PDF テキストとフォントの処理: 開発者向けガイド
PDF のテキストは、画面に文字列を置くだけの仕組みではありません。文字間隔、単語間隔、水平スケール、行送り、ベースライン位置、フォント リソース、エンコーディングが組み合わさり、同じページを異なる環境でも再現できるように設計されています。
PDF を生成、解析、検索、変換するアプリケーションでは、このテキスト状態を理解しておくことが重要です。見た目が正しくても、フォント埋め込みや文字マッピングが不十分だと、検索できない、コピーすると文字化けする、印刷時に置き換わるといった問題が起こります。
PDF テキスト状態の基本
テキスト状態は、文字をどの位置に、どのサイズで、どの間隔で描画するかを決める一連のパラメーターです。PDF のコンテンツ ストリームでは、演算子を使ってこれらの値を変更し、その後に続く文字描画へ反映します。
- Tc は文字間隔を調整します。
- Tw は単語間隔を調整し、欧文の段落組みに影響します。
- Tz は水平方向の拡大率を指定します。
- TL は行送りを決め、複数行テキストの縦方向のリズムを作ります。
- Ts はベースラインからの上下移動を指定し、上付き文字や下付き文字に使えます。
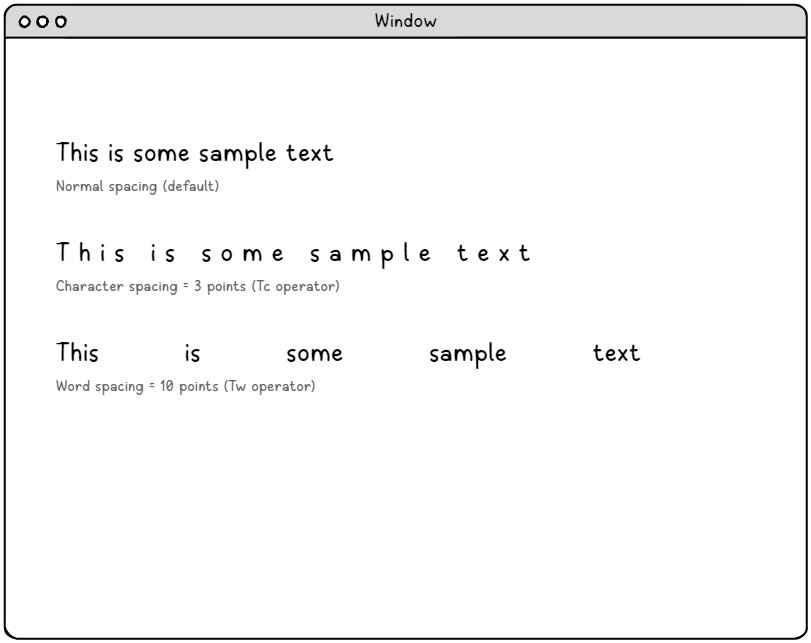
文字間隔と単語間隔
文字間隔と単語間隔を明示すると、見出しや表のラベルを精密に調整できます。
|
1 2 3 4 5 6 7 8 9 10 11 |
BT /F0 24 Tf 1 0 0 1 50 700 Tm (Normal text spacing) Tj 0 -30 Td 3 Tc (Character spacing = 3 points) Tj 0 -30 Td -1 Tc (Tight character spacing = -1 point) Tj ET |

ベースライン位置の調整
数式、化学式、注記では、テキスト ライズを使って同じ行内の文字を上下に移動します。
|
1 2 3 4 5 6 7 8 9 10 11 |
BT /F0 24 Tf 1 0 0 1 50 600 Tm (Normal word spacing) Tj 0 -30 Td 10 Tw (Extended word spacing improves readability) Tj 0 -30 Td -2 Tw (Compressed word spacing saves space) Tj ET |
変換行列と座標
PDF ではページ座標、現在の変換行列、テキスト行列が連携して文字の位置と向きを決めます。回転したラベル、斜めの透かし、縦方向の注記を扱うときは、グラフィックス状態とテキスト状態の両方を意識する必要があります。

テキスト変換
座標変換を局所化するため、保存と復元を組み合わせて描画範囲を明確にします。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
BT /F0 24 Tf 1 0 0 1 50 500 Tm 100 Tz (Normal horizontal scaling - 100%) Tj 0 -30 Td 80 Tz (Condensed text - 80% scaling) Tj 0 -30 Td 120 Tz (Extended text - 120% scaling) Tj ET |
フォント リソースと埋め込み
フォントはリソース辞書で名前を割り当てられ、コンテンツ ストリームから参照されます。ビューア側に同じフォントがない場合でも結果を安定させるには、フォント埋め込みやサブセット化が重要です。
- 標準フォントだけに依存する場合は互換性が高い一方、表現力は限られます。
- TrueType や OpenType を埋め込むと外観を安定させやすくなります。
- サブセット化はファイルサイズ削減に有効ですが、文字マッピングを正しく保持する必要があります。
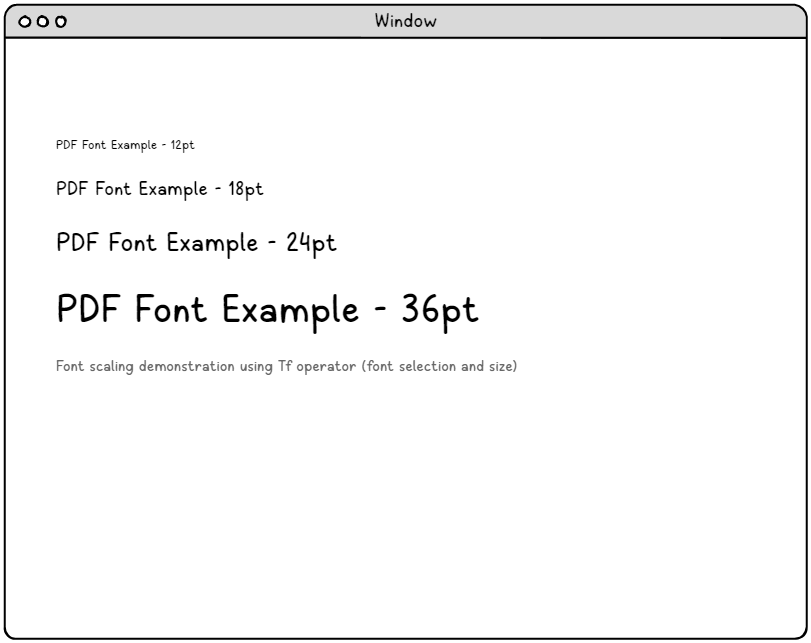
フォント選択
フォント名とサイズを切り替えながら、同じページ内で見出しと本文を描き分けます。
|
1 2 3 4 5 6 7 8 9 10 |
BT /F0 18 Tf 18 TL 1 0 0 1 50 400 Tm (This text uses 18pt leading) Tj T* (which matches the font size) Tj T* 24 TL (This text uses 24pt leading) Tj T* (providing more generous spacing) Tj T* ET |
カーニングとグリフ位置
TJ 配列を使うと、個々の文字やグリフの間隔を細かく調整できます。ロゴ、見出し、帳票の固定幅欄など、見た目の精度が重要な領域で役立ちます。

TJ 配列による間隔調整
配列内の数値でグリフ間隔を調整し、プロフェッショナルな組版に近づけます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
BT /F0 36 Tf 1 0 0 1 140 290 Tm (H) Tj -8 Ts /F0 24 Tf (2) Tj 0 Ts /F0 36 Tf (O represents water with O) Tj 8 Ts /F0 24 Tf (2) Tj 0 Ts /F0 36 Tf ( as oxygen) Tj ET |
テキスト抽出で注意すべき点
PDF のテキストは見た目の再現を優先して保存されるため、抽出順序が人間の読む順序と一致しないことがあります。列組み、回転文字、合字、カスタム エンコーディング、ToUnicode CMap の有無を確認することが、検索やデータ化の品質に直結します。
補足コード例 1
テキスト状態、フォント、抽出処理を検証するための関連コードです。
|
1 2 3 4 5 6 7 8 9 10 11 |
% Set up rotation transformation 0.96 0.25 -0.25 0.96 0 0 cm BT /F0 48 Tf 48 TL % Set text matrix for positioning 1 0 0 1 270 240 Tm (Text and graphics) Tj T* (transforms combined) Tj T* (with proper newlines) Tj ET |
補足コード例 2
テキスト状態、フォント、抽出処理を検証するための関連コードです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
BT % Select font and set initial size /F0 12 Tf 1 0 0 1 50 750 Tm (12-point font example) Tj % Change to larger size, same font /F0 18 Tf 0 -25 Td (18-point font example) Tj % Even larger size /F0 24 Tf 0 -35 Td (24-point font example) Tj % Largest size /F0 36 Tf 0 -50 Td (36-point font example) Tj ET |
補足コード例 3
テキスト状態、フォント、抽出処理を検証するための関連コードです。
|
1 2 3 4 5 6 7 8 9 |
BT /F0 48 Tf 1 0 0 1 100 400 Tm % Standard text rendering (WAVE Type) Tj 0 -60 Td % Kerned text with precise adjustments [(W) -120 (A) -80 (V) -100 (E) 50 (T) -20 (y) -10 (p) -5 (e)] TJ ET |
補足コード例 4
テキスト状態、フォント、抽出処理を検証するための関連コードです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
BT /F0 36 Tf 1 0 0 1 100 500 Tm % Standard filled text 0 Tr (Filled Text) Tj 0 -50 Td % Stroked text only 1 Tr 2 w (Stroked Text) Tj 0 -50 Td % Both filled and stroked 2 Tr (Filled and Stroked) Tj ET |
補足コード例 5
テキスト状態、フォント、抽出処理を検証するための関連コードです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
% Example ToUnicode CMap structure 23 0 obj << /Length 317 >> stream /CIDInit /ProcSet findresource begin 12 dict begin begincmap /CIDSystemInfo << /Registry (Adobe) /Ordering (UCS) /Supplement 0 >> def /CMapName /Adobe-Identity-UCS def 1 begincodespacerange <0001> endcodespacerange 2 beginbfchar <0001> <0041> % Map glyph 1 to Unicode U+0041 (A) <0002> <0042> % Map glyph 2 to Unicode U+0042 (B) endbfchar endcmap CMapName currentdict /CMap defineresource pop end end endstream endobj |
補足コード例 6
テキスト状態、フォント、抽出処理を検証するための関連コードです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
% Complex text positioning that challenges extraction BT /F0 12 Tf 1 0 0 1 72 720 Tm (This text appears) Tj 150 0 Td (out of order) Tj -150 -15 Td (in the content stream) Tj 200 0 Td (but should be) Tj -200 -15 Td (reconstructed properly) Tj 100 0 Td (by extraction algorithms.) Tj ET % Graphics elements that interrupt text flow q 1 0 0 1 100 650 cm 0.5 g 0 0 200 50 re f Q % Continuation of text after graphics BT /F0 12 Tf 1 0 0 1 72 630 Tm (Text continues after graphics elements) Tj ET |
実装のベストプラクティス
- フォント埋め込みと ToUnicode マップを確認する。
- テキスト描画時は座標変換を小さな範囲に閉じ込める。
- 生成後に検索、コピー、印刷、別ビューアでの表示を確認する。
- 抽出処理では描画順ではなく位置情報と構造情報を併用する。
PDF のテキスト処理を正しく扱うと、見た目だけでなく、検索性、アクセシビリティ、長期保存性も改善できます。