Comprendere la struttura interna dei file PDF.
Benvenuti nel fantastico mondo dell'architettura interna dei file PDF! Vi siete mai chiesti cosa rende un file PDF così com'è? Oltre ai documenti familiari che visualizziamo quotidianamente, esiste un'architettura sofisticata che ha rivoluzionato la condivisione di documenti digitali. In questa esplorazione completa, analizzeremo la struttura dei file PDF, rivelando i meccanismi complessi che li fanno funzionare.
🔍 Introduzione: Oltre la superficie.
Il formato PDF (Portable Document Format) è diventato lo standard per lo scambio di documenti in tutto il mondo. Dai semplici documenti di testo ai complessi moduli interattivi, i file PDF mantengono un aspetto coerente su diverse piattaforme e dispositivi. Ma cosa si nasconde dietro questa compatibilità universale?
In questa analisi approfondita, esploreremo la struttura logica che rende i file PDF veramente portatili. Esamineremo i componenti fondamentali: il dizionario del trailer, catalogo del documento.e albero delle pagine—il triumvirato che orchestra tutte le funzionalità di un file PDF. Inoltre, scopriremo i segreti dei formati di dati specializzati di PDF per stringhe di testo e date.
🎯 Cosa imparerai in questa guida:
- I quattro componenti fondamentali della struttura di un file PDF.
- Come PDF organizza e fa riferimento ai contenuti in modo efficiente.
- Il ruolo dei dizionari, dei cataloghi e degli alberi delle pagine.
- Gli approcci unici di PDF alla codifica del testo e alla formattazione delle date.
- Esempi pratici delle strutture degli oggetti PDF.
- Best practice per comprendere il funzionamento interno dei PDF.
📋 L'anatomia di un PDF: panoramica generale.
Prima di approfondire i dettagli, definiamo un modello mentale della struttura dei PDF. Considera un PDF come un sistema di archiviazione sofisticato in cui ogni informazione ha un posto e uno scopo specifici.
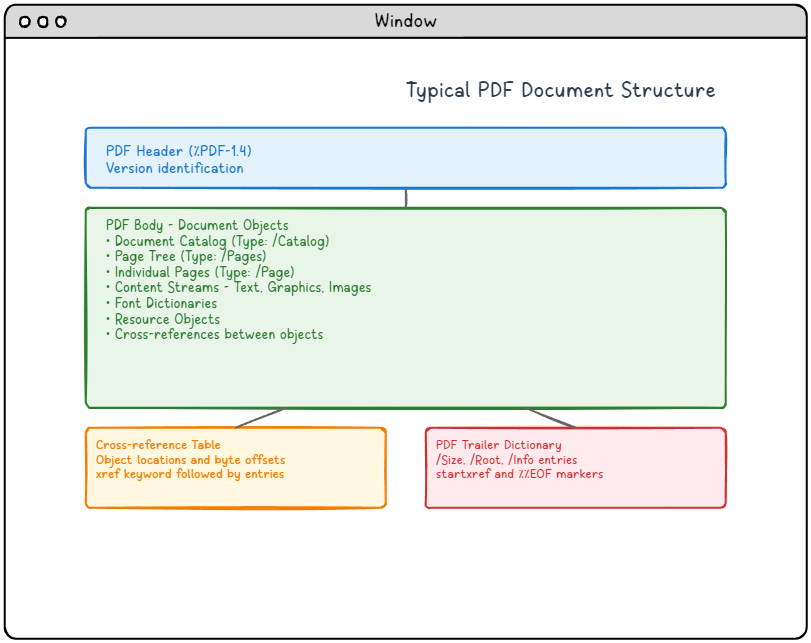
Figura 1: Struttura tipica di un documento PDF che mostra i quattro componenti principali e le loro relazioni.
Descrizione dettagliata del diagramma della struttura del PDF:
Questo diagramma illustra la struttura tipica di un documento PDF con quattro componenti principali disposti verticalmente:
-
- Intestazione PDF (sezione blu in alto): Contiene l'identificazione della versione (%PDF-1.4) che specifica la versione del formato PDF.
- Corpo PDF (sezione verde nella parte centrale): La sezione più grande che contiene tutti gli oggetti del documento, inclusi il catalogo del documento, l'albero delle pagine, le singole pagine, i flussi di contenuto con testo/grafica/immagini, i dizionari dei font, gli oggetti delle risorse e i riferimenti incrociati tra gli oggetti.
- Tabella dei riferimenti incrociati (sezione arancione nell'angolo in basso a sinistra): Contiene le posizioni degli oggetti e gli offset dei byte, contrassegnati con la parola chiave xref seguita dalle voci.
- Dizionario del trailer PDF (sezione rossa nell'angolo in basso a destra): Contiene informazioni di navigazione essenziali, tra cui le voci /Size, /Root, /Info, e termina con i marcatori startxref e %%EOF.
Le frecce mostrano il flusso logico dall'intestazione al corpo, quindi si diramano sia alla tabella di riferimento incrociato che al dizionario del trailer, illustrando come i lettori PDF navigano nella struttura del documento.
Un documento PDF è composto da quattro elementi strutturali principali che lavorano in armonia:
🏗️ I Quattro Pilastri della Struttura PDF:
- Intestazione – Identifica la versione e le funzionalità del PDF.
- Corpo – Contiene tutti gli oggetti del documento (testo, immagini, font, ecc.).
- Tabella di riferimento incrociato. – Mappa le posizioni degli oggetti per un accesso rapido.
- Trailer – Fornisce il punto di accesso per navigare nel documento.
Questa struttura consente a PDF di gestire in modo efficiente documenti di qualsiasi dimensione, dalle semplici lettere di una pagina a massicci manuali tecnici con migliaia di pagine.
🗂️ Il dizionario Trailer: il sistema GPS del tuo PDF.
Immagina di cercare di navigare in una biblioteca senza un sistema di catalogazione: si creerebbe il caos! Il dizionario trailer funge da sofisticato sistema di navigazione di PDF, fornendo la mappa essenziale che i lettori di PDF utilizzano per comprendere e visualizzare il tuo documento.
Situato proprio alla fine del file PDF, il dizionario trailer è paradossalmente una delle prime cose elaborate quando si apre un PDF. Contiene le informazioni cruciali che consentono al software di localizzare e interpretare tutti gli altri componenti del documento.
🔑 Voci essenziali nel dizionario Trailer.
| Key | Type | Purpose | Required? |
|---|---|---|---|
/Size |
Integer | Total entries in cross-reference table (usually objects + 1) | ✅ Yes |
/Root |
Indirect Reference | Points to the document catalog—the master control center | ✅ Yes |
/Info |
Indirect Reference | Links to document metadata (title, author, creation date) | ❌ Optional |
/ID |
Array of Strings | Unique document identifier for workflow management | ❌ Optional |
Suggerimento: Comprendere gli ID PDF.
Il /ID L'array contiene due stringhe: la prima viene impostata quando il documento viene creato e non cambia mai, mentre la seconda viene aggiornata ogni volta che il documento viene modificato. Questo sistema di identificazione duale consente flussi di lavoro avanzati per la gestione dei documenti.
Esempio pratico di dizionario dei trailer:
|
1 2 3 4 5 6 |
<< /Size 421 /Root 377 0 R /Info 375 0 R /ID [<5sazn0fs3tamppia2izf569h281104ae> <6cig0wa61ti593bzuwy41905tr6s5c5a>] >> |
Questo esempio mostra un trailer per un documento con 421 oggetti, in cui l'oggetto 377 funge da catalogo del documento e l'oggetto 375 contiene le informazioni sul documento.
Dizionario delle informazioni sul documento: Metadati PDF tradizionali.
Il dizionario delle informazioni sul documento contiene le date di creazione e modifica del file, insieme ad alcune semplici metadati. Questo è il sistema di metadati tradizionale utilizzato nelle versioni precedenti di PDF, da non confondere con i metadati XMP più completi che saranno discussi in articoli futuri.
Considera questo dizionario come una voce di base del catalogo di una biblioteca. Sebbene non sia essenziale per la visualizzazione del documento, fornisce informazioni fondamentali sull'origine e la storia del documento utilizzando semplici stringhe di testo.
Campi delle informazioni sul documento.
| Key | Data Type | Description | Example |
|---|---|---|---|
/Title |
Text String | Document title (separate from any visible title) | “Annual Report 2024” |
/Subject |
Text String | Document subject or description | “Financial Performance Analysis” |
/Keywords |
Text String | Searchable keywords | “finance, quarterly, revenue” |
/Author |
Text String | Document creator | “Jane Smith” |
/Creator |
Text String | Original application that created the document | “Microsoft Word” |
/Producer |
Text String | Application that converted to PDF | “Adobe Acrobat” |
/CreationDate |
Date String | When the document was originally created | D:20240625132712+08’00’ |
/ModDate |
Date String | Last modification timestamp | D:20240626094530+08’00’ |
⚠️ Importante distinzione.
Il /Creator e /Producer I campi servono a scopi diversi: Creator identifica l'applicazione originale che ha creato il documento (come Microsoft Word), mentre Producer identifica il software che ha generato il file PDF finale (come Adobe Acrobat o un driver di stampa PDF).
📋 Dizionario completo delle informazioni del documento:
|
1 2 3 4 5 6 7 8 9 10 |
<< /ModDate (D:20060926213913+02'00') /CreationDate (D:20060926213913+02'00') /Title (Product Catalog - UK Edition) /Creator (QuarkXPress: pictwpstops filter 1.0) /Producer (Acrobat Distiller 6.0 for Macintosh) /Author (James Smith) /Subject (Quarterly Product Showcase) /Keywords (products, catalog, prices, specifications) >> |
🏛️ Catalogo dei documenti: il centro di controllo principale.
Se il dizionario del trailer è il sistema GPS del PDF, allora il catalogo dei documenti è il suo centro di comando centrale. Essendo l'oggetto radice dell'intero grafo del documento, il catalogo orchestra come tutti gli altri oggetti si relazionano tra loro e come il documento si comporta quando viene visualizzato o stampato.
Ogni oggetto in un documento PDF può essere raggiunto tramite riferimenti diretti o indiretti a partire dal catalogo dei documenti. Questo approccio centralizzato garantisce una navigazione efficiente e mantiene l'integrità del documento.
🎛️ Voci essenziali del catalogo.
| Key | Type | Purpose | Required? |
|---|---|---|---|
/Type |
Name | Must be /Catalog |
✅ Yes |
/Pages |
Indirect Reference | Root of the page tree structure | ✅ Yes |
/PageLabels |
Number Tree | Enables complex page numbering (i, ii, iii, 1, 2, 3) | ❌ Optional |
/Names |
Dictionary | Name trees for referencing objects by name | ❌ Optional |
/Dests |
Dictionary | Named destinations for hyperlinks | ❌ Optional |
/ViewerPreferences |
Dictionary | Controls PDF viewer behavior | ❌ Optional |
/PageMode |
Name | Default viewing mode (thumbnails, bookmarks, etc.) | ❌ Optional |
/PageLayout |
Name | Page display layout (single, facing pages, etc.) | ❌ Optional |
/Outlines |
Indirect Reference | Document bookmarks/outline structure | ❌ Optional |
/Metadata |
Indirect Reference | XMP metadata stream | ❌ Optional |
🎨 Preferenze del visualizzatore: controllo dell'esperienza utente.
Il /ViewerPreferences Il dizionario consente agli autori di documenti di influenzare il modo in cui i visualizzatori di PDF mostrano i loro documenti. Questo può includere la possibilità di nascondere le barre degli strumenti, adattare le pagine alle finestre o persino controllare le impostazioni di stampa.
📚 Spiegazione delle opzioni di modalità pagina
- /UseNone – Solo documento, senza pannelli di navigazione
- /UseOutlines – Mostra il pannello dei segnalibri
- /UseThumbs – Visualizza le miniature delle pagine
- /FullScreen – Entra in modalità presentazione
- /UseOC – Mostra il pannello dei contenuti opzionali (layer)
- /UseAttachments – Visualizza il pannello degli allegati
🌳 Pagine e alberi di pagine: organizzazione efficiente dei contenuti
Una delle scelte progettuali più ingegnose di PDF riguarda il modo in cui organizza le pagine. Invece di utilizzare una semplice lista lineare, PDF utilizza una struttura ad albero che migliora notevolmente le prestazioni, soprattutto per documenti di grandi dimensioni.
Immagina di dover trovare una pagina specifica in un documento di 1000 pagine controllando ogni pagina sequenzialmente: potrebbe richiedere fino a 1000 operazioni! La struttura ad albero delle pagine riduce questo a poche operazioni, rendendo i visualizzatori di PDF estremamente veloci anche con documenti molto grandi.
🏗️ Comprensione della struttura del dizionario delle pagine.
Ogni pagina in un PDF è rappresentata da un dizionario di pagina che riunisce tutti gli elementi necessari per renderizzare quella specifica pagina: istruzioni di contenuto, risorse (font, immagini) e specifiche di layout.
| Key | Type | Purpose | Inheritance |
|---|---|---|---|
/Type |
Name | Must be /Page |
❌ |
/Parent |
Indirect Reference | Parent node in page tree | ❌ |
/Resources |
Dictionary | Fonts, images, other resources | ✅ From parent if missing |
/Contents |
Stream/Array | Page content instructions | ❌ |
/MediaBox |
Rectangle | Physical page size | ✅ From parent if missing |
/CropBox |
Rectangle | Visible page area | ✅ Defaults to MediaBox |
/Rotate |
Integer | Page rotation (0, 90, 180, 270) | ✅ From parent if missing |
📐 Comprensione dei sistemi di coordinate PDF.
PDF utilizza un sofisticato sistema di coordinate basato su rettangoli definiti da quattro numeri che rappresentano gli angoli diagonali. Comprendere questo sistema è fondamentale per lavorare con i layout delle pagine.
📏 Esempi di definizione di rettangoli:
|
1 2 |
/MediaBox [0 0 595 842] # A4 size in points (8.27" × 11.69") /CropBox [50 50 545 792] # A4 with 50-point margins on all sides |
💡 Unità di misura PDF.
PDF utilizza i punti come unità di misura di base, dove 1 punto = 1/72 di pollice. Questo rende i calcoli semplici: 72 punti = 1 pollice, 144 punti = 2 pollici, ecc.
L'architettura ad albero delle pagine.
La brillantezza dell'architettura ad albero risiede nella sua struttura bilanciata. Le buone applicazioni PDF creano alberi in cui qualsiasi pagina può essere trovata in pochi passaggi, indipendentemente dalle dimensioni del documento.
Esempio di architettura ad albero delle pagine.
/Type /Pages
/Count 7
/Count 3
/Count 2
/Type /Page
/Type /Page
Figura 2: Struttura ad albero delle pagine per un documento di 7 pagine, che mostra una gerarchia equilibrata per un accesso efficiente.
🎯 Vantaggi delle prestazioni della struttura ad albero delle pagine:
- Tempo di accesso logaritmico – Trova qualsiasi pagina in O(log n) operazioni.
- Utilizzo efficiente della memoria. – Carica solo le porzioni necessarie di documenti di grandi dimensioni.
- Architettura scalabile. – Le prestazioni rimangono costanti anche quando i documenti crescono.
- Ottimizzazione dell'ereditarietà. – Proprietà comuni condivise tra i gruppi di pagine.
📝 Struttura del nodo dell'albero delle pagine.
| Key | Type | Purpose |
|---|---|---|
/Type |
Name | Must be /Pages |
/Kids |
Array | References to child nodes (pages or page trees) |
/Count |
Integer | Total number of leaf pages under this node |
/Parent |
Reference | Parent node (required unless root) |
🏗️ Esempio di implementazione dell'albero delle pagine:
|
1 2 3 4 5 6 7 8 |
1 0 obj % Root node << /Type /Pages /Kids [2 0 R 3 0 R 4 0 R] /Count 7 >> endobj 2 0 obj % Intermediate node << /Type /Pages /Kids [5 0 R 6 0 R 7 0 R] /Parent 1 0 R /Count 3 >> endobj 5 0 obj % Actual page << /Type /Page /Parent 2 0 R /MediaBox [0 0 612 792] /Resources << >> >> endobj |
Stringa di testo: gestione di codifiche multiple.
La portata globale dei PDF richiede solide capacità di gestione del testo. Il formato supporta schemi di codifica multipli per adattarsi a diverse lingue e set di caratteri, garantendo che i documenti vengano visualizzati correttamente indipendentemente dalla località dello spettatore.
Comprendere la codifica del testo PDF è fondamentale per chiunque lavori con documenti internazionali o sviluppi applicazioni di elaborazione PDF.
Metodi di codifica primari.
1. PDFDocEncoding.
Basato su ISO Latin-1, PDFDocEncoding gestisce in modo efficiente la maggior parte delle lingue europee occidentali. È la codifica predefinita per le stringhe di testo PDF e offre un'eccellente compatibilità con i sistemi legacy.
2. Unicode (UTF-16BE).
Per caratteri internazionali e scritture complesse, PDF utilizza Unicode con codifica UTF-16BE. Le stringhe Unicode sono identificate da un marcatore di ordine dei byte (BOM) all'inizio.
Rilevamento di stringhe Unicode.
I visualizzatori PDF determinano la codifica esaminando i primi due byte di una stringa di testo.
|
1 2 3 4 |
If bytes[0] == 254 AND bytes[1] == 255: encoding = "UTF-16BE" # Unicode byte-order marker U+FEFF else: encoding = "PDFDocEncoding" # Default PDF encoding |
Avviso: Vincolo di codifica.
A causa del meccanismo di rilevamento Unicode, le stringhe PDFDocEncoding non possono iniziare con la sequenza di byte [254, 255] (þÿ). Tuttavia, questa limitazione raramente influisce sui documenti reali.
Formati di data: informazioni temporali precise.
PDF utilizza un formato di data sofisticato che non solo registra quando è accaduto qualcosa, ma tiene anche conto dei fusi orari, il che è fondamentale per i flussi di lavoro documentali globali e i requisiti legali.
Struttura del formato di data PDF.
|
1 |
(D:YYYYMMDDHHmmSSOHH'mm') |
| Component | Meaning | Format | Example |
|---|---|---|---|
| YYYY | Year | Four digits | 2025 |
| MM | Month | 01-12 | 06 (June) |
| DD | Day | 01-31 | 25 |
| HH | Hour | 00-23 | 13 (1 PM) |
| mm | Minute | 00-59 | 27 |
| SS | Second | 00-59 | 12 |
| O | UTC Offset | +, -, or Z | + (later than UTC) |
| HH’ | Offset Hours | 00-23 | 08 (8 hours) |
| mm’ | Offset Minutes | 00-59 | 00 (no minutes) |
Esempi di fusi orari.
|
1 2 3 |
(D:20250625132712+08'00') # June 25, 2024, 1:27:12 PM, UTC+8 (Beijing) (D:20250625132712-05'00') # Same moment in Eastern Standard Time (D:20250625132712Z) # Same moment in UTC (Zulu time) |
🕐 Precisione flessibile delle date.
Le date nei file PDF supportano una precisione variabile. È possibile specificare solo l'anno. (D:2025), oppure includere la precisione completa fino ai secondi e ai fusi orari. I componenti mancanti vengono impostati su valori predefiniti ragionevoli (01 per mese/giorno, 00 per i componenti di tempo).
🧩 Mettiamo tutto insieme: un esempio completo.
Esaminiamo un esempio completo di file PDF creato manualmente che illustra tutti i concetti che abbiamo discusso. Questo documento di tre pagine mostra l'interazione tra tutti gli elementi strutturali del file PDF.
📄 Esempio completo della struttura di un file PDF:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
%PDF-1.0 % Header 1 0 obj % Document catalog << /PageLayout /TwoColumnLeft /Pages 2 0 R /Type /Catalog >> endobj 2 0 obj % Root of page tree << /Kids [3 0 R 4 0 R] /Type /Pages /Count 3 >> endobj 3 0 obj % Page one << /Type /Page /Parent 2 0 R /MediaBox [0 0 612 792] % US Letter size /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [5 0 R] >> endobj 4 0 obj % Intermediate page tree node << /Parent 2 0 R /Kids [6 0 R 7 0 R] /Count 2 /Type /Pages >> endobj 5 0 obj % Content stream for page one << /Length 58 >> stream BT /F0 24 Tf 50 750 Td (Hello, PDF World!) Tj ET endstream endobj 6 0 obj % Page two << /Type /Page /Parent 4 0 R /MediaBox [0 0 612 792] /Rotate 90 % Landscape orientation /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [8 0 R] >> endobj 7 0 obj % Page three << /Type /Page /Parent 4 0 R /MediaBox [0 0 612 792] /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [9 0 R] >> endobj 8 0 obj % Content stream for page two << /Length 72 >> stream BT /F0 18 Tf 50 700 Td (This page is rotated 90 degrees) Tj ET endstream endobj 9 0 obj % Content stream for page three << /Length 45 >> stream BT /F0 24 Tf 50 750 Td (Final page) Tj ET endstream endobj 10 0 obj % Document information dictionary << /Title (PDF Structure Example) /Author (PDF Guide Author) /Producer (Manual Creation) /CreationDate (D:20240625132712+08'00') /ModDate (D:20240625133045+08'00') /Subject (Demonstrating PDF internal structure) /Keywords (PDF, structure, example, tutorial) >> endobj xref % Cross-reference table 0 11 0000000000 65535 f 0000000015 00000 n 0000000074 00000 n 0000000120 00000 n 0000000355 00000 n 0000000415 00000 n 0000000522 00000 n 0000000747 00000 n 0000000958 00000 n 0000001079 00000 n 0000001173 00000 n trailer % Trailer dictionary << /Size 11 /Root 1 0 R /Info 10 0 R /ID [<A1B2C3D4E5F6789012345678901234AB> <A1B2C3D4E5F6789012345678901234AB>] >> startxref 1456 %%EOF |
🗺️ Grafico di riferimento degli oggetti.
/Size 11
/Root 1 0 R → Document Catalog
/Info 10 0 R → Document Info
/Type /Catalog
/Pages 2 0 R
/Title /Author
/CreationDate /ModDate
/Type /Pages
/Kids [3 0 R 4 0 R]
/Count 3
/Type /Page
/Contents [5 0 R]
/Kids [6 0 R 7 0 R]
/Count 2
/Contents [8 0 R]
/Rotate 90
/Contents [9 0 R]
Figura 3: Grafico di riferimento degli oggetti che mostra come il dizionario del trailer si collega a tutti i componenti del documento.
🔍 Analisi della struttura di esempio.
🎯 Osservazioni chiave:
- Navigazione efficiente. – Qualsiasi pagina accessibile in massimo 2 passaggi dalla radice.
- Ereditarietà delle risorse. – Le risorse dei font possono essere ereditate dai nodi padre.
- Layout flessibile. – La pagina 2 dimostra le capacità di rotazione.
- Metadati ricchi. – Informazioni complete sul documento per la gestione del flusso di lavoro.
- Identificazione univoca. – L'array di ID consente il tracciamento dei documenti.
🚀 Argomenti avanzati e best practice.
🔧 Strategie di ottimizzazione.
📈 Suggerimenti per l'ottimizzazione delle prestazioni:
- Alberi bilanciati. – Mantenere tempi di accesso logaritmici per documenti di grandi dimensioni.
- Condivisione delle risorse. – Posizionare le risorse comuni nei nodi dell'albero delle pagine padre.
- Codifica efficiente. – Utilizzare PDFDocEncoding per il testo occidentale, Unicode solo quando necessario.
- Ereditarietà corretta. – Sfruttare l'ereditarietà dell'albero delle pagine per le proprietà comuni.
- Metadati minimi. – Includere solo le voci del dizionario necessarie.
🛡️ Prevenzione e validazione degli errori.
⚠️ Errori comuni da evitare:
- Riferimenti interrotti. – Assicurarsi che tutti i riferimenti indiretti puntino a oggetti validi.
- Conteggi incoerenti. – I conteggi dell'albero delle pagine devono riflettere accuratamente le pagine foglia.
- Campi obbligatori mancanti. – Includere sempre le voci obbligatorie nel dizionario.
- Formati data non validi. – Seguire le specifiche precise dei formati data.
- Incongruenze di codifica. – Identificare correttamente le stringhe Unicode rispetto a PDFDocEncoding.
🔮 Considerazioni future.
Man mano che il formato PDF continua ad evolversi, comprendere queste strutture fondamentali diventa sempre più prezioso. Le moderne funzionalità PDF, come le firme digitali, i tag di accessibilità e i moduli interattivi, si basano tutte sulla solida base che abbiamo esplorato.
🌟 Tecnologie PDF emergenti:
- Standard PDF/A – Formati di archiviazione a lungo termine
- Accessibilità PDF/UA – Conformità all'accessibilità universale
- Moduli interattivi – Contenuti dinamici e interazione con l'utente
- Firme digitali Integrità crittografica dei documenti.
- Contenuti 3D. Incorporamento di modelli tridimensionali.
🎯 Conclusione: Padroneggiare la struttura dei PDF.
Comprendere la struttura interna dei PDF apre le porte a un'elaborazione avanzata dei documenti, alla risoluzione dei problemi e all'ottimizzazione. Dalle funzionalità di navigazione del dizionario di coda all'organizzazione efficiente degli alberi di pagine, ogni componente ha uno scopo specifico nella creazione di documenti robusti e portatili su cui ci affidiamo quotidianamente.
🏆 Punti chiave:
- Progettazione gerarchica. La struttura basata su alberi dei PDF consente una scalabilità efficiente.
- Navigazione intelligente. – Le tabelle di riferimento e i dizionari forniscono un accesso rapido.
- Codifica flessibile. – Il supporto per più codifiche di testo consente lo scambio globale di documenti.
- Metadati ricchi. – Il tracciamento completo delle informazioni supporta flussi di lavoro complessi.
- Modello di ereditarietà. – La condivisione delle risorse riduce la ridondanza e le dimensioni dei file.
“La bellezza del PDF non risiede nella sua complessità, ma nel modo in cui tale complessità è elegantemente organizzata per raggiungere l'obiettivo semplice della portabilità universale dei documenti.”
Questa approfondita esplorazione della struttura PDF mira a chiarire gli aspetti tecnici di uno dei formati di documento più importanti al mondo. Comprendere questi dettagli interni consente a sviluppatori, responsabili della gestione dei documenti e a persone curiose di lavorare in modo più efficace con la tecnologia PDF. Si consiglia di utilizzare librerie di sviluppo PDF mature per semplificare notevolmente le attività di elaborazione PDF.