Tekst pisany od prawej do lewej w generacji PDF: Przedstawiamy funkcję RtLTextOut HotPDF
Wprowadzenie do języków pisanych od prawej do lewej
Języki pisane od prawej do lewej (RTL) stanowią znaczną część światowych systemów komunikacji pisanej, obsługując ponad 400 milionów ludzi na całym świecie. Języki te obejmują arabski, hebrajski, perski (farsi), urdu, paszto i kilka innych, każdy z własnymi unikalnymi cechami i znaczeniem kulturowym.
Kontekst historyczny i kulturowy
RTL systemy pisma mają starożytne korzenie sięgające tysięcy lat. Na przykład język arabski wyewoluował z pisma nabatejskiego i ujednolicił się we wczesnym okresie islamu. Język hebrajski ma jeszcze dłuższą historię, a starożytne inskrypcje hebrajskie pochodzą z X wieku p.n.e. Te systemy pisma rozwinęły się niezależnie od alfabetów łacińskich i odzwierciedlają różne podejścia do organizowania informacji pisanych.
Charakterystyka językowa języków RTL
Języki RTL posiadają kilka charakterystycznych cech, które wpływają na cyfrowe przetwarzanie tekstu:
- Kierunek skryptu: Tekst przepływa od prawej do lewej, w przeciwieństwie do języków europejskich
- Kontekstowe formularze listów: Wiele skryptów RTL używa różnych kształtów liter w zależności od pozycji (początkowa, środkowa, końcowa, izolowana)
- Ligatury i połączenia: Litery często łączą się, tworząc ciągłe słowa, co wymaga wyrafinowanego renderowania
- Znaki diakrytyczne: Znaki samogłosek i inne znaki diakrytyczne pojawiają się nad lub pod znakami podstawowymi
- Tekst dwukierunkowy: RTL dokumenty często zawierają osadzone elementy LTR (cyfry, tekst łaciński, adresy URL)
Cyfrowe wyzwania i standardy Unicode
Cyfrowa reprezentacja języków RTL stwarza wyjątkowe wyzwania techniczne:
- Kodowanie znaków: Unicode zapewnia standardowe punkty kodowe dla znaków RTL:
- Arabski: U+0600-U+06FF (blok arabski)
- Hebrajski: U+0590-U+05FF (blok hebrajski)
- Dodatek arabski: U+0750-U+077F
- Arabski rozszerzony-A: U+08A0-U+08FF
- Algorytm dwukierunkowy: Algorytm dwukierunkowy Unicode (UBA) definiuje, w jaki sposób powinien być przetwarzany mieszany tekst RTL/LTR
- Wymagania dotyczące czcionek: Tekst RTL wymaga czcionek z odpowiednim pokryciem glifów i możliwościami kształtowania
- Uwagi dotyczące układu: Interfejsy użytkownika i dokumenty muszą uwzględniać wzorce czytania od prawej do lewej
Znaczenie rynku globalnego
Obsługa języków RTL jest kluczowa dla firm i organizacji działających na różnorodnych rynkach:
- Regiony arabskojęzyczne: 22 kraje z ponad 300 milionami rodzimych użytkowników języka
- Rynek hebrajski: Izrael i społeczności żydowskie na całym świecie
- Perski/Farsi: Iran, Afganistan i Tadżykistan
- Urdu: Pakistan i części Indii
- Wpływ ekonomiczny: Łączny PKB regionów językowych RTL przekracza 4 biliony dolarów
W dzisiejszym zglobalizowanym świecie tworzenie dokumentów PDF, które prawidłowo obsługują wiele języków i systemów pisma, staje się coraz ważniejsze. Podczas gdy większość bibliotek generacji PDF z łatwością obsługuje języki pisane od lewej do prawej (LTR), takie jak angielski, francuski i niemiecki, obsługa języków pisanych od prawej do lewej (RTL), takich jak arabski i hebrajski, stwarza wyjątkowe wyzwania. W tym artykule omówiono innowacje RtLTextOut działa w komponencie HotPDF Delphi i demonstruje jego praktyczną implementację poprzez kompleksową aplikację demonstracyjną.
Zrozumienie wyzwania związanego z tekstem RTL w plikach PDF
Języki pisane od prawej do lewej wymagają specjalnego traktowania w dokumentach cyfrowych z kilku powodów:
- Kolejność znaków: RTL tekst przepływa od prawej do lewej, w przeciwieństwie do języków LTR
- Tekst dwukierunkowy: Dokumenty często zawierają mieszaną zawartość RTL i LTR
- PDF Zachowanie przeglądarki: PDF czytelnicy potrzebują odpowiednich wskazówek dotyczących kierunku, aby poprawnie wyświetlać tekst
- Złożoność Unicode: Znaki RTL mają określone zakresy Unicode, które muszą zostać wykryte i przetworzone
Tradycyjne metody generowania PDF często zawodzą w przypadku tekstu RTL, co skutkuje odwróconymi sekwencjami znaków, nieprawidłową kolejnością odczytu lub całkowicie zniekształconym wyjściem.
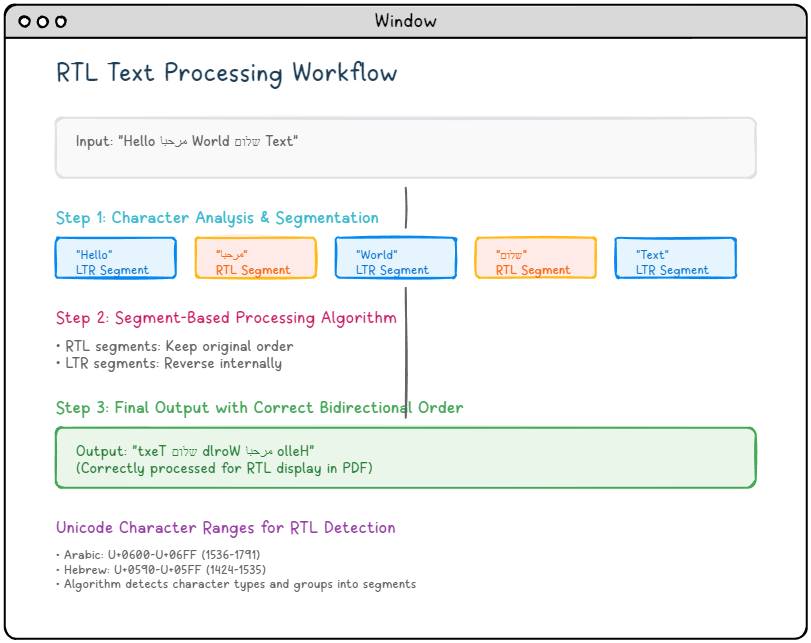
RTL Schemat koncepcyjny przetwarzania tekstu
Przedstawiamy funkcję RtLTextOut HotPDF
Komponent HotPDF pozwala sprostać tym wyzwaniom dzięki swojej wyrafinowanej konstrukcji RtLTextOut , która implementuje zaawansowane algorytmy dwukierunkowego przetwarzania tekstu. W przeciwieństwie do prostych podejść do odwracania znaków, RtLTextOut wykorzystuje przetwarzanie oparte na segmentach, aby inteligentnie obsługiwać mieszaną zawartość RTL/LTR.
Podpisy funkcji
RtLTextOut zapewnia dwie przeciążone wersje dla maksymalnej elastyczności:
|
1 2 3 4 5 |
// PWORD version for direct Unicode character array access procedure RtLTextOut(X, Y: Single; angle: Extended; Text: PWORD; TextLength: Integer); // WideString version for convenient string handling procedure RtLTextOut(X, Y: Single; angle: Extended; Text: WideString); |
Algorytm podstawowy: przetwarzanie oparte na segmentach
Serce RtLTextOut opiera się na dwukierunkowym algorytmie opartym na segmentach. Zamiast stosować ogólne odwrócenie znaku, funkcja:
- Analizuje typy znaków: Identyfikuje znaki RTL (arabski: U+0600-U+06FF, hebrajski: U+0590-U+05FF)
- Segmenty tekstu: Grupuje kolejne znaki tego samego typu (RTL lub LTR)
- Stosuje przetwarzanie selektywne:
- Segmenty RTL zachowują pierwotną kolejność
- Segmenty LTR są wewnętrznie odwrócone
- Generuje prawidłowe dane wyjściowe: Wyniki we wzorcu
Reversed(C)+B+Reversed(A)dla segmentówA+B+C
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
// Core segment processing logic I := 0; while I < TextLength do begin // Determine if current character starts an RTL or LTR segment IsRTLChar := ((ReversedText[I] >= $0600) and (ReversedText[I] <= $06FF)) or // Arabic ((ReversedText[I] >= $0590) and (ReversedText[I] <= $05FF)); // Hebrew CurrentSegmentIsRTL := IsRTLChar; SegmentStart := I; // Find the end of current segment (same character type) while (I < TextLength) do begin IsRTLChar := ((ReversedText[I] >= $0600) and (ReversedText[I] <= $06FF)) or ((ReversedText[I] >= $0590) and (ReversedText[I] <= $05FF)); if IsRTLChar <> CurrentSegmentIsRTL then Break; Inc(I); end; SegmentEnd := I - 1; // Process the segment if CurrentSegmentIsRTL then begin // RTL segment: keep original order for J := SegmentStart to SegmentEnd do OutputText[J] := ReversedText[J]; end else begin // LTR segment: reverse the segment internally for J := SegmentStart to SegmentEnd do OutputText[J] := ReversedText[SegmentEnd - (J - SegmentStart)]; end; end; |
Automatyczna konfiguracja kierunku PDF
Poza przetwarzaniem tekstu, RtLTextOut automatycznie konfiguruje dokument PDF w celu optymalnego wyświetlania RTL:
|
1 2 3 4 5 |
// Store original direction and set to RightToLeft OriginalDirection := FParent.FDirection; FParent.FDirection := RightToLeft; FParent.FViewerPreference := FParent.FViewerPreference + [vpDirection]; FParent.FVPChanged := true; |
Dzięki temu osoby przeglądające PDF otwierają dokument we właściwym kierunku czytania, zapewniając użytkownikom intuicyjne czytanie.
Odkrywanie aplikacji demonstracyjnej RtLTextOut
Biblioteka HotPDF zawiera kompleksową aplikację demonstracyjną (Demo\Delphi\RtLTextOut\RtLTextOut.dpr), który prezentuje RtLTextOut możliwości funkcji w różnych scenariuszach.
Struktura demonstracyjna i funkcje
Aplikacja demonstracyjna demonstruje:
- Podstawowe wyjście tekstu arabskiego: Proste renderowanie tekstu RTL
- Obsługa tekstu w języku hebrajskim: Kompleksowa obsługa znaków hebrajskich
- Treść w różnych językach: Kombinacje tekstu RTL/LTR
- Dokumentacja techniczna: Uwagi dotyczące wdrożenia i najlepsze praktyki
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
program RtLTextOut; {$I ..\..\..\Lib\HotPDF.inc} {$APPTYPE CONSOLE} uses {$IFDEF XE2+} System.SysUtils, Vcl.Graphics, {$ELSE} SysUtils, Graphics, {$ENDIF} HPDFDoc; var HotPDF: THotPDF; begin try HotPDF := THotPDF.Create(nil); try HotPDF.FileName := 'RtLTextOut.pdf'; HotPDF.Title := 'RtLTextOut Function Test - Right-to-Left Text Output'; HotPDF.BeginDoc; // Title HotPDF.CurrentPage.SetFont('Arial', [fsBold], 18, 0, False); HotPDF.CurrentPage.TextOut(40, 50, 0, 'RtLTextOut Function Demonstration'); // Arabic text demonstration HotPDF.CurrentPage.SetFont('Arial Unicode MS', [], 12, 178, False); HotPDF.CurrentPage.TextOut(40, 160, 0, 'RtLTextOut:'); HotPDF.CurrentPage.RtLTextOut(40, 180, 0, 'يوضح ملف PDF هذا كيفية التعامل بشكل صحيح مع النص العربي من اليمين إلى اليسار.'); // Hebrew text demonstration HotPDF.CurrentPage.SetFont('Arial Unicode MS', [], 12, 177, False); HotPDF.CurrentPage.RtLTextOut(40, 370, 0, 'קובץ PDF זה מדגים כיצד לטפל כראוי בטקסט עברי הזורם מימין לשמאל.'); // Mixed text demonstration HotPDF.CurrentPage.RtLTextOut(40, 550, 0, 'مرحبا بالعالم! اكتب في مستندات PDF التي تم إنشاؤها بواسطة مكون HotPDF'); HotPDF.EndDoc; Writeln('RtLTextOut.pdf created successfully!'); finally HotPDF.Free; end; except on E: Exception do Writeln('Error: ', E.Message); end; end. |
Najważniejsze informacje demonstracyjne
Przetwarzanie tekstu arabskiego: Demo pokazuje, jak to zrobić RtLTextOut obsługuje złożone zdania arabskie z właściwym przepływem znaków i odstępami.
Obsługa języka hebrajskiego: Pokazuje renderowanie tekstu hebrajskiego z prawidłową orientacją od prawej do lewej.
Treść w różnych językach: Pokazuje, jak funkcja inteligentnie przetwarza tekst zawierający elementy RTL i LTR.
Konfiguracja czcionki: Ilustruje prawidłowy wybór czcionki Unicode (Arial Unicode MS) dla obsługi znaków RTL.
Szczegóły techniczne implementacji
Wykrywanie znaków Unicode
Funkcja wykorzystuje niezawodne wykrywanie zakresu Unicode:
- Arabski: U+0600 do U+06FF (1536-1791 dziesiętny)
- Hebrajski: U+0590 do U+05FF (1424-1535 dziesiętne)
Zarządzanie pamięcią
Wydajna obsługa macierzy zapewnia optymalną wydajność:
Zakreślacz składni Urvanov v2.9.1|
1 2 3 4 5 6 7 8 9 10 |
// Initialize arrays SetLength(ReversedText, TextLength); SetLength(OutputText, TextLength); // Copy original text first for I := 0 to TextLength - 1 do begin ReversedText[I] := TempText^; Inc(TempText); end; |
Obsługa tekstu pionowego
Funkcja obejmuje specjalistyczną obsługę czcionek pionowych:
Zakreślacz składni Urvanov v2.9.1|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
if CurrentFontObj.IsVertical then begin DeltaH := TextHeight('Zj'); DeltaW := TextWidth('W'); HorizontalLine := Y; ChBuff := @ChCode; for I := 0 to TextLength - 1 do begin ChCode := OutputText[I]; if (ChCode = $30FC) then ChCode := $7C; InternUnicodeTextOut(X + (DeltaW / 2), HorizontalLine - DeltaH, 0, ChBuff, 1); HorizontalLine := HorizontalLine + DeltaH; end; end else InternUnicodeTextOut(X, Y, angle, @OutputText[0], TextLength); |
Najlepsze praktyki dotyczące RTL tekstu w plikach PDF
Wybór czcionki
Wybierz czcionki obsługujące Unicode, które obsługują docelowe języki RTL:
- Arial Unicode MS: Kompleksowa obsługa Unicode
- Times New Roman: Odpowiedni do treści mieszanych
- Tahoma: Doskonała obsługa języka arabskiego
Kodowanie tekstu
Upewnij się, że tekst źródłowy ma prawidłowe kodowanie Unicode:
Zakreślacz składni Urvanov v2.9.1|
1 2 3 4 5 6 7 |
// Use WideString for Unicode text var ArabicText: WideString; begin ArabicText := 'النص العربي'; HotPDF.CurrentPage.RtLTextOut(X, Y, 0, ArabicText); end; |
PDF Zgodność przeglądarki
Automatyczne ustawienie kierunku zapewnia kompatybilność między przeglądarkami PDF:
- Adobe Acrobat Reader
- Czytnik Foxit
- Przeglądarka Chrome PDF
- Przeglądarka Firefox PDF
Względy wydajności
Algorytm oparty na segmentach zapewnia doskonałą charakterystykę wydajności:
- Liniowa złożoność czasu: Czas przetwarzania O(n).
- Minimalne obciążenie pamięci: Efektywne zarządzanie macierzami
- Przetwarzanie jednoprzebiegowe: Nie są wymagane wielokrotne iteracje
- Zoptymalizowane wykrywanie znaków: Szybkie sprawdzanie zakresu Unicode
Aplikacje w świecie rzeczywistym
Lokalizacja dokumentów
RtLTextOut umożliwia bezproblemową lokalizację dokumentów dla rynków RTL:
- Dokumenty prawne w języku arabskim
- Instrukcje techniczne w języku hebrajskim
- Wielojęzyczne formularze i umowy
- Materiały edukacyjne
Biznes międzynarodowy
Firmy działające na rynkach językowych RTL mogą wykorzystać tę funkcjonalność do:
- Generowanie faktury
- Tworzenie raportu
- Drukowanie certyfikatu
- Materiały marketingowe
Rozwiązywanie typowych problemów
Problemy z kodowaniem znaków
Problem: Zniekształcone lub brakujące znaki
Rozwiązanie: Zapewnij prawidłowe kodowanie Unicode i wybór czcionki
|
1 2 3 4 5 |
// Correct approach HotPDF.CurrentPage.SetFont('Arial Unicode MS', [], 12, 178, False); var Text: WideString := 'النص العربي'; HotPDF.CurrentPage.RtLTextOut(X, Y, 0, Text); |
Problemy z kierunkiem
Problem: Tekst pojawia się w złym kierunku
Rozwiązanie: Sprawdź to RtLTextOut jest używany zamiast zwykłego TextOut
Problemy z mieszaną zawartością
Problem: Nieprawidłowa kolejność w mieszanym tekście RTL/LTR
Rozwiązanie: Algorytm oparty na segmentach obsługuje to automatycznie
Przyszłe ulepszenia i plan działania
Zespół programistów HotPDF stale ulepsza obsługę RTL:
- Rozszerzona obsługa języków: Dodatkowe języki RTL
- Złożona obsługa skryptów: Zaawansowane funkcje typograficzne
- Optymalizacja wydajności: Dalsze ulepszenia prędkości
- Ulepszone debugowanie: Lepsze narzędzia diagnostyczne
Słowa końcowe
RtLTextOut w HotPDF reprezentuje znaczący postęp w technologii generowania PDF dla języków RTL. Jego wyrafinowany algorytm przetwarzania oparty na segmentach, w połączeniu z automatyczną konfiguracją PDF, zapewnia programistom potężne narzędzie do tworzenia prawdziwie międzynarodowych dokumentów PDF.
Wszechstronna aplikacja demonstracyjna służy zarówno jako źródło wiedzy, jak i praktyczny przewodnik po wdrażaniu, demonstrując najlepsze praktyki w zakresie obsługi tekstu RTL w rzeczywistych scenariuszach. Niezależnie od tego, czy tworzysz aplikacje na rynki arabskojęzyczne, tworzysz dokumentację w języku hebrajskim, czy budujesz systemy wielojęzyczne, RtLTextOut zapewnia solidną podstawę potrzebną do generowania profesjonalnej jakości PDF.
Rozumiejąc i wdrażając te techniki, programiści mogą tworzyć dokumenty PDF, które właściwie służą odbiorcom na całym świecie, przełamując bariery językowe i zapewniając dostępność i czytelność treści niezależnie od używanego systemu pisma.
Aby uzyskać więcej informacji na temat HotPDF i jego zaawansowanych funkcji, odwiedź oficjalną dokumentację lub przejrzyj kompleksowe aplikacje demonstracyjne dołączone do komponentu.