PDF 텍스트 및 글꼴 마스터하기: 개발자를 위한 가이드
PDF 문서는 다양한 플랫폼 및 장치에서 서식화된 텍스트를 공유하고 보존하는 방식을 혁신했습니다. 하지만 모든 PDF의 세련된 표면 아래에는 고급 타이포그래피 개념과 정밀한 수학 연산을 결합하는 정교한 텍스트 렌더링 시스템이 있습니다. 문서 생성, 텍스트 추출 또는 PDF 조작 작업을 수행하는 개발자에게 PDF가 텍스트와 글꼴을 처리하는 방식을 이해하는 것은 매우 중요합니다.
이 포괄적인 가이드는 PDF 텍스트 렌더링의 세계로 깊이 들어가 기본 문자 간격부터 복잡한 글꼴 임베딩 기술, 문자 인코딩 시스템 및 텍스트 추출의 복잡한 과제까지 모든 것을 살펴봅니다. 숙련된 개발자이든 PDF 기술을 처음 접하는 사람이든, 이 널리 사용되는 문서가 실제로 어떻게 작동하는지에 대한 귀중한 통찰력을 얻을 수 있습니다.
PDF 텍스트 렌더링의 철학
Adobe에서 Portable Document Format을 만들 때, 오늘날 수십억 개의 문서가 렌더링되는 방식을 결정할 근본적인 설계 과제에 직면했습니다. 문제는 다음과 같았습니다. 다양한 시스템, 즉 고해상도 프린터부터 모바일 장치에 이르기까지 매우 다른 환경에서 문서가 동일하게 보이도록 유연성과 일관성을 어떻게 균형을 맞출 것인가?
그들은 두 가지 극단적인 접근 방식 중 하나를 선택할 수 있었습니다.
- 동적 레이아웃 접근 방식: 데스크톱 출판 소프트웨어와 유사하게 레이아웃 지침과 함께 일반 텍스트를 저장하여 보기 중에 실시간 텍스트 흐름 및 서식 계산을 허용합니다.
- 순수 그래픽 접근 방식: 모든 텍스트를 생성 과정에서 벡터 그래픽으로 변환하여 완벽한 시각적 일관성을 보장하지만, 모든 의미론적 정보와 텍스트 기반 기능을 완전히 잃게 됩니다.
대신, PDF는 "골디락스 접근 방식"이라고 부를 수 있는 정교한 중간 지점을 채택합니다. 이 방식은 양쪽의 장점을 모두 활용하면서 각각의 단점을 피합니다. 이 하이브리드 시스템은 글꼴과 문자의 기본 개념을 유지하면서 문서 생성 과정에서 대부분의 레이아웃 결정을 미리 계산합니다.
PDF 접근 방식의 전략적 장점
완벽한 레이아웃 제어 및 예측 가능성
단락 나누기, 줄 간격, 열 너비, 페이지 레이아웃과 같은 대규모 서식 결정은 작성 애플리케이션에서 PDF 생성 시 처리합니다. 즉, 문서가 도쿄의 스마트폰에서 보든, 실리콘 밸리의 4K 모니터에 표시되든, 뉴욕의 레이저 프린터에서 인쇄되든 동일하게 보입니다. 레이아웃의 무결성이 모든 보기 환경에서 유지되어 다른 문서 형식에서 발생하는 예측 불가능한 리플로우 문제를 방지합니다.
예측 가능한 미세한 텍스트 작업
문자 위치, 단어 간격, 글꼴 크기 조정과 같은 미세한 텍스트 작업은 잘 정의된 연산자 세트를 통해 표준화됩니다. 이를 통해 세밀한 텍스트 제어가 가능하면서도 다양한 PDF 뷰어 및 프로세서에서 예측 가능한 동작을 유지합니다. 이 시스템은 커닝, 리가처, 문맥적 문자 대체와 같은 정교한 서체 기능을 지원하면서도 일관된 결과를 보장합니다.
효율적인 저장 및 자원 관리
글꼴을 재사용 가능한 문자 모양의 라이브러리로 취급함으로써, PDF 파일은 텍스트가 많은 문서에서도 비교적 작은 크기를 유지합니다. 각 글자의 벡터 윤곽선을 개별적으로 저장하는 대신, 문서는 여러 페이지 및 여러 문서에서 재사용할 수 있는 공유 글꼴 정의를 참조합니다. 이러한 접근 방식은 파일 크기를 크게 줄이는 동시에 정교한 글꼴 부분 집합 및 임베딩 전략을 가능하게 합니다.
접근성을 위한 의미 보존
순전히 그래픽적인 접근 방식과 달리, PDF는 시각적 글리프와 그에 해당하는 기본 문자 코드 간의 중요한 연결을 유지합니다. 이러한 보존은 텍스트 검색, 복사-붙여넣기 작업, 화면 판독기 접근성 및 자동 콘텐츠 분석과 같은 필수 기능을 가능하게 합니다. 이 형식은 유니코드 매핑, 대체 텍스트 설명 및 태그 구조 정보를 지원하며, 이를 통해 문서가 보조 기술에 접근 가능합니다.
포괄적인 PDF 텍스트 상태 시스템
PDF의 텍스트 렌더링 시스템은 페이지에 텍스트가 표시되는 모든 측면을 제어하는 다양한 상태 매개변수 세트를 통해 작동합니다. 이러한 매개변수를 기본 외관뿐만 아니라 고급 서체 기능, 위치 계산 및 렌더링 최적화를 제어하는 종합적인 제어판으로 생각하십시오.
완전한 텍스트 상태 매개변수 시스템에는 다음이 포함됩니다.
| Parameter | Operator | Description | Default Value |
|---|---|---|---|
| Character Spacing | Tc | Additional space between characters | 0 |
| Word Spacing | Tw | Additional space between words | 0 |
| Horizontal Scaling | Tz | Horizontal scaling percentage | 100 |
| Leading | TL | Line spacing for T* operator | 0 |
| Font and Size | Tf | Font selection and scaling | N/A |
| Text Rendering Mode | Tr | Fill, stroke, or path mode | 0 (Fill) |
| Text Rise | Ts | Vertical text displacement | 0 |
문자 간 간격 (Tc 연산자) – 정밀 서체 제어
문자 간격 매개변수는 텍스트 문자열 내 각 문자 사이에 삽입되는 추가 공간을 세밀하게 제어합니다. 이 매개변수는 텍스트 공간 단위로 측정되며, 일반적으로 글꼴 크기의 1/1000에 해당하여 매우 정확한 조정을 가능하게 합니다.
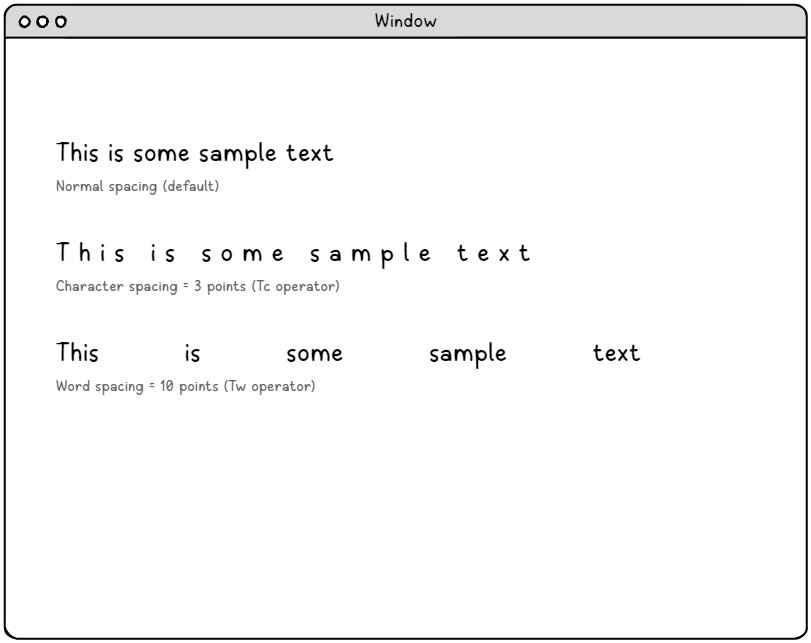
문자 간격 적용 분야는 다음과 같습니다.
- 서체 향상: 제목 및 본문 텍스트에서 강조 효과를 만들거나 가독성을 향상시킵니다.
- 정렬 지원: 정렬된 텍스트 레이아웃에서 줄 길이를 미세 조정합니다.
- 브랜드 일관성: 기업 지침에서 요구하는 특정 서체 스타일을 일치시킵니다.
- 접근성: 난독증이나 시각 장애가 있는 사용자를 위한 가독성 향상.
|
1 2 3 4 5 6 7 8 9 10 11 |
BT /F0 24 Tf 1 0 0 1 50 700 Tm (Normal text spacing) Tj 0 -30 Td 3 Tc (Character spacing = 3 points) Tj 0 -30 Td -1 Tc (Tight character spacing = -1 point) Tj ET |
단어 간 간격 조절 (Tw 연산자) – 지능형 간격 관리.
단어 간 간격 조절은 텍스트 문자열 내의 공백 문자(ASCII 32)를 대상으로 하며, 다른 공백 문자에 영향을 주지 않고 단어 간 간격을 세밀하게 제어할 수 있습니다. 이러한 정밀한 제어는 텍스트 정렬 알고리즘과 전문적인 문서 레이아웃을 만드는 데 매우 유용합니다.
Tw 연산자는 PDF가 타이포그래피에 대한 정교한 접근 방식을 보여주며, 다양한 유형의 간격이 서로 다른 목적을 가진다는 것을 인식합니다. 문자 간 간격은 모든 문자에 동일하게 영향을 미치는 반면, 단어 간 간격은 실제 단어 경계에만 영향을 미치므로 디자이너는 텍스트 흐름과 가독성에 대한 정밀한 제어를 할 수 있습니다.
|
1 2 3 4 5 6 7 8 9 10 11 |
BT /F0 24 Tf 1 0 0 1 50 600 Tm (Normal word spacing) Tj 0 -30 Td 10 Tw (Extended word spacing improves readability) Tj 0 -30 Td -2 Tw (Compressed word spacing saves space) Tj ET |
수평 스케일링 (Tz 연산자) – 치수 타이포그래피 제어.
수평 스케일링을 통해 텍스트의 높이에 영향을 주지 않고 가로로 늘리거나 압축할 수 있으며, 이는 백분율로 표현되며 100%는 일반적인 너비를 나타냅니다. 이 매개변수는 반응형 타이포그래피 조정 및 기존의 편집 방식으로 불가능한 특수한 타이포그래피 효과를 가능하게 합니다.
수평 스케일링 적용 분야:
- 공간 제약 레이아웃: 텍스트를 미리 정해진 열 너비 또는 디자인 요소에 맞추기.
- 스타일 효과: 제목 및 강조를 위해 텍스트를 압축하거나 확장하기.
- 글꼴 시뮬레이션: 사용 가능한 경우, 압축 또는 확장된 글꼴 변형을 근사하기.
- 반응형 디자인: 가독성을 유지하면서 텍스트를 다양한 페이지 크기에 맞게 조정하기.
그러나, 가로 스케일링은 신중하게 사용해야 합니다. 과도한 스케일링은 가독성을 저해하고 부자연스러운 텍스트를 만들어 독서 경험을 방해할 수 있습니다. 권장되는 방법은 본문 텍스트의 스케일링 범위를 85-115%로 제한하고, 더 극적인 스케일링은 디스플레이 용도로 사용하는 것입니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
BT /F0 24 Tf 1 0 0 1 50 500 Tm 100 Tz (Normal horizontal scaling - 100%) Tj 0 -30 Td 80 Tz (Condensed text - 80% scaling) Tj 0 -30 Td 120 Tz (Extended text - 120% scaling) Tj ET |
자간 (TL Operator) – 수직 리듬 및 가독성
자간은 "ledding"으로 발음하며, 전통적인 인쇄 방식에서 얇은 납 조각을 글자 줄 사이에 삽입하는 것에서 유래했습니다. PDF에서 자간은 텍스트 베이스라인 사이의 수직 공간을 결정하며, T* (다음 줄로 이동) 연산자를 사용할 때 텍스트 위치가 얼마나 이동하는지를 제어합니다.
적절한 자간은 텍스트의 가독 가능한 수직 리듬을 설정하는 데 매우 중요합니다. 글꼴 크기와 자간의 관계는 가독성, 이해 속도 및 전체 문서의 미적 감각에 큰 영향을 미칩니다. 타이포그래피 전문가들은 일반적으로 최적의 가독성을 위해 글꼴 크기의 120%에서 145% 사이의 자간 값을 권장합니다.
자간 고려 사항:
- 글꼴 크기 관계: 일반적으로 글꼴 크기가 클수록 더 많은 자간이 필요합니다.
- 줄 길이 영향: 긴 줄은 여백을 늘려 독자가 다음 줄의 시작 부분으로 쉽게 돌아갈 수 있도록 하는 것이 좋습니다.
- 글꼴 특징: 큰 x-높이 또는 장식 요소를 가진 글꼴은 여백을 조정해야 할 수 있습니다.
- 읽기 환경: 콘텐츠 유형에 따라 (본문, 캡션, 제목) 필요한 여백이 다릅니다.
|
1 2 3 4 5 6 7 8 9 10 |
BT /F0 18 Tf 18 TL 1 0 0 1 50 400 Tm (This text uses 18pt leading) Tj T* (which matches the font size) Tj T* 24 TL (This text uses 24pt leading) Tj T* (providing more generous spacing) Tj T* ET |
텍스트 높이 (Ts 연산자) – 수직 위치 정밀도
텍스트 높이는 정밀한 수직 조정 기능을 제공하여, 텍스트 흐름에 영향을 주지 않고 텍스트를 기준선 위 또는 아래로 이동할 수 있습니다. 이 매개변수는 정확한 수직 위치가 필요한 전문적인 타이포그래피 요소를 만드는 데 필수적입니다.

텍스트 높이의 적용 분야는 다음과 같습니다.
- 수학 표기: 지수, 하첨자 및 수학 기호의 배치.
- 과학 콘텐츠: 화학식, 분자 구조 및 과학적 주석.
- 편집 요소: 각주 표시, 상표 기호 및 저작권 표시.
- 다국어 서체: 다양한 문자 체계에 대한 기준선 위치 조정.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
BT /F0 36 Tf 1 0 0 1 140 290 Tm (H) Tj -8 Ts /F0 24 Tf (2) Tj 0 Ts /F0 36 Tf (O represents water with O) Tj 8 Ts /F0 24 Tf (2) Tj 0 Ts /F0 36 Tf ( as oxygen) Tj ET |
고급 텍스트 변환 및 행렬 연산
PDF의 가장 정교한 기능 중 하나는 이중 행렬 시스템을 통해 텍스트 변환과 그래픽 변환을 완벽하게 결합하는 기능입니다. 이 기능은 복잡한 레이아웃 효과를 가능하게 하면서, 다양한 보기 환경에서 일관된 텍스트 위치 지정 작업을 수행하는 데 필요한 수학적 정확성을 유지합니다.

변환 시스템은 두 가지 주요 행렬을 통해 작동합니다.
현재 변환 행렬 (CTM)
CTM은 모든 그래픽 요소, 텍스트를 포함하여 전역 좌표 변환을 처리합니다. 페이지 수준에서 회전, 크기 조정, 이동, 기울기 등의 작업을 관리합니다. cm과 같은 연산자를 사용하여 변환을 적용하면 CTM이 수정됩니다.
텍스트 행렬 (TM)
TM은 텍스트 위치 지정 및 로컬 텍스트 변환을 specifically 처리합니다. CTM과 함께 작동하여 텍스트 블록 전체가 변환되더라도 줄 바꿈, 문자 이동, 단락 흐름과 같은 텍스트 위치 지정 작업이 올바르게 계속 작동하도록 합니다.
행렬 변환 순서
PDF에서 변환된 텍스트가 렌더링될 때, 정확한 수학적 순서를 따릅니다.
- 글리프 공간 계산: 개별 문자 모양은 글리프 공간 좌표로 정의됩니다.
- 텍스트 공간 변환: 문자는 글꼴 크기와 텍스트 상태 매개변수를 사용하여 텍스트 공간에 배치됩니다.
- 텍스트 행렬 적용: 텍스트 행렬은 좌표를 텍스트 공간에서 사용자 공간으로 변환합니다.
- 그래픽 행렬 적용: 현재 변환 행렬은 최종 위치와 방향을 적용합니다.
- 장치 공간 변환: 최종 좌표는 렌더링을 위해 장치별 단위로 변환됩니다.
이 다단계 프로세스는 텍스트 변환이 수학적으로 정확하고 다양한 보기 조건, 출력 장치 및 스케일링 요소에서 시각적으로 일관성을 유지하도록 보장합니다.
|
1 2 3 4 5 6 7 8 9 10 11 |
% Set up rotation transformation 0.96 0.25 -0.25 0.96 0 0 cm BT /F0 48 Tf 48 TL % Set text matrix for positioning 1 0 0 1 270 240 Tm (Text and graphics) Tj T* (transforms combined) Tj T* (with proper newlines) Tj ET |
텍스트 변환의 실제 응용 분야
- 회전된 헤더 및 레이블: 차트, 다이어그램 및 특수 레이아웃에 대한 기울어진 텍스트 생성
- 예술적인 타이포그래피: 창의적인 텍스트 효과 구현과 가독성 유지.
- 다방향 문서: 혼합된 세로 및 가로 요소가 포함된 문서 지원.
- 좌표 시스템 정렬: 텍스트 방향을 기존 그래픽 좌표 시스템에 맞춤.
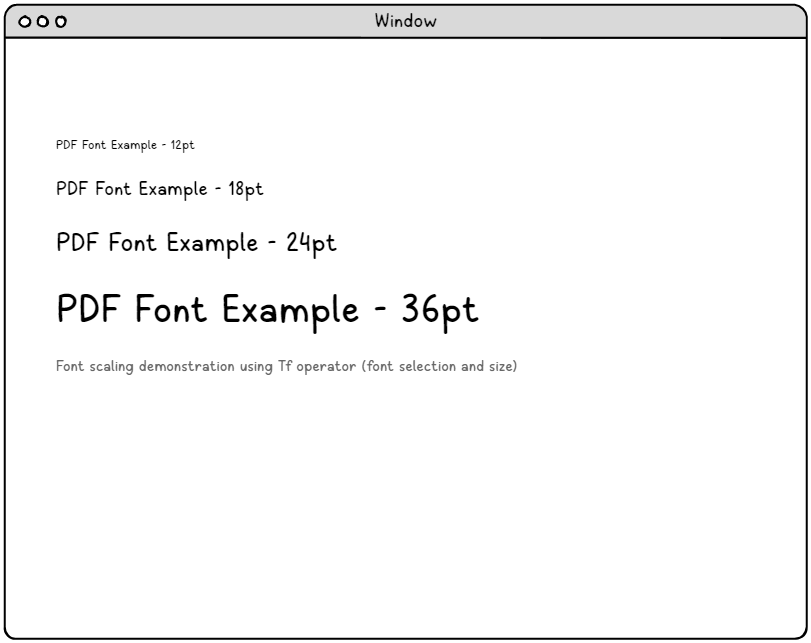
포괄적인 글꼴 선택 및 리소스 관리.
PDF에서 글꼴 처리는 단순한 글꼴 선택을 넘어선 정교한 리소스 관리 시스템을 포함합니다. 이 시스템은 다양한 환경에서 최적의 렌더링 성능을 유지하면서 효율적으로 글꼴 리소스, 문자 인코딩 방식, 스케일링 작업 및 호환성 요구 사항을 관리해야 합니다.
글꼴 리소스 사전 시스템.
PDF 문서에서는 계층적 글꼴 사전 구조를 사용하여 기호 이름을 실제 글꼴 리소스에 매핑합니다. 이러한 간접적인 계층 구조는 문서 아키텍처에서 여러 중요한 역할을 수행합니다.
- 리소스 최적화: 여러 페이지와 콘텐츠 스트림은 중복 없이 동일한 글꼴 리소스를 공유할 수 있습니다.
- 대체 제어: 글꼴 대체 메커니즘을 리소스 수준에서 구현할 수 있으며, 콘텐츠 스트림에는 영향을 미치지 않습니다.
- 인코딩 관리: 문자 인코딩 체계를 특정 글꼴 인스턴스와 연결할 수 있습니다.
- 성능 향상: 글꼴 로딩 및 파싱은 지능적인 캐싱 전략을 통해 최적화될 수 있습니다.
글꼴 유형 및 기술적 특징
Type 1 (PostScript) 글꼴
Type 1 글꼴은 어도비의 원래 확장 가능한 글꼴 기술로, 수학적 정확성을 사용하여 큐빅 베지어 곡선으로 문자 윤곽선을 정의합니다. 이러한 글꼴은 뛰어난 확장성 및 정교한 힌팅 시스템 덕분에 전문 출판 애플리케이션에서 뛰어난 성능을 발휘합니다.
주요 Type 1 특징:
- 큐빅 베지어 윤곽선: 수학적으로 정확한 곡선 정의로, 어떤 크기에도 부드럽게 확장됩니다.
- PostScript 힌팅: 작은 크기에서도 최적의 렌더링을 위한 지능적인 윤곽선 조정.
- 인코딩 유연성: 사용자 정의 문자 인코딩 및 특수 문자 세트 지원.
- 임베딩 호환성: 라이선스 존중 메커니즘을 갖춘 완전한 임베딩 지원.
TrueType 글꼴
TrueType 글꼴은 이차 베지어 곡선을 사용하며, 화면 표시 및 저해상도 출력 장치에 최적화된 정교한 힌팅 정보를 포함합니다. Apple에서 처음 개발했으며, 이후 Microsoft에서 채택한 TrueType 글꼴은 뛰어난 플랫폼 간 호환성을 제공합니다.
TrueType의 장점:
- 화면 최적화: 픽셀 그리드 정렬에 최적화된 고급 힌팅 시스템
- 플랫폼 호환성: 다양한 운영 체제 및 애플리케이션에 대한 폭넓은 지원
- 압축된 저장 공간: 이차 곡선을 사용한 효율적인 윤곽선 표현
- 유니코드 지원: 대규모 문자 집합 및 국제 텍스트에 대한 기본 지원
OpenType 글꼴
OpenType은 디지털 서체의 발전을 나타내며, Type 1 및 TrueType 글꼴의 최상의 기술적 기능을 결합하는 동시에 혁신적인 서체 기능을 추가하여 전문 텍스트가 렌더링되는 방식을 변화시킵니다.
OpenType의 혁신:
- 고급 서체: 문맥적 리가처, 스와시, 대체 글꼴, 스타일 세트
- 방대한 문자 세트: 수천 개의 문자 및 여러 문자 체계 지원
- 레이아웃 지능: 정교한 규칙을 통한 문맥 기반 문자 대체 및 배치
- 플랫폼 간 일관성: 다양한 시스템 및 애플리케이션에서 동일한 렌더링 동작
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
BT % Select font and set initial size /F0 12 Tf 1 0 0 1 50 750 Tm (12-point font example) Tj % Change to larger size, same font /F0 18 Tf 0 -25 Td (18-point font example) Tj % Even larger size /F0 24 Tf 0 -35 Td (24-point font example) Tj % Largest size /F0 36 Tf 0 -50 Td (36-point font example) Tj ET |
전문적인 커닝 및 글리프 배치
전문적인 서체 디자인은 개별 문자 간 간격에 대한 정밀한 제어를 요구합니다. 문자 모양에 따라 다양한 문자 조합 간의 시각적 간격이 크게 달라지므로, 지능적인 커닝 조정은 전문 출판 기준을 충족하는 시각적으로 매력적이고 가독성이 뛰어난 텍스트를 만드는 데 필수적입니다.

TJ 연산자는 단순한 문자 및 단어 간격 제어를 넘어선 정교한 글리프 배치 기능을 제공합니다. TJ 연산자는 단일 텍스트 문자열 대신, 문자 수준의 정밀한 위치 제어를 가능하게 하는 이종 배열을 받아들입니다.
TJ 배열 구조 이해
TJ 연산자의 배열 기반 접근 방식은 혼합 콘텐츠를 받아들임으로써 텍스트 위치 방식을 혁신합니다.
- 문자 요소: 포함하는 실제 텍스트 내용이며, 표준 글꼴 인코딩을 사용합니다.
- 숫자 요소: 텍스트 공간 단위의 천분 단위로 측정되는 수평 조정 값을 지정합니다.
- 음수 값: 이후 문자를 더 가깝게 배치하여 문자 간 간격을 줄입니다.
- 양수 값: 문자 간 간격을 늘려 텍스트 레이아웃을 확장합니다.
이러한 세밀한 제어 기능을 통해 전문적인 수준의 서체 디자인이 가능하며, 단순한 텍스트 처리 방식으로는 불가능한 정확한 커닝 조정을 제공합니다. 이 시스템은 미적인 개선과 서체 메트릭에 대한 기술적 수정 모두를 지원합니다.
|
1 2 3 4 5 6 7 8 9 |
BT /F0 48 Tf 1 0 0 1 100 400 Tm % Standard text rendering (WAVE Type) Tj 0 -60 Td % Kerned text with precise adjustments [(W) -120 (A) -80 (V) -100 (E) 50 (T) -20 (y) -10 (p) -5 (e)] TJ ET |
고급 커닝 전략
광학 커닝
광학 커닝은 글꼴 내장 메트릭에만 의존하는 것이 아니라, 문자 조합의 시각적 외관에 따라 문자 간 간격을 조정합니다. 이 방식은 인접한 문자의 실제 모양과 시각적 상호 작용을 고려합니다.
메트릭 커닝
메트릭 커닝은 글꼴에 내장된 커닝 테이블을 사용하여 특정 문자 쌍 간의 간격을 조정합니다. 전문적인 글꼴에는 수천 개의 문자 쌍 조정이 포함된 광범위한 커닝 테이블이 포함되어 있습니다.
수동 커닝
수동 커닝을 사용하면 특정 디자인 요구 사항에 맞게 또는 자동 커닝 시스템으로 충분히 해결되지 않는 문제 있는 문자 조합을 수정하기 위해 문자별로 정확한 조정을 할 수 있습니다.
실용적인 커닝 적용 사례
- 로고 및 브랜딩: 기업의 정체성을 나타내는 서체에 대한 정밀한 제어
- 헤드라인 서체: 시각적 효과를 극대화하기 위한 큰 글꼴 최적화
- 섬세한 서체 디자인: 출판 품질의 텍스트 레이아웃 구현
- 다국어 지원: 다양한 문자 체계 및 문자 조합에 따른 간격 조정.
텍스트 렌더링 모드 및 시각 효과.
PDF는 텍스트가 시각적으로 어떻게 표시되는지를 제어하는 8가지 텍스트 렌더링 모드를 제공하며, 다양한 типографические 효과를 만들 수 있는 광범위한 유연성을 제공합니다. 이러한 모드는 텍스트가 채워지거나, 윤곽선이 적용되거나, 클리핑 경로로 사용되거나, 특수 목적을 위해 보이지 않게 렌더링되는지 여부를 결정합니다.
텍스트 렌더링 모드 참조 (전체).
| Mode | Name | Visual Effect | Common Uses |
|---|---|---|---|
| 0 | Fill | Solid color fill only | Standard body text |
| 1 | Stroke | Outline only, no fill | Decorative headers |
| 2 | Fill and Stroke | Both fill and outline | Emphasized text |
| 3 | Invisible | No visual rendering | Text positioning |
| 4 | Fill and Add to Path | Fill plus path construction | Text-based clipping |
| 5 | Stroke and Add to Path | Stroke plus path construction | Complex path operations |
| 6 | Fill, Stroke, and Add to Path | Complete text with path | Advanced graphics integration |
| 7 | Add to Path Only | Path construction, no rendering | Clipping path creation |
고급 렌더링 모드 응용.
보이지 않는 텍스트 모드 (모드 3).
PDF 문서에서 보이지 않는 텍스트는 여러 가지 특수 목적을 수행합니다.
- 검색 가능한 이미지 PDF. 스캔한 문서에 검색 기능을 위한 보이지 않는 텍스트를 오버레이합니다.
- 텍스트 위치 조정: 복잡한 레이아웃에서 시각적 출력 없이 텍스트 위치를 조정합니다.
- 접근성 향상: 시각적인 방해 없이 대체 텍스트 설명을 제공합니다.
- 템플릿 시스템: 동적 콘텐츠 생성을 위한 위치 지정 프레임워크를 만듭니다.
경로 생성 모드 (4-7번 모드)
이러한 고급 모드는 텍스트와 그래픽 시스템 간의 정교한 통합을 가능하게 합니다.
- 텍스트 기반 클리핑: 텍스트 모양을 사용하여 다른 그래픽 요소를 클리핑합니다.
- 복잡한 마스킹: 문자 모양을 사용하여 복잡한 마스킹 효과를 만듭니다.
- 예술적인 효과: 텍스트를 그라데이션, 패턴 및 기타 그래픽 요소와 결합합니다.
- 인터랙티브 요소: 텍스트 경계를 정확하게 일치시키는 클릭 가능한 영역을 만듭니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
BT /F0 36 Tf 1 0 0 1 100 500 Tm % Standard filled text 0 Tr (Filled Text) Tj 0 -50 Td % Stroked text only 1 Tr 2 w (Stroked Text) Tj 0 -50 Td % Both filled and stroked 2 Tr (Filled and Stroked) Tj ET |
글꼴 임베딩 및 서브셋 최적화.
글꼴 임베딩은 PDF 생성에서 가장 중요한 기술적 과제 중 하나이며, 문서 이식성, 파일 크기 최적화 및 법적 준수 간의 균형을 유지합니다. 임베딩 시스템은 다양한 시스템에서 문서가 동일하게 렌더링되도록 보장하는 동시에 글꼴 라이선스 제한을 준수하고 합리적인 파일 크기를 유지해야 합니다.
글꼴 임베딩 전략.
전체 글꼴 임베딩.
전체 글꼴 임베딩은 PDF 문서 내에 전체 글꼴 파일을 포함하여 완벽한 렌더링 호환성을 보장하지만 파일 크기가 증가합니다. 이 방법은 모든 문자, 커닝 정보 및 서체 기능을 사용할 수 있도록 보장합니다.
장점:
- 완벽한 호환성: 대상 시스템과 관계없이 모든 글꼴 기능이 그대로 사용 가능합니다.
- 렌더링 정확도: 원래의 서체 및 간격이 완벽하게 재현됩니다.
- 기능 유지: 고급 OpenType 기능이 정상적으로 작동합니다.
- 미래 대비: 글꼴 사용 가능 여부에 관계없이 문서의 가독성은 유지됩니다.
단점:
- 파일 크기 영향: 문서 크기가 크게 증가하며, 특히 여러 글꼴을 사용할 경우 더욱 그렇습니다.
- 라이선스 관련 문제: 글꼴 임베딩을 제한하는 글꼴 라이선스 계약을 위반할 수 있습니다.
- 처리 오버헤드: 글꼴 로딩으로 인해 메모리 사용량과 처리 시간이 증가합니다.
글꼴 부분 추출:
글꼴 부분 추출은 문서에 실제로 사용된 문자만 포함하여 파일 크기를 크게 줄이면서, 포함된 문자 세트에 대한 렌더링 정확도를 유지합니다.
부분 집합의 장점:
- 최적 파일 크기: 문서 크기에 미치는 영향이 최소화되면서 서식은 유지됩니다.
- 라이선스 준수: 사용된 문자만 포함되므로 법적 문제가 줄어듭니다.
- 성능 향상: 글꼴 로딩 속도가 빨라지고 메모리 사용량이 줄어듭니다.
- 대역폭 효율성: 작은 파일은 네트워크를 통해 더 빠르게 전송됩니다.
문자 인코딩 및 유니코드 매핑
PDF의 문자 인코딩 시스템은 글꼴별 문자 코드와 유니코드와 같은 범용 문자 식별 시스템 간의 간극을 메워야 합니다. 이 매핑 프로세스는 텍스트 추출, 검색 및 접근성 기능에 매우 중요합니다.
인코딩 메커니즘
내장 인코딩: 글꼴의 내부 문자 매핑을 사용하며, 표준 서양 문자 세트에 적합하지만 국제 콘텐츠에는 제한적입니다.
표준 PDF 인코딩: WinAnsiEncoding 및 MacRomanEncoding과 같은 미리 정의된 인코딩 체계는 다양한 플랫폼에서 일관된 문자 매핑을 제공합니다.
사용자 정의 인코딩: 문서별 문자 매핑으로, 특수 문자 또는 기존 글꼴 시스템 지원을 가능하게 합니다.
유니코드 (CMap) 시스템: 문자 맵 (CMaps)을 사용하는 현대적인 방식으로, 문자 코드와 유니코드 값 간의 직접적인 매핑을 제공합니다.
ToUnicode 매핑 테이블:
ToUnicode CMaps는 글꼴별 문자 코드와 유니코드 값 간의 연결을 제공하여 정확한 텍스트 추출 및 검색을 가능하게 합니다. 이러한 매핑 테이블은 접근성과 콘텐츠 분석에 필수적입니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
% Example ToUnicode CMap structure 23 0 obj << /Length 317 >> stream /CIDInit /ProcSet findresource begin 12 dict begin begincmap /CIDSystemInfo << /Registry (Adobe) /Ordering (UCS) /Supplement 0 >> def /CMapName /Adobe-Identity-UCS def 1 begincodespacerange <0001> endcodespacerange 2 beginbfchar <0001> <0041> % Map glyph 1 to Unicode U+0041 (A) <0002> <0042> % Map glyph 2 to Unicode U+0042 (B) endbfchar endcmap CMapName currentdict /CMap defineresource pop end end endstream endobj |
PDF 텍스트 추출의 복잡한 과제:
PDF 문서에서 텍스트를 추출하는 것은 PDF 처리의 가장 기술적으로 어려운 측면 중 하나이며, 그래픽 기반 형식에서 논리적인 읽기 순서를 재구성할 수 있는 정교한 알고리즘이 필요합니다. 기존 텍스트 형식과 달리, PDF는 텍스트를 의미 구조를 유지하는 대신 위치가 지정된 그래픽 요소의 시퀀스로 저장하므로, 추출은 복잡한 역공학 프로세스가 됩니다.
기본적인 추출 과제
비순차적인 텍스트 배치
PDF 콘텐츠 스트림은 텍스트 요소를 논리적인 읽기 순서가 아닌 시각적 레이아웃 요구 사항에 따라 배치합니다. 단락 하나가 수십 개의 분리된 텍스트 배치 명령으로 표현될 수 있으며, 이러한 명령은 콘텐츠 스트림 전체에 흩어져 있으며, 그래픽 작업 및 기타 텍스트 요소와 혼합되어 있습니다.
이러한 배치 방식은 여러 가지 추출상의 어려움을 야기합니다.
- 읽기 순서 재구성: 순서가 뒤바뀐 텍스트 요소의 올바른 순서를 결정합니다.
- 열 감지: 다중 열 레이아웃을 식별하고 올바른 열 흐름을 결정합니다.
- 페이지 구조 분석: 헤더, 푸터, 사이드바 및 주요 콘텐츠 영역 구분
- 상호 참조 해결: 그래픽 또는 서식으로 분리된 관련 텍스트 요소 연결
글꼴 및 인코딩 문제
문자 추출에는 글꼴 인코딩 방식의 정확한 해석이 필요하며, 이는 다양한 글꼴 및 문서 작성 시스템 간에 크게 다를 수 있습니다.
- 누락된 글꼴 정보: 문서에서 참조하는 글꼴이 추출 시스템에 없을 수 있습니다.
- 인코딩 변형: 서로 다른 글꼴은 호환되지 않는 문자 인코딩 방식을 사용할 수 있습니다.
- 부분 글꼴 제한 사항: 포함된 글꼴 부분 집합은 완전한 문자 매핑 정보를 포함하지 않을 수 있습니다.
- 유니코드 매핑 오류: 잘못되었거나 누락된 ToUnicode 테이블은 문자 오해를 유발할 수 있습니다.
레이아웃 구조 인식
전문 문서는 자동 추출 시스템에 어려움을 주는 복잡한 레이아웃 구조를 사용합니다.
- 표 인식: 표 데이터 식별 및 행/열 관계 유지.
- 목록 구조: 글머리 기호 및 번호 목록 인식, 적절한 계층 구조 유지.
- 부동 요소: 텍스트 상자, 사이드바 및 콜아웃 처리 (일반 텍스트 흐름을 방해하는 요소).
- 다중 페이지 연속성: 단락 및 섹션에 대한 페이지 경계를 넘어 문맥 유지.
고급 추출 방법론
다단계 분석 접근 방식
정교한 추출 시스템은 여러 분석 단계를 사용하며, 각 단계는 문서 구조의 서로 다른 측면에 집중합니다.
- 문자 수준 분석: 개별 문자 위치, 글꼴 및 인코딩 정보를 추출합니다.
- 단어 형성 분석: 공백 및 글꼴 특성을 기반으로 문자를 단어로 그룹화합니다.
- 줄 감지 분석: 텍스트 줄을 기준선 분석 및 수직 간격 패턴을 사용하여 식별합니다.
- 단락 조립 단계: 들여쓰기 및 간격 힌트를 기반으로 줄을 단락으로 결합합니다.
- 구조 분석 단계: 헤더, 목록, 표 및 기타 문서 요소를 감지합니다.
- 콘텐츠 구성 단계: 요소를 논리적인 읽기 순서 및 계층 구조로 구성합니다.
머신러닝 기반 개선.
최신 추출 시스템은 정확도를 향상시키기 위해 점점 더 많은 머신 러닝 기술을 사용합니다.
- 레이아웃 분류: 일반적인 문서 레이아웃 패턴을 인식하도록 모델을 훈련합니다.
- 읽기 순서 예측: 신경망을 사용하여 최적의 텍스트 순서를 결정합니다.
- 콘텐츠 유형 인식: 텍스트 요소를 자동으로 헤더, 본문, 캡션 등으로 분류합니다.
- 테이블 구조 감지: 복잡한 테이블 레이아웃 인식을 위한 고급 알고리즘.
텍스트 추출 코드 예제.
다음 예제는 PDF 위치 명령에서 텍스트를 재구성하는 데 관련된 복잡성을 보여줍니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
% Complex text positioning that challenges extraction BT /F0 12 Tf 1 0 0 1 72 720 Tm (This text appears) Tj 150 0 Td (out of order) Tj -150 -15 Td (in the content stream) Tj 200 0 Td (but should be) Tj -200 -15 Td (reconstructed properly) Tj 100 0 Td (by extraction algorithms.) Tj ET % Graphics elements that interrupt text flow q 1 0 0 1 100 650 cm 0.5 g 0 0 200 50 re f Q % Continuation of text after graphics BT /F0 12 Tf 1 0 0 1 72 630 Tm (Text continues after graphics elements) Tj ET |
품질 보증 및 검증.
전문 추출 시스템은 여러 가지 검증 메커니즘을 구현합니다.
- 언어 분석: 사전 검사 및 문법 검증을 통해 추출 오류를 식별합니다.
- 형식 일관성: 추출된 구조가 일반 문서 패턴과 일치하는지 확인.
- 상호 참조 검증: 내부 문서 참조가 손상되지 않았는지 확인.
- 문자 인코딩 검증: 문자 인코딩 오류를 감지하고 수정.
성능 최적화 및 모범 사례.
효율적인 PDF 텍스트 처리는 렌더링 속도, 메모리 사용량 및 전체 시스템 응답성에 큰 영향을 미치는 성능 요소에 대한 주의가 필요합니다. 최신 PDF 애플리케이션은 간단한 단일 페이지 파일부터 복잡한 수천 페이지 분량의 출판물까지 다양한 문서를 처리해야 합니다.
글꼴 리소스 관리.
지능형 캐싱 전략
글꼴 로딩 및 파싱은 비용이 많이 드는 작업이며, 전략적인 캐싱을 통해 상당한 이점을 얻을 수 있습니다.
- 리소스 레벨 캐싱: 리소스 딕셔너리 레벨에서 파싱된 글꼴 객체를 캐시하여 불필요한 파싱을 방지합니다.
- 글리프 렌더링 캐시: 렌더링된 문자 글리프를 저장하여 여러 텍스트 작업에서 재사용합니다.
- 메트릭 계산 캐시: 글꼴 메트릭 계산을 캐시하여 반복적인 계산을 방지합니다.
- 문서 간 캐싱: 필요한 경우, 여러 PDF 문서에서 폰트 리소스를 공유합니다.
메모리 관리 전략:
효과적인 메모리 관리는 텍스트 중심 애플리케이션의 성능 저하를 방지합니다.
- 지연 로딩: 렌더링 또는 처리 시 필요한 경우에만 폰트 리소스를 로드합니다.
- 리소스 풀링: 일반적으로 사용되는 폰트 객체의 풀을 유지하여 할당 오버헤드를 줄입니다.
- 가비지 컬렉션 최적화: 사용하지 않는 글꼴 리소스에 대한 스마트 정리 전략 구현.
- 메모리 매핑: 큰 내장 글꼴에 대해 메모리 매핑 파일을 사용하여 RAM 사용량을 줄입니다.
텍스트 스트림 최적화.
콘텐츠 스트림 구성.
텍스트 작업을 효율적으로 구성하면 렌더링 성능을 크게 향상시킬 수 있습니다.
- 텍스트 작업 일괄 처리: 관련된 텍스트 작업을 단일 BT/ET 블록 내에 그룹화하여 상태 변경을 최소화합니다.
- 글꼴 변경을 최소화합니다. 콘텐츠를 구성하여 글꼴 선택 작업을 줄입니다.
- 전략적 배치: 적절한 경우 절대 배치(Tm) 대신 상대 배치(Td, TD)를 사용합니다.
- 상태 통합: 호환 가능한 텍스트 상태 변경을 단일 작업으로 결합합니다.
렌더링 파이프라인 최적화.
최신 PDF 프로세서는 정교한 렌더링 파이프라인을 사용합니다.
- 멀티 스레딩: 독립적인 텍스트 요소의 병렬 처리.
- GPU 가속: 하드웨어 가속 글리프 래스터화 및 합성.
- 점진적 렌더링: 백그라운드 처리가 진행되는 동안 텍스트 콘텐츠를 표시합니다.
- 뷰포트 절단: 보이는 영역 밖의 텍스트 요소에 대한 처리를 건너습니다.
접근성 및 보편적 설계
접근 가능한 PDF 문서를 만들려면 텍스트 구조, 의미론적 마크업 및 보조 기술 호환성에 주의를 기울여야 합니다. 최신 접근성 표준에서는 PDF 문서가 화면 읽기 프로그램, 음성 인식 소프트웨어 및 기타 보조 기술과 원활하게 작동해야 합니다.
태그가 있는 PDF 구조
태그가 있는 PDF는 의미론적 구조 정보를 제공하여 보조 기술이 문서의 구조를 이해할 수 있도록 합니다.
- 논리적 구조 트리: 문서 요소의 계층적 구성
- 역할 기반 태깅: 제목, 단락, 목록 및 기타 요소의 의미적 식별.
- 읽기 순서 지정: 올바른 읽기 순서의 명시적 정의.
- 대체 설명: 그래픽 요소 및 복잡한 구조에 대한 텍스트 대체.
국제 텍스트 지원.
글로벌 문서 접근성을 위해서는 포괄적인 국제 텍스트 지원이 필요합니다.
- Unicode 준수: 모든 국제 문자 집합 및 문자 체계에 대한 완벽한 지원.
- 양방향 텍스트: 왼쪽에서 오른쪽으로, 오른쪽에서 왼쪽으로 혼합된 콘텐츠에 대한 적절한 처리.
- 복잡한 문자 체계: 아랍어, 인도 문자 및 기타 복잡한 문자 체계에서 문맥에 따른 문자 모양 지원.
- 수직 텍스트 지원: 전통 중국어, 일본어 및 몽골어 수직 텍스트 레이아웃 지원.
PDF 타이포그래피의 향후 개발.
PDF 사양은 계속 진화하며, 디지털 문서 워크플로우, 웹 통합 및 고급 타이포그래피 애플리케이션에서 발생하는 새로운 요구 사항을 해결하는 새로운 기능을 통합합니다.
차세대 타이포그래피 기능
가변 폰트 기술
가변 폰트는 디지털 타이포그래피의 혁신적인 발전으로, 단일 폰트 파일에 여러 디자인 변형을 포함할 수 있습니다.
- 두께 변형: 얇은 글씨체에서 굵은 글씨체로 연속적인 조정
- 너비 변형: 좁은 글씨체에서 넓은 글씨체로 동적인 조정
- 광학 크기: 다양한 디스플레이 크기에 대한 자동 최적화
- 사용자 정의 축: 글꼴별 변형, 예를 들어 대비, x-높이 또는 스타일 변형
컬러 글꼴 통합
고급 컬러 글꼴은 기존 글꼴로는 불가능했던 풍부한 서체 표현을 가능하게 합니다.
- 내장 그래픽: 전체 컬러 비트맵 또는 벡터 그래픽을 포함하는 글꼴
- 그라데이션 지원: 복잡한 색상 전환 및 효과를 가진 문자:
- 다층 글꼴: 그림자, 윤곽선 및 장식 요소에 대한 별도 레이어를 가진 글꼴:
- 애니메이션 타이포그래피: 디지털 프레젠테이션을 위한 시간 기반 타이포그래피 효과:
웹 및 모바일 통합:
PDF 문서가 웹 및 모바일 환경에서 점점 더 많이 사용됨에 따라, 새로운 기능은 반응형 및 적응형 타이포그래피에 중점을 둡니다.
- 점진적인 텍스트 로딩: 배경 글꼴 로딩을 통한 더 빠른 초기 표시:
- 반응형 타이포그래피: 다양한 화면 크기와 방향에 대한 적응형 텍스트 재정렬:
- 터치 최적화된 상호 작용: 터치스크린 장치에 대한 향상된 텍스트 선택 및 상호 작용:
- 고해상도 지원: 고해상도 디스플레이에 대한 최적화된 렌더링:
결론
PDF 텍스트 시스템의 정교함은 수십 년간의 디지털 타이포그래피 및 문서 기술 발전의 결과입니다. 각 연산자, 매개변수 및 인코딩 방식은 전문 문서 제작 생태계에서 특정 목적을 수행합니다. 글꼴 임베딩 전략, 문자 인코딩 시스템, 변환 행렬 및 렌더링 모드는 모두 함께 작동하여 텍스트 통신을 위한 강력한 플랫폼을 구축합니다.
PDF 텍스트 및 글꼴 작업을 계속하면서, 사양이 복잡한 이유가 중요한 목적을 수행한다는 점을 기억하십시오. 즉, 문서의 장기 보존, 시각적 충실도 유지, 국제 콘텐츠 지원 및 접근성 제공입니다. 이러한 기본 개념은 PDF 기술이 계속 발전하고 디지털 통신의 새로운 과제에 적응함에 따라 귀중한 역할을 할 것입니다.