
Przykład kodu ekstrakcji tekstu
Poniższy przykład ilustruje złożoność związaną z rekonstrukcją tekstu z poleceń pozycjonowania PDF:
Zakreślacz składni Urvanov v2.9.1|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
% Complex text positioning that challenges extraction BT /F0 12 Tf 1 0 0 1 72 720 Tm (This text appears) Tj 150 0 Td (out of order) Tj -150 -15 Td (in the content stream) Tj 200 0 Td (but should be) Tj -200 -15 Td (reconstructed properly) Tj 100 0 Td (by extraction algorithms.) Tj ET % Graphics elements that interrupt text flow q 1 0 0 1 100 650 cm 0.5 g 0 0 200 50 re f Q % Continuation of text after graphics BT /F0 12 Tf 1 0 0 1 72 630 Tm (Text continues after graphics elements) Tj ET |
Zapewnienie jakości i walidacja
Profesjonalne systemy ekstrakcji wdrażają wiele mechanizmów walidacji:
- Analiza językowa: Sprawdzanie słowników i sprawdzanie gramatyki w celu identyfikacji błędów ekstrakcji
- Spójność formatu: Weryfikacja wyodrębnionej struktury pod kątem typowych wzorców dokumentów
- Walidacja odsyłaczy: Zapewnienie nienaruszenia wewnętrznych odniesień do dokumentów
- Weryfikacja kodowania znaków: Wykrywanie i korygowanie błędów kodowania znaków
Optymalizacja wydajności i najlepsze praktyki
Wydajne przetwarzanie tekstu PDF wymaga szczególnej uwagi na czynniki wydajności, które mogą znacząco wpłynąć na szybkość renderowania, zużycie pamięci i ogólną responsywność systemu. Nowoczesne aplikacje PDF muszą obsługiwać dokumenty od prostych jednostronicowych plików po złożone, wielotysięczne publikacje.
Zarządzanie zasobami czcionek
Inteligentne strategie buforowania
Ładowanie i analizowanie czcionek to kosztowne operacje, które znacząco zyskują na strategicznym buforowaniu:
- Buforowanie na poziomie zasobów: Buforuj przeanalizowane obiekty czcionek na poziomie słownika zasobów, aby uniknąć zbędnego analizowania
- Pamięć podręczna renderowania glifów: Przechowuj renderowane glify znaków w celu ponownego użycia w wielu operacjach tekstowych
- Pamięć podręczna obliczeń metryk: Buforuj obliczenia metryk czcionek, aby uniknąć powtarzających się obliczeń
- Buforowanie między dokumentami: W razie potrzeby udostępniaj zasoby czcionek w wielu dokumentach PDF
Strategie zarządzania pamięcią
Efektywne zarządzanie pamięcią zapobiega spadkowi wydajności w aplikacjach wymagających dużej ilości tekstu:
- Leniwe ładowanie: Ładuj zasoby czcionek tylko wtedy, gdy są potrzebne do renderowania lub przetwarzania
- Łączenie zasobów: Utrzymuj pule powszechnie używanych obiektów czcionek, aby zmniejszyć obciążenie związane z alokacją
- Optymalizacja zbierania śmieci: Wdróż inteligentne strategie czyszczenia nieużywanych zasobów czcionek
- Mapowanie pamięci: Użyj plików mapowanych w pamięci dla dużych osadzonych czcionek, aby zmniejszyć zużycie pamięci RAM
Optymalizacja strumienia tekstu
Organizacja strumienia treści
Efektywne organizowanie operacji tekstowych może radykalnie poprawić wydajność renderowania:
- Operacje tekstowe wsadowe: Grupuj powiązane operacje tekstowe w obrębie pojedynczych bloków BT/ET, aby zminimalizować zmiany stanu
- Minimalizuj przełączanie czcionek: Organizuj zawartość, aby ograniczyć liczbę operacji wyboru czcionki
- Pozycjonowanie strategiczne: Jeśli to konieczne, użyj pozycjonowania względnego (Td, TD) zamiast pozycjonowania bezwzględnego (Tm)
- Konsolidacja stanu: Połącz kompatybilne zmiany stanu tekstu w pojedyncze operacje
Optymalizacja potoku renderowania
Nowoczesne procesory PDF wykorzystują wyrafinowane potoki renderowania:
- Wielowątkowość: Równoległe przetwarzanie niezależnych elementów tekstowych
- Przyspieszenie GPU: Przyspieszona sprzętowo rasteryzacja i kompozycja glifów
- Renderowanie progresywne: Wyświetlaj treść tekstową, gdy przetwarzanie w tle jest kontynuowane
- Usuwanie rzutni: Pomiń przetwarzanie elementów tekstowych poza widocznym obszarem
Dostępność i uniwersalny design
Tworzenie dostępnych dokumentów PDF wymaga szczególnej uwagi na strukturę tekstu, znaczniki semantyczne i zgodność z technologiami pomocniczymi. Nowoczesne standardy dostępności wymagają, aby dokumenty PDF bezproblemowo współpracowały z czytnikami ekranu, oprogramowaniem do rozpoznawania głosu i innymi technologiami wspomagającymi.
Oznaczono PDF Struktura
Oznaczone PDF dostarcza informacji o strukturze semantycznej, które umożliwiają technologiom wspomagającym zrozumienie organizacji dokumentów:
- Drzewo struktury logicznej: Hierarchiczna organizacja elementów dokumentu
- Tagowanie oparte na rolach: Semantyczna identyfikacja nagłówków, akapitów, list i innych elementów
- Specyfikacja kolejności odczytu: Jasna definicja prawidłowej sekwencji odczytu
- Alternatywne opisy: Alternatywy tekstowe dla elementów graficznych i złożonych struktur
Międzynarodowa obsługa tekstów
Globalna dostępność dokumentów wymaga kompleksowej obsługi tekstów międzynarodowych:
- Zgodność z Unicode: Pełna obsługa międzynarodowych zestawów znaków i systemów pisma
- Tekst dwukierunkowy: Prawidłowa obsługa mieszanej treści pisanej od lewej do prawej i od prawej do lewej
- Skrypty złożone: Obsługa kontekstowego kształtowania znaków w języku arabskim, indyjskim i innych złożonych systemach pisma
- Obsługa tekstu pionowego: Tradycyjny chiński, japoński i mongolski pionowy układ tekstu
Przyszły rozwój typografii PDF
Specyfikacja PDF stale ewoluuje, włączając nowe możliwości, które spełniają pojawiające się wymagania w zakresie obiegu dokumentów cyfrowych, integracji z Internetem i zaawansowanych aplikacji typograficznych.
Funkcje typograficzne nowej generacji
Technologia zmiennej czcionki
Czcionki zmienne reprezentują rewolucyjny postęp w typografii cyfrowej, umożliwiając pojedyncze pliki czcionek zawierające wiele odmian projektu:
- Zmiana masy: Ciągła regulacja od cienkich do odważnych ciężarów
- Zmiana szerokości: Dynamika skondensowana do rozszerzonej regulacji szerokości
- Rozmiar optyczny: Automatyczna optymalizacja dla różnych rozmiarów wyświetlaczy
- Osie niestandardowe: Różnice specyficzne dla czcionki, takie jak kontrast, wysokość x lub różnice stylistyczne
Integracja kolorowych czcionek
Zaawansowane kolorowe czcionki umożliwiają bogatą ekspresję typograficzną, niemożliwą wcześniej w przypadku tradycyjnych czcionek:
- Wbudowana grafika: Czcionki zawierające pełnokolorową bitmapę lub grafikę wektorową
- Obsługa gradientu: Postacie ze złożonymi przejściami kolorów i efektami
- Czcionki wielowarstwowe: Czcionki z oddzielnymi warstwami dla cieni, konturów i elementów dekoracyjnych
- Animowana typografia: Efekty typograficzne oparte na czasie do prezentacji cyfrowych
Integracja z Internetem i urządzeniami mobilnymi
Ponieważ dokumenty PDF coraz częściej pojawiają się w kontekście internetowym i mobilnym, nowe funkcje skupiają się na responsywnej i adaptacyjnej typografii:
- Progresywne ładowanie tekstu: Szybsze wyświetlanie początkowe przy ładowaniu czcionek w tle
- Typografia responsywna: Adaptacyjne ponowne wlanie tekstu dla różnych rozmiarów i orientacji ekranu
- Interakcja zoptymalizowana pod kątem dotyku: Ulepszony wybór tekstu i interakcja dla urządzeń z ekranem dotykowym
- Obsługa wysokiej rozdzielczości: Zoptymalizowane renderowanie dla wyświetlaczy o wysokiej rozdzielczości
Wniosek
Zaawansowanie systemu tekstowego PDF odzwierciedla dziesięciolecia ewolucji cyfrowej typografii i technologii dokumentów. Każdy operator, parametr i schemat kodowania służy konkretnym celom w szerszym ekosystemie profesjonalnej produkcji dokumentów. Strategie osadzania czcionek, systemy kodowania znaków, macierze transformacji i tryby renderowania współpracują ze sobą, tworząc solidną platformę do komunikacji tekstowej.
Kontynuując pracę z tekstem i czcionkami PDF, pamiętaj, że złożoność specyfikacji służy ważnym celom: zapewnieniu trwałości dokumentu, utrzymaniu wierności wizualnej, obsłudze treści międzynarodowych i umożliwieniu dostępności. Te podstawowe koncepcje będą Ci dobrze służyć, ponieważ technologia PDF stale ewoluuje i dostosowuje się do nowych wyzwań w komunikacji cyfrowej.