PDF 내부 구조 이해.
PDF 내부 구조의 매혹적인 세계에 오신 것을 환영합니다! PDF 파일이 어떻게 작동하는지 궁금해하신 적이 있습니까? 매일 보는 익숙한 문서 외에도, 디지털 문서 공유를 혁신한 정교한 아키텍처가 있습니다. 이 포괄적인 탐색에서 PDF 구조의 층위를 벗겨내어 이러한 보편적인 파일이 작동하는 복잡한 메커니즘을 밝힐 것입니다.
🔍 소개: 표면 너머
PDF(Portable Document Format)는 전 세계 문서 교환의 사실상 표준이 되었습니다. 간단한 텍스트 문서부터 복잡한 대화형 양식까지, PDF는 다양한 플랫폼과 장치에서 일관된 모양을 유지합니다. 하지만 이 보편적인 호환성 뒤에는 무엇이 있을까요?
이 심층 분석에서 PDF 파일을 진정으로 휴대 가능하게 만드는 논리적 구조를 살펴볼 것입니다. 다음의 기본 구성 요소를 살펴보겠습니다. 트레일러 사전 (trailer dictionary)., 문서 카탈로그 (document catalog).그리고 페이지 트리—PDF의 모든 기능을 조율하는 핵심 요소입니다. 또한 PDF의 텍스트 문자열 및 날짜에 대한 특수 데이터 형식의 비밀을 밝힐 것입니다.
🎯 이 가이드에서 배우는 내용:
- PDF 구조의 네 가지 기본 구성 요소
- PDF가 콘텐츠를 효율적으로 구성하고 참조하는 방법
- 딕셔너리, 카탈로그 및 페이지 트리의 역할
- PDF의 텍스트 인코딩 및 날짜 형식에 대한 고유한 접근 방식
- PDF 객체 구조의 실제 예시
- PDF 내부 구조 이해를 위한 모범 사례
📋 PDF의 구조: 개요
구체적인 내용으로 들어가기 전에, PDF 구조에 대한 기본적인 이해를 갖도록 합시다. PDF를 모든 정보가 특정 위치와 목적을 가진 정교한 파일 시스템으로 생각하십시오.
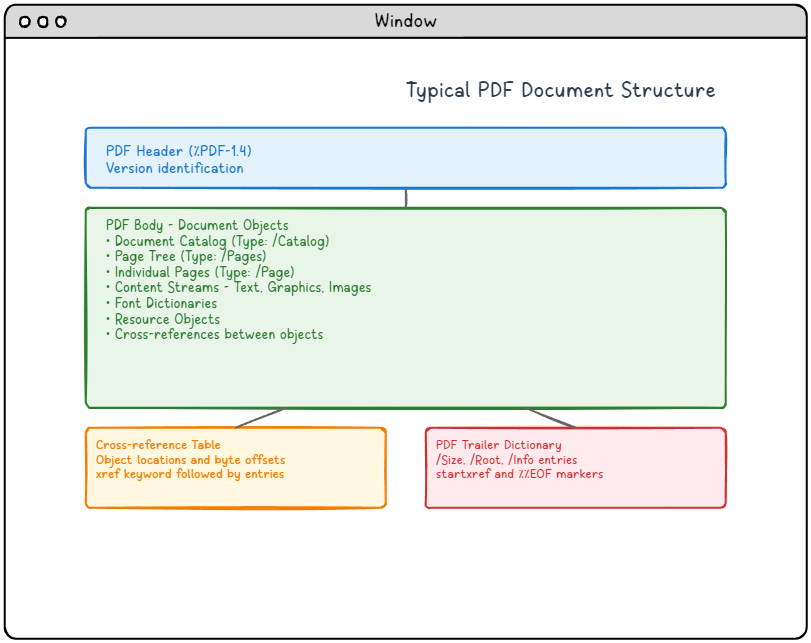
그림 1: 일반적인 PDF 문서 구조: 네 가지 주요 구성 요소와 그 관계를 보여줍니다.
PDF 구조 다이어그램에 대한 자세한 설명:
이 다이어그램은 PDF 문서의 일반적인 구조를 보여주며, 네 가지 주요 구성 요소가 수직으로 배열되어 있습니다.
-
- PDF 헤더 (상단 파란색 영역): PDF 버전 정보 (%PDF-1.4)가 포함되어 있으며, 이는 PDF 파일의 버전 정보를 나타냅니다.
- PDF 본문 (중앙의 녹색 영역): 문서의 모든 객체를 포함하는 가장 큰 영역이며, 여기에는 문서 카탈로그, 페이지 트리, 개별 페이지, 텍스트/그래픽/이미지가 포함된 콘텐츠 스트림, 폰트 사전, 리소스 객체 및 객체 간의 교차 참조가 포함됩니다.
- 교차 참조 테이블 (왼쪽 하단의 주황색 영역): 객체의 위치 및 바이트 오프셋을 포함하며, "xref" 키워드로 시작하고 그 뒤에 항목들이 나옵니다.
- PDF 트레일러 사전 (오른쪽 하단의 빨간색 영역): 필수적인 탐색 정보를 포함하며, 여기에는 "/Size", "/Root", "/Info" 항목이 포함되어 있으며, "startxref" 및 "%%EOF" 마커로 끝납니다.
화살표는 헤더에서 본문으로의 논리적 흐름을 보여주며, 이후 교차 참조 테이블과 트레일러 사전으로 분기되어 PDF 리더가 문서 구조를 탐색하는 방식을 설명합니다.
PDF 문서는 조화롭게 작동하는 네 가지 주요 구조 요소로 구성됩니다.
🏗️ PDF 구조의 네 가지 핵심 요소:
- 헤더 – PDF 버전 및 기능을 식별합니다.
- 본문 – 모든 문서 객체(텍스트, 이미지, 글꼴 등)를 포함합니다.
- 교차 참조 테이블 – 개체 위치를 매핑하여 빠른 접근을 제공합니다.
- 트레일러 – 문서를 탐색하기 위한 진입점을 제공합니다.
이 구조는 PDF가 모든 크기의 문서를 처리하는 데 놀라운 효율성을 갖도록 합니다. 간단한 1페이지 편지부터 수천 페이지의 방대한 기술 매뉴얼까지 가능합니다.
🗂️ 트레일러 딕셔너리: PDF의 GPS 시스템
카탈로그 시스템 없이 도서관을 탐색하려고 상상해 보세요. 혼란이 발생할 것입니다! 트레일러 딕셔너리는 PDF의 정교한 탐색 시스템으로, PDF 리더가 문서를 이해하고 표시하는 데 필요한 필수적인 지도를 제공합니다.
PDF 파일의 맨 뒤에 위치한 트레일러 딕셔너리는 역설적으로 PDF를 열 때 처리되는 첫 번째 요소 중 하나입니다. 이 딕셔너리에는 소프트웨어가 문서의 모든 다른 구성 요소를 찾고 해석할 수 있도록 하는 중요한 정보가 포함되어 있습니다.
🔑 트레일러 딕셔너리의 필수 항목
| Key | Type | Purpose | Required? |
|---|---|---|---|
/Size |
Integer | Total entries in cross-reference table (usually objects + 1) | ✅ Yes |
/Root |
Indirect Reference | Points to the document catalog—the master control center | ✅ Yes |
/Info |
Indirect Reference | Links to document metadata (title, author, creation date) | ❌ Optional |
/ID |
Array of Strings | Unique document identifier for workflow management | ❌ Optional |
💡 팁: PDF ID 이해하기
The /ID 배열에는 두 개의 문자열이 포함됩니다. 첫 번째는 문서가 생성될 때 설정되며 변경되지 않으며, 두 번째는 문서가 수정될 때마다 업데이트됩니다. 이 이중 식별자 시스템은 정교한 문서 관리 워크플로우를 가능하게 합니다.
📄 실제 트레일러 사전 예제:
|
1 2 3 4 5 6 |
<< /Size 421 /Root 377 0 R /Info 375 0 R /ID [<5sazn0fs3tamppia2izf569h281104ae> <6cig0wa61ti593bzuwy41905tr6s5c5a>] >> |
이 예제는 421개의 객체를 가진 문서의 트레일러를 보여주며, 여기서 객체 377은 문서 카탈로그 역할을 하고 객체 375에는 문서 정보가 포함되어 있습니다.
📊 문서 정보 사전: 기존 PDF 메타데이터
문서 정보 사전에는 파일의 생성 및 수정 날짜와 함께 몇 가지 간단한 메타데이터가 포함되어 있습니다. 이것은 이전 PDF 버전에서 사용되는 기존 메타데이터 시스템이며, 향후 기사에서 다룰 더 포괄적인 XMP 메타데이터와 혼동해서는 안 됩니다.
이 사전을 기본적인 도서관 카드 카탈로그 항목으로 생각하십시오. 문서를 표시하는 데 필수적이지는 않지만, 간단한 텍스트 문자열을 사용하여 문서의 기원 및 역사에 대한 기본적인 정보를 제공합니다.
📋 문서 정보 필드
| Key | Data Type | Description | Example |
|---|---|---|---|
/Title |
Text String | Document title (separate from any visible title) | “Annual Report 2024” |
/Subject |
Text String | Document subject or description | “Financial Performance Analysis” |
/Keywords |
Text String | Searchable keywords | “finance, quarterly, revenue” |
/Author |
Text String | Document creator | “Jane Smith” |
/Creator |
Text String | Original application that created the document | “Microsoft Word” |
/Producer |
Text String | Application that converted to PDF | “Adobe Acrobat” |
/CreationDate |
Date String | When the document was originally created | D:20240625132712+08’00’ |
/ModDate |
Date String | Last modification timestamp | D:20240626094530+08’00’ |
주의: 중요한 구별
The /Creator 그리고 /Producer fields는 서로 다른 목적을 수행합니다. Creator는 원래 작성 애플리케이션(예: Microsoft Word)을 식별하고, Producer는 최종 PDF를 생성한 소프트웨어(예: Adobe Acrobat 또는 PDF 프린터 드라이버)를 식별합니다.
문서 정보 사전:
|
1 2 3 4 5 6 7 8 9 10 |
<< /ModDate (D:20060926213913+02'00') /CreationDate (D:20060926213913+02'00') /Title (Product Catalog - UK Edition) /Creator (QuarkXPress: pictwpstops filter 1.0) /Producer (Acrobat Distiller 6.0 for Macintosh) /Author (James Smith) /Subject (Quarterly Product Showcase) /Keywords (products, catalog, prices, specifications) >> |
문서 카탈로그: 마스터 제어 센터
트레일러 사전이 PDF의 GPS 시스템이라면, 문서 카탈로그는 중앙 제어 센터입니다. 문서 그래프의 루트 객체로서, 카탈로그는 다른 모든 객체 간의 관계와 문서가 뷰어 또는 프린터로 표시될 때의 동작을 조정합니다.
PDF 문서의 모든 객체는 문서 카탈로그에서 시작하여 직접 또는 간접 참조를 통해 접근할 수 있습니다. 이러한 중앙 집중식 접근 방식은 효율적인 탐색을 보장하고 문서의 무결성을 유지합니다.
필수 카탈로그 항목
| Key | Type | Purpose | Required? |
|---|---|---|---|
/Type |
Name | Must be /Catalog |
✅ Yes |
/Pages |
Indirect Reference | Root of the page tree structure | ✅ Yes |
/PageLabels |
Number Tree | Enables complex page numbering (i, ii, iii, 1, 2, 3) | ❌ Optional |
/Names |
Dictionary | Name trees for referencing objects by name | ❌ Optional |
/Dests |
Dictionary | Named destinations for hyperlinks | ❌ Optional |
/ViewerPreferences |
Dictionary | Controls PDF viewer behavior | ❌ Optional |
/PageMode |
Name | Default viewing mode (thumbnails, bookmarks, etc.) | ❌ Optional |
/PageLayout |
Name | Page display layout (single, facing pages, etc.) | ❌ Optional |
/Outlines |
Indirect Reference | Document bookmarks/outline structure | ❌ Optional |
/Metadata |
Indirect Reference | XMP metadata stream | ❌ Optional |
뷰어 기본 설정: 사용자 경험 제어
The /ViewerPreferences dictionary는 문서 작성자가 PDF 뷰어가 문서를 표시하는 방식을 제어할 수 있도록 합니다. 여기에는 도구 모음 숨기기, 페이지를 창에 맞추기 또는 심지어 인쇄 설정 제어 등이 포함될 수 있습니다.
📚 페이지 모드 옵션 설명
- /UseNone – 문서만 표시, 탐색 패널은 표시하지 않음
- /UseOutlines – 북마크 패널 표시
- /UseThumbs – 페이지 축소 그림 표시
- /FullScreen – 발표 모드 진입
- /UseOC – 선택적 콘텐츠(레이어) 패널 표시
- /UseAttachments – 첨부 파일 패널 표시
🌳 페이지 및 페이지 트리: 콘텐츠를 효율적으로 구성하기
PDF의 가장 훌륭한 설계 결정 중 하나는 페이지를 구성하는 방식입니다. 단순한 선형 목록 대신, PDF는 트리 구조를 사용하여 성능을 크게 향상시키며, 특히 대용량 문서에서 더욱 그렇습니다.
1000페이지 분량의 문서에서 특정 페이지를 순차적으로 확인하여 찾는다고 상상해 보세요. 최대 1000번의 작업이 필요할 수 있습니다! 페이지 트리 구조는 이를 몇 번의 작업으로 줄여주어 PDF 뷰어가 엄청난 양의 문서에서도 매우 빠르게 작동할 수 있도록 합니다.
🏗️ 페이지 딕셔너리 구조 이해
PDF의 각 페이지는 페이지 딕셔너리로 표현되며, 해당 페이지를 렌더링하는 데 필요한 모든 요소(콘텐츠 지침, 리소스(글꼴, 이미지), 레이아웃 사양)를 포함합니다.
| Key | Type | Purpose | Inheritance |
|---|---|---|---|
/Type |
Name | Must be /Page |
❌ |
/Parent |
Indirect Reference | Parent node in page tree | ❌ |
/Resources |
Dictionary | Fonts, images, other resources | ✅ From parent if missing |
/Contents |
Stream/Array | Page content instructions | ❌ |
/MediaBox |
Rectangle | Physical page size | ✅ From parent if missing |
/CropBox |
Rectangle | Visible page area | ✅ Defaults to MediaBox |
/Rotate |
Integer | Page rotation (0, 90, 180, 270) | ✅ From parent if missing |
📐 PDF 좌표 시스템 이해
PDF는 네 개의 숫자로 정의된 사각형을 기반으로 하는 정교한 좌표 시스템을 사용합니다. 이 시스템을 이해하는 것은 페이지 레이아웃 작업을 수행하는 데 중요합니다.
📏 사각형 정의 예시:
|
1 2 |
/MediaBox [0 0 595 842] # A4 size in points (8.27" × 11.69") /CropBox [50 50 545 792] # A4 with 50-point margins on all sides |
💡 PDF 측정 단위
PDF는 기본 측정 단위로 포인트를 사용하며, 1 포인트 = 1/72 인치입니다. 이를 통해 계산이 간단해집니다. 예를 들어, 72 포인트 = 1 인치, 144 포인트 = 2 인치입니다.
🌲 페이지 트리 아키텍처
페이지 트리의 뛰어난 점은 균형 잡힌 구조에 있습니다. 좋은 PDF 애플리케이션은 문서 크기와 관계없이 모든 페이지를 몇 단계 만에 찾을 수 있는 트리를 생성합니다.
🌳 페이지 트리 아키텍처 예제
/Type /Pages
/Count 7
/Count 3
/Count 2
/Type /Page
/Type /Page
그림 2: 7페이지 분량 문서의 페이지 트리 구조, 효율적인 접근을 위한 균형 잡힌 계층 구조를 보여줍니다.
🎯 페이지 트리 성능상의 이점:
- 로그 시간 접근 – O(log n) 연산으로 모든 페이지를 찾을 수 있습니다.
- 효율적인 메모리 사용. – 큰 문서의 필요한 부분만 로드합니다.
- 확장 가능한 아키텍처. – 문서 크기가 증가해도 성능이 일관됩니다.
- 상속 최적화. – 페이지 그룹 간에 공통 속성을 공유합니다.
📝 페이지 트리 노드 구조.
| Key | Type | Purpose |
|---|---|---|
/Type |
Name | Must be /Pages |
/Kids |
Array | References to child nodes (pages or page trees) |
/Count |
Integer | Total number of leaf pages under this node |
/Parent |
Reference | Parent node (required unless root) |
🏗️ 페이지 트리 구현 예제:
|
1 2 3 4 5 6 7 8 |
1 0 obj % Root node << /Type /Pages /Kids [2 0 R 3 0 R 4 0 R] /Count 7 >> endobj 2 0 obj % Intermediate node << /Type /Pages /Kids [5 0 R 6 0 R 7 0 R] /Parent 1 0 R /Count 3 >> endobj 5 0 obj % Actual page << /Type /Page /Parent 2 0 R /MediaBox [0 0 612 792] /Resources << >> >> endobj |
🔤 텍스트 문자열: 다양한 인코딩 처리
PDF의 전 세계적인 사용 범위는 강력한 텍스트 처리 기능을 필요로 합니다. 이 형식은 다양한 언어와 문자 세트를 지원하기 위해 여러 인코딩 방식을 지원하며, 이를 통해 사용자의 로케일과 관계없이 문서가 올바르게 표시되도록 합니다.
PDF 텍스트 인코딩을 이해하는 것은 국제 문서 작업을 하거나 PDF 처리 응용 프로그램을 개발하는 모든 사람에게 중요합니다.
📝 주요 인코딩 방법 2가지
1. PDFDocEncoding
PDFDocEncoding은 ISO Latin-1을 기반으로 하며, 대부분의 서유럽 언어를 효율적으로 처리합니다. PDF 텍스트 문자열의 기본 인코딩이며, 기존 시스템과의 호환성이 뛰어납니다.
2. Unicode (UTF-16BE)
국제 문자 및 복잡한 스크립트의 경우, PDF는 UTF-16BE 인코딩을 사용하는 Unicode를 사용합니다. Unicode 문자열은 시작 부분에 특별한 바이트 순서 마커(BOM)가 있습니다.
🔍 유니코드 문자열 감지
PDF 뷰어는 텍스트 문자열의 처음 두 바이트를 검사하여 인코딩을 결정합니다.
|
1 2 3 4 |
If bytes[0] == 254 AND bytes[1] == 255: encoding = "UTF-16BE" # Unicode byte-order marker U+FEFF else: encoding = "PDFDocEncoding" # Default PDF encoding |
⚠️ 인코딩 제약
유니코드 감지 메커니즘으로 인해 PDFDocEncoding 문자열은 바이트 시퀀스 [254, 255] (þÿ)로 시작할 수 없습니다. 그러나 이 제한은 실제 문서에 거의 영향을 미치지 않습니다.
📅 날짜 형식: 정확한 시간 정보
PDF는 정교한 날짜 형식을 사용하여 발생 시점뿐만 아니라 시간대까지 고려합니다. 이는 글로벌 문서 워크플로우 및 법적 요구 사항에 매우 중요합니다.
📋 PDF 날짜 형식 구조
|
1 |
(D:YYYYMMDDHHmmSSOHH'mm') |
| Component | Meaning | Format | Example |
|---|---|---|---|
| YYYY | Year | Four digits | 2025 |
| MM | Month | 01-12 | 06 (June) |
| DD | Day | 01-31 | 25 |
| HH | Hour | 00-23 | 13 (1 PM) |
| mm | Minute | 00-59 | 27 |
| SS | Second | 00-59 | 12 |
| O | UTC Offset | +, -, or Z | + (later than UTC) |
| HH’ | Offset Hours | 00-23 | 08 (8 hours) |
| mm’ | Offset Minutes | 00-59 | 00 (no minutes) |
🌍 시간대 예시
|
1 2 3 |
(D:20250625132712+08'00') # June 25, 2024, 1:27:12 PM, UTC+8 (Beijing) (D:20250625132712-05'00') # Same moment in Eastern Standard Time (D:20250625132712Z) # Same moment in UTC (Zulu time) |
🕐 유연한 날짜 정밀도
PDF 날짜는 가변 정밀도를 지원합니다. 연도만 지정할 수 있습니다. (D:2025)또는 초 단위의 정확한 시간 정보와 시간대를 포함할 수 있습니다. 누락된 구성 요소는 합리적인 기본값으로 설정됩니다 (월/일은 01, 시간 구성 요소는 00).
🧩 모든 것을 함께 엮어보기: 완벽한 예제
다음은 지금까지 논의한 모든 개념을 보여주는 완벽하고 수동으로 제작된 PDF 예제입니다. 이 세 페이지 분량의 문서는 PDF의 모든 구조 요소 간의 상호 작용을 보여줍니다.
📄 완전한 PDF 구조 예제:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
%PDF-1.0 % Header 1 0 obj % Document catalog << /PageLayout /TwoColumnLeft /Pages 2 0 R /Type /Catalog >> endobj 2 0 obj % Root of page tree << /Kids [3 0 R 4 0 R] /Type /Pages /Count 3 >> endobj 3 0 obj % Page one << /Type /Page /Parent 2 0 R /MediaBox [0 0 612 792] % US Letter size /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [5 0 R] >> endobj 4 0 obj % Intermediate page tree node << /Parent 2 0 R /Kids [6 0 R 7 0 R] /Count 2 /Type /Pages >> endobj 5 0 obj % Content stream for page one << /Length 58 >> stream BT /F0 24 Tf 50 750 Td (Hello, PDF World!) Tj ET endstream endobj 6 0 obj % Page two << /Type /Page /Parent 4 0 R /MediaBox [0 0 612 792] /Rotate 90 % Landscape orientation /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [8 0 R] >> endobj 7 0 obj % Page three << /Type /Page /Parent 4 0 R /MediaBox [0 0 612 792] /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [9 0 R] >> endobj 8 0 obj % Content stream for page two << /Length 72 >> stream BT /F0 18 Tf 50 700 Td (This page is rotated 90 degrees) Tj ET endstream endobj 9 0 obj % Content stream for page three << /Length 45 >> stream BT /F0 24 Tf 50 750 Td (Final page) Tj ET endstream endobj 10 0 obj % Document information dictionary << /Title (PDF Structure Example) /Author (PDF Guide Author) /Producer (Manual Creation) /CreationDate (D:20240625132712+08'00') /ModDate (D:20240625133045+08'00') /Subject (Demonstrating PDF internal structure) /Keywords (PDF, structure, example, tutorial) >> endobj xref % Cross-reference table 0 11 0000000000 65535 f 0000000015 00000 n 0000000074 00000 n 0000000120 00000 n 0000000355 00000 n 0000000415 00000 n 0000000522 00000 n 0000000747 00000 n 0000000958 00000 n 0000001079 00000 n 0000001173 00000 n trailer % Trailer dictionary << /Size 11 /Root 1 0 R /Info 10 0 R /ID [<A1B2C3D4E5F6789012345678901234AB> <A1B2C3D4E5F6789012345678901234AB>] >> startxref 1456 %%EOF |
🗺️ 객체 참조 그래프
/Size 11
/Root 1 0 R → Document Catalog
/Info 10 0 R → Document Info
/Type /Catalog
/Pages 2 0 R
/Title /Author
/CreationDate /ModDate
/Type /Pages
/Kids [3 0 R 4 0 R]
/Count 3
/Type /Page
/Contents [5 0 R]
/Kids [6 0 R 7 0 R]
/Count 2
/Contents [8 0 R]
/Rotate 90
/Contents [9 0 R]
그림 3: 트레일러 딕셔너리가 모든 문서 구성 요소와 연결되는 객체 참조 그래프
🔍 예제 구조 분석
🎯 주요 관찰 사항:
- 효율적인 탐색 – 루트에서 최대 2단계 이내에 모든 페이지에 접근 가능
- 리소스 상속 – 글꼴 리소스는 부모 노드에서 상속될 수 있음
- 유연한 레이아웃 – 2페이지에서는 회전 기능을 보여줍니다.
- 풍부한 메타데이터 – 워크플로우 관리를 위한 문서 정보 제공.
- 고유 식별 – ID 배열을 사용하여 문서 추적을 지원합니다.
🚀 고급 주제 및 모범 사례
🔧 최적화 전략
📈 성능 최적화 팁:
- 균형 트리 – 대용량 문서에 대한 로그 시간 접근 속도 유지
- 리소스 공유 – 공통 리소스를 부모 페이지 트리 노드에 배치
- 효율적인 인코딩 – 서양 문자에는 PDFDocEncoding을 사용하고, 필요한 경우에만 Unicode을 사용
- 적절한 상속 – 공통 속성을 위해 페이지 트리 상속을 활용
- 최소한의 메타데이터 – 필요한 정보만 포함하는 사전 항목
🛡️ 오류 방지 및 유효성 검사
⚠️ 흔히 발생하는 문제점:
- 깨진 참조 – 모든 간접 참조가 유효한 객체를 가리키도록 확인
- 일관성 없는 개수 – 페이지 트리 개수는 실제 리프 페이지 개수를 정확하게 반영해야 함
- 필수 필드 누락 – 필수 사전 항목을 항상 포함해야 합니다.
- 잘못된 날짜 형식 – 정확한 날짜 형식 사양을 준수해야 합니다.
- 인코딩 불일치 – Unicode 및 PDFDocEncoding 문자열을 올바르게 식별해야 합니다.
🔮 향후 고려 사항
PDF가 계속 발전함에 따라 이러한 기본 구조를 이해하는 것이 점점 더 중요해집니다. 디지털 서명, 접근성 태그 및 대화형 양식과 같은 최신 PDF 기능은 우리가 살펴본 견고한 기반 위에 구축됩니다.
🌟 떠오르는 PDF 기술:
- PDF/A 표준 – 장기 보존 형식
- PDF/UA 접근성 – 보편적인 접근성 준수
- 대화형 양식 – 동적 콘텐츠 및 사용자 상호 작용
- 디지털 서명 암호화된 문서 무결성
- 3D 콘텐츠 3차원 모델 임베딩
🎯 결론: PDF 구조 마스터하기
PDF의 내부 구조를 이해하면 고급 문서 처리, 문제 해결 및 최적화를 위한 새로운 가능성이 열립니다. 트레일러 딕셔너리의 탐색 기능부터 페이지 트리의 효율적인 구성까지, 모든 구성 요소는 우리가 매일 사용하는 강력하고 이식 가능한 문서를 만드는 데 중요한 역할을 합니다.
🏆 주요 내용:
- 계층적 설계 PDF의 트리 기반 구조는 효율적인 확장을 가능하게 합니다.
- 스마트 내비게이션 – 교차 참조 테이블 및 사전은 빠른 접근을 제공합니다.
- 유연한 인코딩 – 다양한 텍스트 인코딩을 지원하여 글로벌 문서 교환이 가능합니다.
- 풍부한 메타데이터 – 포괄적인 정보 추적 기능은 복잡한 워크플로우를 지원합니다.
- 상속 모델 – 리소스 공유는 중복을 줄이고 파일 크기를 줄입니다.
"PDF의 아름다움은 복잡성에 있는 것이 아니라, 그 복잡성이 어떻게 단순한 목표인 보편적인 문서 호환성을 위해 우아하게 구성되었는지에 있습니다."
이 포괄적인 PDF 구조 탐색은 세계에서 가장 중요한 문서 형식 중 하나인 기술적인 측면을 명확히 하기 위한 것입니다. 이러한 내부 구조를 이해하면 개발자, 문서 관리자 및 호기심 많은 사람들이 PDF 기술을 더 효과적으로 사용할 수 있습니다. 다음을 사용하는 것이 좋습니다. 성숙한 PDF 개발 라이브러리 를 사용하여 PDF 처리 작업을 크게 단순화하십시오.