Comprendre les métadonnées XML et les signets PDF : un guide technique.
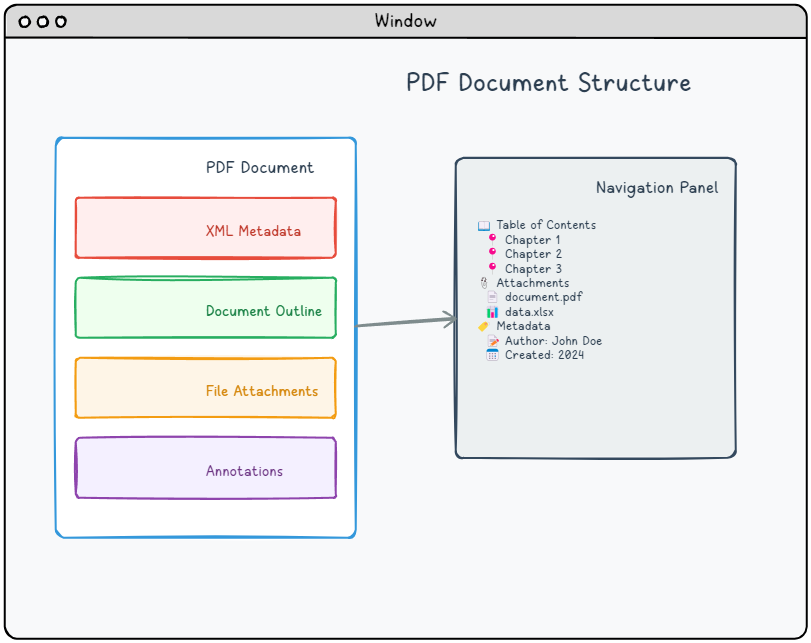
Sujets clés abordés.
📍 Destinations.
Marqueurs de position précis qui définissent des positions spécifiques dans les documents PDF. Ceux-ci permettent une navigation précise pour les signets et les hyperliens, tandis que les plans de documents offrent une fonctionnalité de table des matières hiérarchique.
📄 Métadonnées XML.
Flux XML structurés qui fournissent des métadonnées complètes des documents en utilisant des formats XMP standardisés, allant au-delà des propriétés de base des documents pour inclure des informations descriptives riches.
📎 Pièces jointes.
Capacité complète d'intégration de fichiers qui encapsule les ressources externes directement dans les documents PDF, créant des ensembles de documents autonomes similaires aux pièces jointes de courrier électronique.
📝 Annotations.
Éléments de superposition interactifs qui ajoutent du texte, des graphiques et des fonctionnalités cliquables aux pages PDF sans modifier le contenu sous-jacent. Inclut des hyperliens pour une navigation transparente dans les documents et divers outils de marquage pour une interaction accrue avec le lecteur.
Favoris et destinations.

La navigation dans le document repose sur des structures de favoris hiérarchiques, techniquement appelées les... plan du documentCe système organisé en arborescence présente des entrées cliquables, généralement des titres de chapitres, des en-têtes de sections et des noms de sous-sections, qui permettent aux lecteurs de passer rapidement à des parties spécifiques du document. Chaque entrée de signet combine un texte d'affichage avec des informations de destination qui spécifient exactement où le lien doit rediriger.
Comprendre les destinations
Les destinations PDF servent de marqueurs de position précis dans un document, spécifiant quelle page afficher, où positionner la vue sur cette page et quel niveau de zoom appliquer. Vous pouvez créer des destinations de deux manières : les définir directement (ce que nous utiliserons dans nos exemples pour plus de clarté) ou les référencer par nom via un système de nommage global au sein du document. La plupart des lecteurs PDF présentent les signets dans un panneau de navigation à côté du contenu principal du document.
Chaque destination utilise une structure de tableau où les éléments spécifiques varient en fonction du comportement de visualisation que vous souhaitez obtenir. Voici les principaux modèles de destination disponibles :
Tableau des types de destinations
Remarque : "page" représente une référence indirecte à un objet page. Par défaut, ces destinations fonctionnent avec les limites de la zone de découpe de la page, en revenant à la zone de médias lorsque aucune zone de découpe n'est définie.
| Array | Description |
|---|---|
| [page /Fit] | Scales the page to fit completely within the viewer window, adjusting both width and height proportionally. |
| [page /FitH top] | Positions the specified top coordinate at the window’s top edge while scaling horizontally to fit the full page width. |
| [page /FitV left] | Aligns the specified left coordinate with the window’s left edge while scaling vertically to fit the full page height. |
| [page /XYZ left top zoom] | Positions the coordinates (left, top) at the window’s upper-left corner and applies the specified zoom factor. Null values preserve current settings for those parameters. |
| [page /FitR left bottom right top] | Zooms and positions the view to display the rectangular area defined by the left, bottom, right, and top coordinates. |
| [page /FitB] | Similar to /Fit, but scales based on the actual content boundaries instead of the defined crop box area. |
| [page /FitBH top] | Functions like /FitH but uses the content bounding box instead of the crop box for horizontal scaling calculations. |
| [page /FitBV left] | Operates like /FitV but calculates vertical scaling based on the content bounding box rather than the crop box boundaries. |
Structure du plan du document
Les plans de documents créent une structure de navigation hiérarchique qui fonctionne comme une table des matières interactive pour les lecteurs de PDF. Cette organisation en forme d'arbre aide les utilisateurs à naviguer rapidement dans des documents complexes en fournissant une vue d'ensemble structurée claire. Le système repose sur deux types d'objets fondamentaux :
- Dictionnaire du plan – La racine de la hiérarchie du plan
- Dictionnaires d'éléments du plan – Les entrées individuelles dans le plan
Structure du dictionnaire du plan (Table)
| Key | Value Type | Value |
|---|---|---|
| /Type | name | If present, must be /Outlines. |
| /First | indirect reference to dictionary | References the initial top-level outline entry in the document hierarchy. This field is mandatory when outline entries exist. |
| /Last | indirect reference to dictionary | References the final top-level outline entry in the document hierarchy. This field is mandatory when outline entries exist. |
| /Count | integer | Specifies how many outline entries are currently expanded across the entire outline tree. Can be omitted when no entries are in an open state. |
Implémentation des éléments du plan
Chaque élément du plan est constitué d'un dictionnaire qui spécifie son titre d'affichage, sa destination et ses relations avec les autres éléments de la hiérarchie.
Examinons comment un simple plan de document est structuré dans la syntaxe PDF.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
8 0 obj <</Type/Outlines/Count 4/First 9 0 R/Last 9 0 R>> endobj 9 0 obj <</Title(Chapter 1: Experiment A)/Count 3/Parent 8 0 R/First 12 0 R/Last 18 0 R>> endobj 12 0 obj <</Title(1: Introduction)/Count 0/Parent 9 0 R/Next 15 0 R>> endobj 15 0 obj <</Title(2: Methodology)/Count 0/Parent 9 0 R/Prev 12 0 R/Next 18 0 R>> endobj 18 0 obj <</Title(3: Result verification)/Count 0/Parent 9 0 R/Prev 15 0 R/>> endobj |
Structure du tableau du dictionnaire des éléments du plan.
* indique une entrée obligatoire
| Key | Value Type | Value |
|---|---|---|
| /Title* | text string | Text to be displayed for this entry. |
| /Parent* | indirect reference to dictionary | References this item’s parent within the outline hierarchy, which can be either another outline item or the root outline dictionary. |
| /Prev | indirect reference to dictionary | References the preceding sibling item at the same hierarchical level, when applicable. |
| /Next | indirect reference to dictionary | References the following sibling item at the same hierarchical level, when applicable. |
| /First | indirect reference to dictionary | References the initial child item under this entry, when child items exist. |
| /Last | indirect reference to dictionary | References the final child item under this entry, when child items exist. |
| /Count | integer | When the entry is expanded, indicates the count of visible descendant entries. When collapsed, stores a negative value representing the total number of hidden descendants that would become visible upon expansion. |
| /Dest | name, string or array | The destination. Arrays are destinations, names are references to entries in the /Dests entry in the document catalog, strings are references to entries in the /Dests entry in the document’s name dictionary. |
Métadonnées XML.
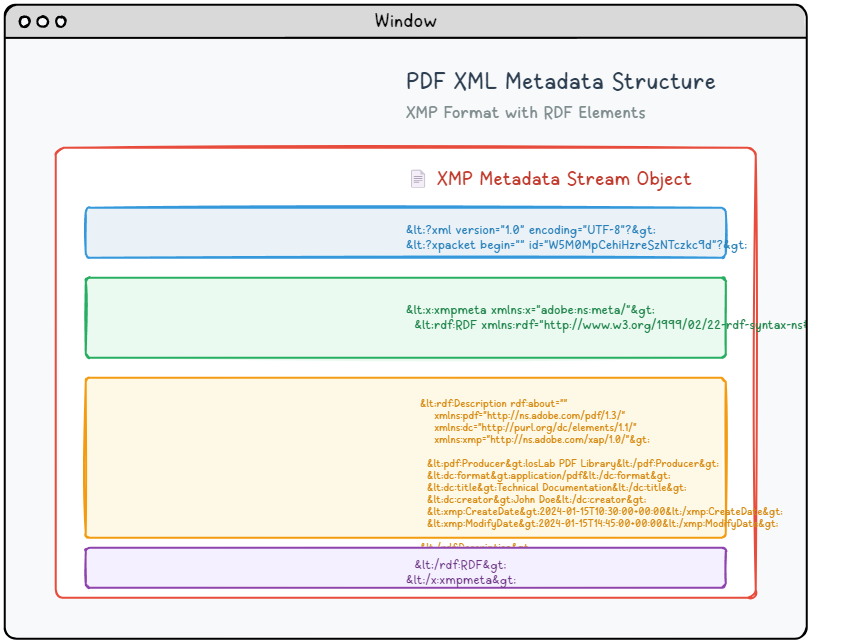
Les documents PDF modernes peuvent intégrer des flux de métadonnées XML sophistiqués qui offrent des informations beaucoup plus détaillées et structurées que les propriétés de document traditionnelles. Ce système de métadonnées avancé utilise la spécification XMP (Extensible Metadata Platform) d'Adobe pour fournir des descriptions de documents standardisées et lisibles par machine, qui améliorent la recherche, l'organisation et les capacités de traitement automatisé.
Structure des métadonnées XMP.
Les métadonnées XMP sont regroupées sous forme de document XML qui utilise la syntaxe RDF (Resource Description Framework) pour organiser et décrire les propriétés du document dans un format standardisé. Ce contenu de métadonnées est intégré dans un objet de flux dédié qui inclut une identification de type appropriée pour les processeurs PDF :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
6 0 obj <</Length 1235/Type/Metadata/Subtype/XML>>stream <?xpacket begin="锘xBF" id="W5M0MpCehiHzreSzNTczkc9d"?> <x:xmpmeta xmlns:x="adobe:ns:meta/" x:xmptk="Adobe XMP Core 5.2-c001 63.139439, 2010/09/27-13:37:26" ><rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" ><rdf:Description rdf:about="" xmlns:pdf="http://ns.adobe.com/pdf/1.3/" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:xmp="http://ns.adobe.com/xap/1.0/" ><pdf:Producer>losLab PDF Library</pdf:Producer> <dc:creator>losLab.com</dc:creator> <dc:title>Delphi PDF SDKs</dc:title> <xmp:CreateDate>2025-06-29T10:46:27+08:00</xmp:CreateDate> <xmp:ModifyDate>2025-06-29T10:58:57+08:00</xmp:ModifyDate> <xmp:MetadataDate>2025-06-29T10:46:27+08:00</xmp:MetadataDate> <dc:description>Delphi Development Library for PDF creation & editing</dc:description> <xmp:CreatorTool>HotPDF Component</xmp:CreatorTool> <dc:subject>PDF Developer Library for RAD Studio></dc:subject> <pdf:Keywords>Delphi, PDF SDK, PDF Component</pdf:Keywords> </rdf:Description>Robust Delphi PDF development library</rdf:RDF> </x:xmpmeta> <?xpacket end="w"?> endstream endobj |
Schémas de métadonnées standard.
Le framework XMP organise les métadonnées grâce à des espaces de noms de schémas bien établis, chacun servant des catégories d'informations spécifiques.
📋 Dublin Core (dc:)
Informations bibliographiques de base.
- dc:title – Titre du document.
- dc:creator – Auteur(s) du document.
- dc:subject – Sujet/mots-clés du document.
- dc:description – Description du document.
- dc:format – Type MIME.
🏷️ XMP Basic (xmp:)
Propriétés de base de XMP
- xmp:CreateDate – Date de création
- xmp:ModifyDate – Date de modification
- xmp:CreatorTool – Application de création
- xmp:MetadataDate – Date de modification des métadonnées
📄 Schéma PDF (pdf:)
Propriétés spécifiques à PDF
- pdf:Producer – Fabricant du fichier PDF.
- pdf:Keywords – Mots-clés du document.
- pdf:PDFVersion – Version du fichier PDF.
Intégration avec le catalogue de documents.
Le flux de métadonnées XML est référencé à partir du catalogue de documents :
|
1 2 3 |
1 0 obj < < Type Catalog Pages 2 0 R Metadata 10 0 R Outlines 1 0 R>> endobj |
🎯 Bonnes pratiques pour les métadonnées XML.
- Incluez toujours à la fois le dictionnaire d'informations du document et les métadonnées XMP pour une compatibilité maximale.
- Assurez-vous que les valeurs des métadonnées sont cohérentes entre les deux emplacements.
- Utilisez le codage XML approprié (UTF-8) pour les caractères internationaux.
- Incluez les dates de création et de modification au format ISO 8601.
- Validez la structure XML pour éviter les erreurs d'analyse.
Pièces jointes de fichiers.
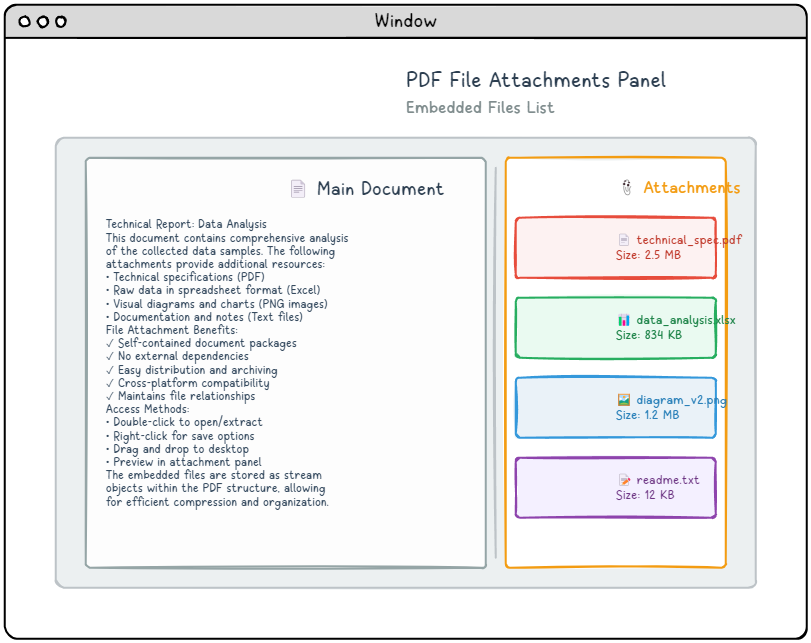
Les pièces jointes de fichiers PDF offrent une méthode pratique pour intégrer directement des fichiers externes dans un document PDF, créant des packages autonomes qui incluent toutes les ressources nécessaires. Ces pièces jointes peuvent être associées à l'ensemble du document ou liées à des pages spécifiques, selon vos besoins. La plupart des lecteurs PDF modernes présentent ces fichiers intégrés dans un panneau de pièces jointes dédié, ce qui permet aux utilisateurs d'accéder, de visualiser ou d'enregistrer facilement le contenu inclus. Cette fonctionnalité est particulièrement utile pour créer des packages de documents complets, tels que des présentations qui incluent des ressources supplémentaires ou des rapports avec des fichiers de données associés.
Structure des fichiers intégrés.
Au cœur d'un fichier intégré se trouve un objet de flux qui contient les données réelles du fichier, ainsi qu'une entrée de dictionnaire de flux qui spécifie /Type /EmbeddedFileCette approche simple permet de stocker n'importe quel type de fichier dans un PDF. Voici à quoi ressemble la structure de base d'un fichier intégré :
|
1 2 3 4 5 6 |
8 0 obj < < Type EmbeddedFile Length 35>> stream This is a text file attachment... endstream endobj |
Le format PDF prend en charge deux approches distinctes pour référencer les fichiers intégrés, chacune répondant à des cas d'utilisation différents : les pièces jointes au niveau du document, accessibles globalement, et les pièces jointes au niveau de la page, qui apparaissent comme des éléments interactifs sur des pages spécifiques.
Pièces jointes au niveau du document
Pour les pièces jointes valables pour l'ensemble du document, vous devez ajouter une /EmbeddedFiles entrée au dictionnaire de noms, qui est accessible via l' /Names entrée dans le catalogue du document. Cette approche rend la pièce jointe globalement disponible dans l'ensemble du PDF, quel que soit la page que l'utilisateur consulte actuellement :
|
1 2 3 4 5 6 |
9 0 obj < < Names << EmbeddedFiles << Names [ (attachment.txt) << EF << F 8 0 R>> /F (attachment.txt) /Type /Filespec >> ] >> >> /Pages 1 0 R /Type /Catalog >> endobj |
Explication de la structure du code
- /Names – Contient le dictionnaire de noms pour le document.
- /EmbeddedFiles – Gère spécifiquement les noms de fichiers intégrés.
- (attachment.txt) – Le nom de fichier tel qu'il apparaît aux utilisateurs.
- /EF – Dictionnaire des fichiers intégrés contenant la référence réelle au fichier.
- /F 8 0 R – Référence à l'objet de flux de fichier intégré.
- /Type /Filespec – Identifie ceci comme un dictionnaire de spécification de fichier.
Pièces jointes au niveau de la page.
Les pièces jointes spécifiques à la page nécessitent une approche différente utilisant des annotations de pièces jointes de fichier. Celles-ci sont ajoutées au /Annots tableau dans le dictionnaire de la page cible, créant une icône de pièce jointe visible avec laquelle les utilisateurs peuvent interagir directement sur la page :
|
1 2 3 4 5 6 7 8 |
9 0 obj < < Type Page (Other dictionary entries as usual) Annots [ << FS << EF << F 8 0 R>> /F (attachment.txt) /Type /Filespec >> /Subtype /FileAttachment /Contents (attachment.txt) /Rect [ 18 796.88976378 45 823.88976378 ] >> ] >> endobj |
Propriétés des pièces jointes de la page.
- /FS – Dictionnaire de spécification de fichier (identique à /EF ci-dessus).
- /Subtype /FileAttachment – Identifie cette annotation comme une pièce jointe.
- /Contents – Texte d'infobulle qui apparaît lorsque vous survolez l'icône de la pièce jointe.
- /Rect – Rectangle définissant la position et la taille de l'icône de la pièce jointe sur la page.
Cas d'utilisation des pièces jointes
📊 Fichiers de données
Intégrez des feuilles de calcul, des bases de données ou des fichiers de données bruts aux rapports et analyses.
🎨 Fichiers sources
Incluez les fichiers de conception originaux, les plans CAD ou les modèles modifiables.
📹 Ressources multimédias
Joignez des présentations vidéo, des enregistrements audio ou du contenu interactif.
📋 Documents justificatifs
Regroupez les fichiers PDF, les contrats ou les documents de référence connexes.
Annotations.

Les annotations PDF offrent un moyen puissant d'ajouter des éléments interactifs et des marquages visuels aux documents sans modifier le contenu de la page originale. Ces éléments superposés améliorent l'expérience de lecture en permettant aux utilisateurs de surligner du texte, d'ajouter des commentaires ou de créer des liens cliquables. Parmi les types d'annotations les plus utiles, on trouve les hyperliens, qui permettent une navigation fluide entre les différentes sections d'un document ou vers des ressources externes.
Structure des annotations
Bien que différents types d'annotations servent à des fins variées, ils suivent tous une structure fondamentale cohérente, avec des propriétés spécifiques au type ajoutées si nécessaire. Les pages PDF peuvent contenir plusieurs annotations, qui sont organisées dans un tableau référencé par l'entrée /Annots dans le dictionnaire de chaque page. Chaque annotation est implémentée en tant qu'objet de dictionnaire avec des propriétés spécifiques.
Structure du dictionnaire des annotations Tableau
* indique une entrée obligatoire
| Key | Value Type | Value |
|---|---|---|
| /Type | name | When specified, this value must be set to /Annot to properly identify the dictionary type. |
| /Subtype* | name | Specifies the specific annotation category (e.g., Link, Text, Highlight). |
| /Rect* | rectangle | Defines the annotation’s position and dimensions using standard PDF coordinate units. |
| /Contents | text string | Contains the annotation’s text content or provides an alternative descriptive label for accessibility purposes. |
Exemple de dictionnaire d'annotation fondamental :
|
1 2 3 |
12 0 obj < < Type Annot Subtype Link Rect [100 200 300 250] Border [0 0 1] C [0.0 0.0 1.0] Dest [5 0 R XYZ null null null]>> endobj |
Types d'annotations courants
🔗 Annotations de lien
Créez des zones cliquables qui permettent de naviguer vers des destinations à l'intérieur du document ou vers des ressources externes.
- /Subtype /Link – Identifie une annotation de lien.
- /Dest – Tableau de destinations ou destination nommée.
- /A – Dictionnaire d'actions pour des comportements plus complexes.
📝 Annotations de texte.
Affiche des notes et des commentaires contextuels lorsqu'ils sont cliqués.
- /Subtype /Text – Identifie l'annotation comme étant du texte.
- /Contents – Le contenu textuel de l'annotation.
- /Open – Indique si l'annotation est initialement ouverte.
🖍️ Annotations de surlignage.
Mettre en surbrillance, souligner ou barrer du contenu textuel.
- /Subtype /Highlight – Mise en évidence du texte
- /Subtype /Underline – Soulignement du texte
- /Subtype /StrikeOut – Barrage du texte
Actions avancées pour les liens.
Les annotations de lien peuvent effectuer diverses actions au-delà de la simple navigation :
|
1 2 3 |
13 0 obj < < Type Annot Subtype Link Rect [50 50 200 100] A << Type Action S URI URI (https: www.example.com)>> >> endobj |
Types d'actions
- /S /GoTo – Naviguer vers une destination dans le document
- /S /GoToR – Naviguer vers une destination dans un autre document
- /S /URI – Ouvrir une URL web
- /S /Launch – Lancer une application externe.
- /S /JavaScript – Exécuter du code JavaScript.
Apparence de l'annotation.
Le style visuel personnalisé des annotations est obtenu grâce aux flux d'apparence, ce qui permet un contrôle précis de la manière dont les annotations s'affichent aux utilisateurs :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
14 0 obj < < Type Annot Subtype Square Rect [100 100 200 150] C [1.0 0.0 0.0] BS << W 2 S S>> /AP < < N 15 0 R>> >> endobj 15 0 obj < < Type XObject Subtype Form BBox [0 0 100 50] Length 85>> stream q 1.0 0.0 0.0 RG 2 w 10 10 80 30 re S Q endstream endobj |
Lignes directrices de mise en œuvre pratique.
Intégration de la structure du document.
Une implémentation réussie nécessite de comprendre comment ces éléments fonctionnent ensemble dans l'architecture globale du document PDF.
|
1 2 3 4 |
1 0 obj < < Type Catalog Pages 2 0 R Outlines 3 0 R Names << EmbeddedFiles 4 0 R>> /Metadata 5 0 R >> endobj |
✅ Liste de contrôle de l'implémentation
- Configuration du catalogue de documents – Assurez-vous que les références aux plans, aux noms et aux métadonnées sont correctes.
- Numérotation des objets – Maintenez une numérotation des objets et des références croisées cohérentes.
- Encodage des flux – Appliquez les filtres et l'encodage appropriés aux flux.
- Validation – Vérifier la structure du PDF à l'aide d'outils de validation.
- Tests de compatibilité – Tester sur différents lecteurs PDF et versions.
Problèmes courants et solutions.
❌ Les signets ne s'affichent pas.
Solution : Vérifier que le catalogue de documents inclut une /Outlines entrée et que la hiérarchie du plan est correctement structurée avec les relations parent-enfant appropriées.
❌ Les métadonnées ne sont pas reconnues.
Solution : Assurez-vous que le flux de métadonnées XML est correctement formaté, utilise les espaces de noms corrects et est référencé dans le catalogue de documents. /Type /Metadata et /Subtype /XML.
❌ Pièces jointes non accessibles.
Solution : Vérifiez que les fichiers intégrés sont correctement référencés soit dans le dictionnaire de noms au niveau du document, soit dans le dictionnaire d'annotations au niveau de la page, et que les dictionnaires de spécifications de fichiers sont correctement structurés.
Conclusion.
La maîtrise des métadonnées PDF et de l'implémentation des signets est essentielle pour développer des documents de qualité professionnelle qui offrent une expérience utilisateur et des fonctionnalités supérieures. Ces fonctionnalités puissantes offrent :
- Navigation améliorée. – Grâce à des signets et des destinations bien structurés.
- Métadonnées riches. – Permettant une meilleure gestion et une meilleure recherche des documents.
- Intégration de fichiers. – Regroupement des ressources connexes dans les documents.
- Éléments interactifs. – Création d'expériences utilisateur engageantes grâce aux annotations.
En mettant en œuvre correctement ces fonctionnalités, vous pouvez créer des documents PDF qui vont au-delà du simple texte et des graphiques pour devenir des ressources complètes et interactives, qui servent efficacement les lecteurs humains et les systèmes automatisés.
🚀 Prochaines étapes.
- Entraînez-vous à mettre en œuvre ces structures dans votre flux de travail de création de PDF.
- Expérimentez avec différents types d'annotations et hiérarchies de signets.
- Testez vos implémentations sur plusieurs lecteurs PDF.
- Explorez les fonctionnalités PDF avancées en vous basant sur ces fondations.