PDF作成における右から左へのテキスト表示:HotPDFのRtLTextOut関数をご紹介します。
右から左への言語の紹介。
右から左(RTL)の言語は、世界の書面によるコミュニケーションシステムにおいて重要な位置を占めており、世界中で4億人以上の人々に利用されています。これらの言語には、アラビア語、ヘブライ語、ペルシャ語(ファルシ語)、ウルドゥー語、パシュトゥー語などがあり、それぞれ独自の特性と文化的意義を持っています。
歴史的および文化的背景。
右から左の文字体系は、数千年前の古代に起源を持ちます。例えば、アラビア語はナバテア文字から発展し、初期のイスラム時代に標準化されました。ヘブライ語はさらに長い歴史を持ち、紀元前10世紀の古代ヘブライ文字の碑文が存在します。これらの文字体系は、ラテン文字に基づいた文字体系とは独立して発展し、書かれた情報を整理する異なるアプローチを反映しています。
RTL言語の言語学的特徴。
RTL言語は、デジタルテキスト処理に影響を与えるいくつかの独特な特徴を持っています。
- 文字の方向。テキストは右から左に表示され、ヨーロッパの言語とは逆です。
- 文脈に応じた文字の形状多くの右から左への文字体系では、文字の形状が位置(先頭、中間、末尾、独立)によって異なります。
- 接続文字文字はしばしば繋がり、連続した単語を形成するため、高度なレンダリングが必要です。
- アクセント記号母音記号などのアクセント記号は、基本文字の上または下に表示されます。
- 双向テキスト。RTL ドキュメントには、数字、ラテン文字のテキスト、URL などの LTR 要素が埋め込まれることがよくあります。
数字表記の課題と Unicode 標準
RTL 言語の数字表記には、独自の技術的課題があります。
- 文字エンコード。Unicode は RTL 文字に標準化されたコードポイントを提供します。
- 阿拉伯语:U+0600-U+06FF(阿拉伯语块)。
- 希伯来语:U+0590-U+05FF(希伯来语块)。
- 阿拉伯语补充:U+0750-U+077F。
- Arabic Extended-A: U+08A0-U+08FF
- 双方向アルゴリズム: Unicode 双方向アルゴリズム (UBA) は、混在する RTL/LTR テキストの処理方法を定義します。
- フォント要件: RTL テキストには、適切なグリフ範囲と字形処理機能を備えたフォントが必要です。
- 布局注意事项: ユーザーインターフェイスとドキュメントは、右から左への読書方向に対応する必要があります。
全球市场重要性
右から左(RTL)言語のサポートは、多様な市場で事業を行う企業や組織にとって重要です。
- 阿拉伯语地区:22 か国で 3 億人を超える母語話者がいます。
- 希伯来语市场:イスラエルおよび世界中のユダヤ人コミュニティ。
- 波斯语/波斯语:伊朗、阿富汗和塔吉克斯坦。
- 乌尔都语。:パキスタンおよびインドの一部地域。
- 経済への影響。RTL言語圏の合計GDPは4兆ドルを超えています。
現代のグローバル化が進む世界において、複数の言語と文字体系を適切にサポートするPDFドキュメントを作成することは、ますます重要になっています。 多くのPDF作成ライブラリは、英語、フランス語、ドイツ語などの左から右への言語(LTR)を容易に処理できますが、アラビア語やヘブライ語などの右から左への言語(RTL)をサポートするには、独自の課題があります。 本記事では、この革新的な RtLTextOut HotPDF Delphiコンポーネントの機能について説明し、包括的なデモアプリケーションを通じて、その具体的な実装方法を示します。
PDFファイルにおけるRTLテキストの問題について理解する。
右から左に記述する言語は、デジタル文書においていくつかの理由から特別な処理が必要です。
- 文字順序RTL テキストは右から左へ流れ、左から右へ書く言語とは逆です。
- 双向テキスト。ドキュメントには通常、RTL と LTR の内容が混在します。
- PDF ビューアーの動作PDF リーダーがテキストを正しく表示するには、適切な方向指定が必要です。
- Unicode複雑性。RTL 文字には特定の Unicode 範囲があり、検出して処理する必要があります。
従来の PDF 作成方法は RTL テキスト処理で失敗することが多く、文字順の反転、読書順序の誤り、認識できない出力につながる場合があります。
HotPDFのRtLTextOut関数をご紹介します。
HotPDFコンポーネントは、これらの課題を、高度な双方向テキスト処理アルゴリズムを実装した、洗練された機能によって解決します。 RtLTextOut 単純な文字反転アプローチとは異なり、 RtLTextOut は、混合RTL/LTRコンテンツをインテリジェントに処理するために、セグメントベースの処理を利用します。
関数シグネチャ
The RtLTextOut この関数は、最大限の柔軟性を提供するために、2つのオーバーロードバージョンを提供します。
|
1 2 3 4 5 |
// PWORD version for direct Unicode character array access procedure RtLTextOut(X, Y: Single; angle: Extended; Text: PWORD; TextLength: Integer); // WideString version for convenient string handling procedure RtLTextOut(X, Y: Single; angle: Extended; Text: WideString); |
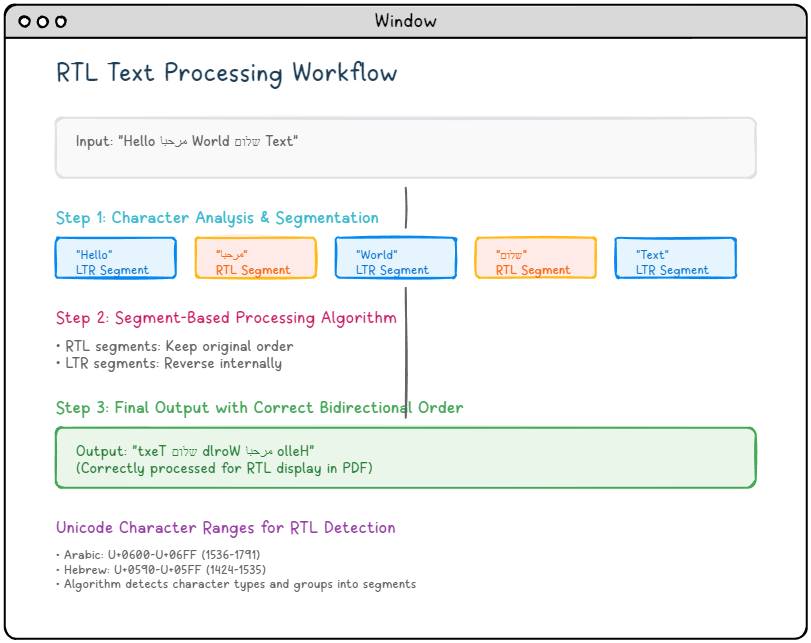
基本アルゴリズム:セグメントベース処理。
の核心は、セグメントベースの双方向アルゴリズムにあります。 RtLTextOut この関数は、単純な文字反転ではなく、以下の処理を行います。
- 文字の種類を分析します。: RTL文字(アラビア語:U+0600-U+06FF、ヘブライ語:U+0590-U+05FF)を識別します。
- テキストをセグメントに分割する: 同じ種類の連続する文字(RTLまたはLTR)をグループ化します。
- 選択的な処理を適用します。:
- RTLセグメントは、元の順序を維持します。
- LTR 段落の内部は反転されます。
- 正しい出力を生成する結果は次のパターンになります。
Reversed(C)+B+Reversed(A)段落に使用します。A+B+C
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
// Core segment processing logic I := 0; while I < TextLength do begin // Determine if current character starts an RTL or LTR segment IsRTLChar := ((ReversedText[I] >= $0600) and (ReversedText[I] <= $06FF)) or // Arabic ((ReversedText[I] >= $0590) and (ReversedText[I] <= $05FF)); // Hebrew CurrentSegmentIsRTL := IsRTLChar; SegmentStart := I; // Find the end of current segment (same character type) while (I < TextLength) do begin IsRTLChar := ((ReversedText[I] >= $0600) and (ReversedText[I] <= $06FF)) or ((ReversedText[I] >= $0590) and (ReversedText[I] <= $05FF)); if IsRTLChar <> CurrentSegmentIsRTL then Break; Inc(I); end; SegmentEnd := I - 1; // Process the segment if CurrentSegmentIsRTL then begin // RTL segment: keep original order for J := SegmentStart to SegmentEnd do OutputText[J] := ReversedText[J]; end else begin // LTR segment: reverse the segment internally for J := SegmentStart to SegmentEnd do OutputText[J] := ReversedText[SegmentEnd - (J - SegmentStart)]; end; end; |
PDF 方向の自動設定
テキスト処理に加えて、 RtLTextOut RTL 表示に適した状態になるよう、PDF ドキュメントを自動的に設定します。
|
1 2 3 4 5 |
// Store original direction and set to RightToLeft OriginalDirection := FParent.FDirection; FParent.FDirection := RightToLeft; FParent.FViewerPreference := FParent.FViewerPreference + [vpDirection]; FParent.FVPChanged := true; |
これにより、PDF ビューアーが正しい読書方向でドキュメントを開き、ユーザーに自然な閲覧体験を提供できます。
RtLTextOut デモアプリケーションの確認
HotPDF ライブラリには包括的なデモアプリケーション(Demo\Delphi\RtLTextOut\RtLTextOut.dpr)が含まれており、 RtLTextOut 関数がさまざまな場面でどのように機能するかを示しています。
デモ構造和機能
デモアプリケーションでは次の内容を確認できます。
- 基本的なアラビア語テキスト出力: シンプルな RTL テキスト描画
- ヘブライ文字のサポート: 包括的なヘブライ文字の処理
- : 混合言語コンテンツ: RTL/LTRテキストの組み合わせ
- 技術ドキュメント: 実装に関する注意点とベストプラクティス
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
program RtLTextOut; {$I ..\..\..\Lib\HotPDF.inc} {$APPTYPE CONSOLE} uses {$IFDEF XE2+} System.SysUtils, Vcl.Graphics, {$ELSE} SysUtils, Graphics, {$ENDIF} HPDFDoc; var HotPDF: THotPDF; begin try HotPDF := THotPDF.Create(nil); try HotPDF.FileName := 'RtLTextOut.pdf'; HotPDF.Title := 'RtLTextOut Function Test - Right-to-Left Text Output'; HotPDF.BeginDoc; // Title HotPDF.CurrentPage.SetFont('Arial', [fsBold], 18, 0, False); HotPDF.CurrentPage.TextOut(40, 50, 0, 'RtLTextOut Function Demonstration'); // Arabic text demonstration HotPDF.CurrentPage.SetFont('Arial Unicode MS', [], 12, 178, False); HotPDF.CurrentPage.TextOut(40, 160, 0, 'RtLTextOut:'); HotPDF.CurrentPage.RtLTextOut(40, 180, 0, 'يوضح ملف PDF هذا كيفية التعامل بشكل صحيح مع النص العربي من اليمين إلى اليسار.'); // Hebrew text demonstration HotPDF.CurrentPage.SetFont('Arial Unicode MS', [], 12, 177, False); HotPDF.CurrentPage.RtLTextOut(40, 370, 0, 'קובץ PDF זה מדגים כיצד לטפל כראוי בטקסט עברי הזורם מימין לשמאל.'); // Mixed text demonstration HotPDF.CurrentPage.RtLTextOut(40, 550, 0, 'مرحبا بالعالم! اكتب في مستندات PDF التي تم إنشاؤها بواسطة مكون HotPDF'); HotPDF.EndDoc; Writeln('RtLTextOut.pdf created successfully!'); finally HotPDF.Free; end; except on E: Exception do Writeln('Error: ', E.Message); end; end. |
主要なデモのハイライト
アラビア語テキスト処理: このデモでは、 RtLTextOut が、適切な文字フローと間隔で複雑なアラビア語の文をどのように処理するかを示しています。
: ヘブライ語サポート: ヘブライ語テキストの正しい右から左への表示方法を示します。
: 混合言語コンテンツ: この関数が、RTL(右から左)とLTR(左から右)の両方の要素を含むテキストをどのようにインテリジェントに処理するかを示します。
: フォント設定: 正しいUnicodeフォントの選択方法を示します(Arial Unicode MSRTL文字サポート用。
技術実装の詳細。
Unicode文字検出。
この関数は、堅牢なUnicode範囲検出を利用します。
- アラビア語。: U+0600からU+06FF (1536-1791十進法)。
- ヘブライ語。: U+0590からU+05FF (1424-1535十進法)。
メモリ管理
効率的な配列処理により、最適なパフォーマンスを実現します。
|
1 2 3 4 5 6 7 8 9 10 |
// Initialize arrays SetLength(ReversedText, TextLength); SetLength(OutputText, TextLength); // Copy original text first for I := 0 to TextLength - 1 do begin ReversedText[I] := TempText^; Inc(TempText); end; |
縦書きテキストのサポート
この機能には、縦書きフォントに特化した処理が含まれています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
if CurrentFontObj.IsVertical then begin DeltaH := TextHeight('Zj'); DeltaW := TextWidth('W'); HorizontalLine := Y; ChBuff := @ChCode; for I := 0 to TextLength - 1 do begin ChCode := OutputText[I]; if (ChCode = $30FC) then ChCode := $7C; InternUnicodeTextOut(X + (DeltaW / 2), HorizontalLine - DeltaH, 0, ChBuff, 1); HorizontalLine := HorizontalLine + DeltaH; end; end else InternUnicodeTextOut(X, Y, angle, @OutputText[0], TextLength); |
PDFにおける右から左(RTL)テキストのベストプラクティス
フォントの選択
ターゲットのRTL言語をサポートする、Unicode対応フォントを選択してください。
- Arial Unicode MS包括的な Unicode サポートを含みます。
- Times New Roman混在コンテンツに適しています。
- Tahoma優れたアラビア語サポートを備えています。
テキストエンコード。
ソースコード内のテキストで正しい Unicode エンコードを使用していることを確認します。
|
1 2 3 4 5 6 7 |
// Use WideString for Unicode text var ArabicText: WideString; begin ArabicText := 'النص العربي'; HotPDF.CurrentPage.RtLTextOut(X, Y, 0, ArabicText); end; |
PDF表示器兼容性。
自動方向設定により、さまざまな PDF リーダーとの互換性を確保できます。
- Adobe Acrobat Reader
- Foxit Reader
- Chrome PDF Viewer
- Firefox PDF Viewer
性能考量
セグメントベースのアルゴリズムは優れた性能特性を備えています。
- 線性時間複雜度: O(n) の処理時間
- : 最小限のメモリオーバーヘッド: 効率的な配列管理
- : 単一パス処理: 複数回の反復処理は不要
- : 最適化された文字検出: 高速な Unicode 範囲チェック
: 実世界での応用
ドキュメントのローカライズ
The RtLTextOut この機能により、右から左へ記述の言語市場向けに、シームレスなドキュメントローカライズが可能になります。
- アラビア語の法的文書
- ヘブライ語の技術マニュアル
- 多言語対応のフォームと契約書
- 教育資料
国際ビジネス
右から左へ記述の言語市場で事業を展開する企業は、この機能を活用して以下を行うことができます。
- 請求書発行
- レポート作成
- 証明書印刷
- マーケティング資料
よくある問題のトラブルシューティング
文字エンコーディングの問題
Issue: 文字化けまたは文字の欠落
Solution: 正しいUnicodeエンコーディングとフォントの選択を確認してください
|
1 2 3 4 5 |
// Correct approach HotPDF.CurrentPage.SetFont('Arial Unicode MS', [], 12, 178, False); var Text: WideString := 'النص العربي'; HotPDF.CurrentPage.RtLTextOut(X, Y, 0, Text); |
表示方向の問題
Issue: テキストが間違った方向に表示される
Solution: 確認してください RtLTextOut が通常の代わりに利用されているか TextOut
Mixed Content Problems
Issue: 混合 RTL/LTR テキスト内の順序エラー
Solutionセグメントベースのアルゴリズムにより、この問題を自動的に処理できます
Future Enhancements and Roadmap
HotPDF 開発チームは RTL サポートを引き続き強化します。
- Extended Language Support追加の右から左への言語サポート
- 複雑な文字スクリプトの処理高度なタイポグラフィ機能
- 性能最適化さらなる速度向上
- 強化されたデバッグ機能より優れた診断ツール
总结
The RtLTextOut HotPDFのfunctionは、右から左に記述される言語(RTL言語)向けのPDF作成技術において、大きな進歩をもたらします。この高度なセグメントベースの処理アルゴリズムと、自動PDF設定機能を組み合わせることで、開発者は真に国際的なPDFドキュメントを作成するための強力なツールを手に入れることができます。
この包括的なデモアプリケーションは、学習リソースとしてだけでなく、実践的な実装ガイドとしても機能し、実際のシナリオにおけるRTLテキスト処理のベストプラクティスを示しています。アラビア語圏の市場向けのアプリケーション開発、ヘブライ語のドキュメント作成、または多言語システムの構築など、あらゆる状況で役立ちます。 RtLTextOut この関数は、プロフェッショナル品質のPDF作成に必要な、堅牢な基盤を提供します。
これらの技術を理解して実装することで、開発者はグローバルな利用者に適した PDF ドキュメントを作成できます。言語の壁を越え、どの文字体系でも読みやすく利用しやすいコンテンツを提供できます。
HotPDFとその高度な機能の詳細については、公式ドキュメントを参照するか、このコンポーネントに含まれる包括的なデモアプリケーションをご覧ください。