Comprendre la structure interne des fichiers PDF.
Bienvenue dans le fascinant monde des entrailles des fichiers PDF ! Vous êtes-vous déjà demandé ce qui fait fonctionner un fichier PDF ? Au-delà des documents familiers que nous consultons quotidiennement, se trouve une architecture sophistiquée qui a révolutionné le partage de documents numériques. Dans cette exploration complète, nous allons dévoiler les différentes couches de la structure PDF, révélant les mécanismes complexes qui permettent à ces fichiers omniprésents de fonctionner.
🔍 Introduction : Au-delà de la surface.
Le format de document portable (PDF) est devenu la norme de facto pour l'échange de documents dans le monde entier. Des documents texte simples aux formulaires interactifs complexes, les fichiers PDF maintiennent une apparence cohérente sur différentes plateformes et appareils. Mais qu'y a-t-il sous cette compatibilité universelle ?
Dans cette analyse approfondie, nous allons explorer la structure logique qui rend les fichiers PDF véritablement portables. Nous allons examiner les éléments constitutifs fondamentaux : le dictionnaire de la fin de fichier (trailer dictionary)., le catalogue du document.et arbre de pages—le triumvirat qui orchestre toutes les fonctionnalités d'un fichier PDF. Nous allons également découvrir les secrets des formats de données spécialisés de PDF pour les chaînes de texte et les dates.
🎯 Ce que vous apprendrez dans ce guide :
- Les quatre composants fondamentaux de la structure PDF.
- Comment PDF organise et référence le contenu de manière efficace.
- Le rôle des dictionnaires, des catalogues et des arbres de pages.
- Les approches uniques de PDF pour l'encodage du texte et le formatage des dates.
- Exemples concrets de structures d'objets PDF.
- Bonnes pratiques pour comprendre le fonctionnement interne des PDF.
📋 L'anatomie d'un PDF : aperçu général.
Avant d'entrer dans les détails, établissons un modèle mental de la structure des PDF. Considérez un PDF comme un système de classement sophistiqué où chaque information a une place et un but précis.
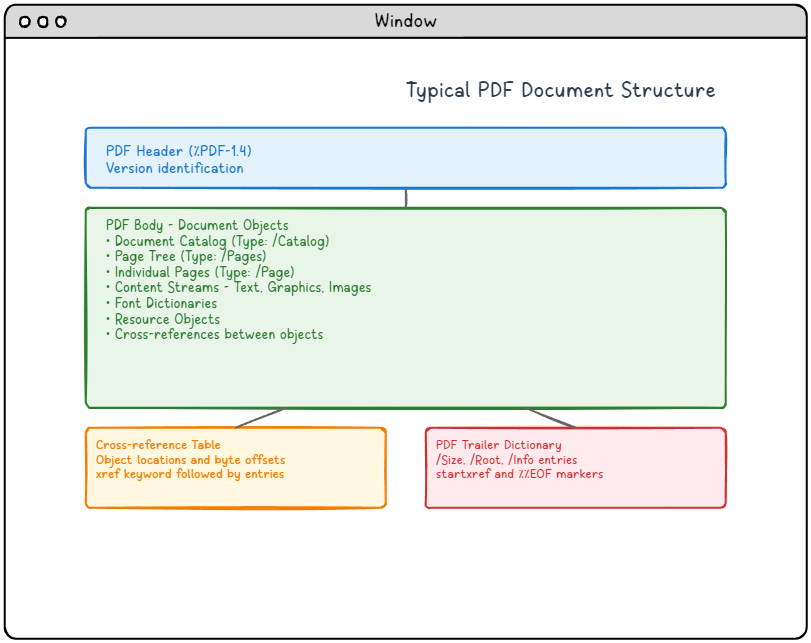
Figure 1 : Structure typique d'un document PDF montrant les quatre principaux composants et leurs relations.
Description détaillée du diagramme de la structure PDF :
Ce diagramme illustre la structure typique d'un document PDF avec quatre principaux composants disposés verticalement :
-
- En-tête PDF (section bleue en haut) : Contient l'identification de la version (%PDF-1.4) qui spécifie la version du format PDF.
- Corps du PDF (section verte au milieu) : La section la plus importante, contenant tous les objets du document, notamment le catalogue du document, l'arborescence des pages, les pages individuelles, les flux de contenu avec du texte/des graphiques/des images, les dictionnaires de polices, les objets de ressources et les références croisées entre les objets.
- Table des références croisées (section orange en bas à gauche) : Contient les emplacements des objets et les décalages en octets, marqués par le mot-clé xref, suivi des entrées.
- Dictionnaire de la fin du PDF (section rouge en bas à droite) : Contient des informations de navigation essentielles, notamment les entrées /Size, /Root, /Info, et se termine par les marqueurs startxref et %%EOF.
Les flèches indiquent le flux logique de l'en-tête au corps, puis se ramifient vers le tableau de références croisées et le dictionnaire de la fin, illustrant comment les lecteurs PDF naviguent dans la structure du document.
Un document PDF est composé de quatre éléments structurels principaux qui fonctionnent en harmonie.
🏗️ Les Quatre Piliers de la Structure PDF :
- En-tête – Identifie la version et les fonctionnalités du PDF.
- Corps – Contient tous les objets du document (texte, images, polices, etc.).
- Tableau de références croisées. – Permet de localiser rapidement les objets.
- Remorque – Fournit le point d'entrée pour naviguer dans le document.
Cette structure permet à PDF d'être remarquablement efficace pour gérer des documents de toutes tailles, des simples lettres d'une page à d'énormes manuels techniques contenant des milliers de pages.
🗂️ Le dictionnaire de la remorque : le système de navigation de votre PDF.
Imaginez essayer de naviguer dans une bibliothèque sans système de catalogage : le chaos en résulterait ! Le dictionnaire de la remorque sert de système de navigation sophistiqué pour PDF, fournissant la carte essentielle que les lecteurs PDF utilisent pour comprendre et afficher votre document.
Situé à la toute fin du fichier PDF, le dictionnaire de la remorque est paradoxalement l'une des premières choses traitées lors de l'ouverture d'un PDF. Il contient les informations cruciales qui permettent aux logiciels de localiser et d'interpréter tous les autres composants du document.
🔑 Éléments essentiels du dictionnaire de la remorque.
| Key | Type | Purpose | Required? |
|---|---|---|---|
/Size |
Integer | Total entries in cross-reference table (usually objects + 1) | ✅ Yes |
/Root |
Indirect Reference | Points to the document catalog—the master control center | ✅ Yes |
/Info |
Indirect Reference | Links to document metadata (title, author, creation date) | ❌ Optional |
/ID |
Array of Strings | Unique document identifier for workflow management | ❌ Optional |
💡 Conseil : Comprendre les identifiants PDF.
La /ID Le tableau contient deux chaînes de caractères : la première est définie lors de la création du document et ne change jamais, tandis que la seconde est mise à jour chaque fois que le document est modifié. Ce système de double identifiant permet des flux de travail de gestion de documents sophistiqués.
📄 Exemple concret de dictionnaire de remorque :
|
1 2 3 4 5 6 |
<< /Size 421 /Root 377 0 R /Info 375 0 R /ID [<5sazn0fs3tamppia2izf569h281104ae> <6cig0wa61ti593bzuwy41905tr6s5c5a>] >> |
Cet exemple montre une remorque pour un document contenant 421 objets, où l'objet 377 sert de catalogue de documents et l'objet 375 contient les informations du document.
📊 Dictionnaire des informations du document : métadonnées PDF traditionnelles.
Le dictionnaire des informations du document contient les dates de création et de modification du fichier, ainsi que quelques métadonnées simples. Il s'agit du système de métadonnées traditionnel utilisé dans les anciennes versions de PDF, et qu'il ne faut pas confondre avec les métadonnées XMP plus complètes qui seront abordées dans les prochains articles.
Considérez ce dictionnaire comme une entrée de catalogue de bibliothèque de base. Bien qu'il ne soit pas essentiel pour afficher le document, il fournit des informations fondamentales sur l'origine et l'historique du document à l'aide de simples chaînes de caractères.
📋 Champs des informations du document.
| Key | Data Type | Description | Example |
|---|---|---|---|
/Title |
Text String | Document title (separate from any visible title) | “Annual Report 2024” |
/Subject |
Text String | Document subject or description | “Financial Performance Analysis” |
/Keywords |
Text String | Searchable keywords | “finance, quarterly, revenue” |
/Author |
Text String | Document creator | “Jane Smith” |
/Creator |
Text String | Original application that created the document | “Microsoft Word” |
/Producer |
Text String | Application that converted to PDF | “Adobe Acrobat” |
/CreationDate |
Date String | When the document was originally created | D:20240625132712+08’00’ |
/ModDate |
Date String | Last modification timestamp | D:20240626094530+08’00’ |
⚠️ Distinzione importante.
La /Creator et /Producer Les champs Creator et Producer servent à des fins différentes : Creator identifie l'application d'origine (comme Microsoft Word), tandis que Producer identifie le logiciel qui a généré le fichier PDF final (comme Adobe Acrobat ou un pilote d'imprimante PDF).
📋 Dictionnaire complet des informations du document :
|
1 2 3 4 5 6 7 8 9 10 |
<< /ModDate (D:20060926213913+02'00') /CreationDate (D:20060926213913+02'00') /Title (Product Catalog - UK Edition) /Creator (QuarkXPress: pictwpstops filter 1.0) /Producer (Acrobat Distiller 6.0 for Macintosh) /Author (James Smith) /Subject (Quarterly Product Showcase) /Keywords (products, catalog, prices, specifications) >> |
🏛️ Catalogue de documents : Le centre de contrôle principal.
Si le dictionnaire de la bande-annonce est le système GPS du PDF, alors le catalogue de documents est son centre de commande central. En tant qu'objet racine de l'ensemble du graphe de documents, le catalogue orchestre la manière dont tous les autres objets sont liés les uns aux autres et la manière dont le document se comporte lorsqu'il est visualisé ou imprimé.
Chaque objet dans un document PDF peut être atteint par des références directes ou indirectes, en commençant par le catalogue de documents. Cette approche centralisée garantit une navigation efficace et maintient l'intégrité du document.
🎛️ Entrées essentielles du catalogue.
| Key | Type | Purpose | Required? |
|---|---|---|---|
/Type |
Name | Must be /Catalog |
✅ Yes |
/Pages |
Indirect Reference | Root of the page tree structure | ✅ Yes |
/PageLabels |
Number Tree | Enables complex page numbering (i, ii, iii, 1, 2, 3) | ❌ Optional |
/Names |
Dictionary | Name trees for referencing objects by name | ❌ Optional |
/Dests |
Dictionary | Named destinations for hyperlinks | ❌ Optional |
/ViewerPreferences |
Dictionary | Controls PDF viewer behavior | ❌ Optional |
/PageMode |
Name | Default viewing mode (thumbnails, bookmarks, etc.) | ❌ Optional |
/PageLayout |
Name | Page display layout (single, facing pages, etc.) | ❌ Optional |
/Outlines |
Indirect Reference | Document bookmarks/outline structure | ❌ Optional |
/Metadata |
Indirect Reference | XMP metadata stream | ❌ Optional |
🎨 Préférences du visualiseur : Contrôle de l'expérience utilisateur.
La /ViewerPreferences Le dictionnaire permet aux auteurs de documents d'influencer la façon dont les lecteurs PDF affichent leurs documents. Cela peut inclure la dissimulation des barres d'outils, l'ajustement des pages à la fenêtre, ou même le contrôle des paramètres d'impression.
📚 Explication des options de mode de page
- /UseNone – Document uniquement, sans panneaux de navigation
- /UseOutlines – Afficher le panneau des signets
- /UseThumbs – Afficher les miniatures des pages
- /FullScreen – Entrer en mode présentation
- /UseOC – Afficher le panneau des contenus optionnels (calques)
- /UseAttachments – Afficher le panneau des pièces jointes
🌳 Pages et arbres de pages : organiser le contenu efficacement
L'une des décisions de conception les plus ingénieuses de PDF concerne la manière dont il organise les pages. Au lieu d'utiliser une simple liste linéaire, PDF utilise une structure arborescente qui améliore considérablement les performances, en particulier pour les documents volumineux.
Imaginez essayer de trouver une page spécifique dans un document de 1000 pages en vérifiant chaque page séquentiellement : cela pourrait prendre jusqu'à 1000 opérations ! La structure en arbre des pages réduit cela à seulement quelques opérations, ce qui rend les lecteurs de PDF remarquablement rapides, même avec des documents volumineux.
🏗️ Comprendre la structure du dictionnaire de page.
Chaque page d'un PDF est représentée par un dictionnaire de page qui regroupe tous les éléments nécessaires pour afficher cette page spécifique : instructions de contenu, ressources (polices, images) et spécifications de mise en page.
| Key | Type | Purpose | Inheritance |
|---|---|---|---|
/Type |
Name | Must be /Page |
❌ |
/Parent |
Indirect Reference | Parent node in page tree | ❌ |
/Resources |
Dictionary | Fonts, images, other resources | ✅ From parent if missing |
/Contents |
Stream/Array | Page content instructions | ❌ |
/MediaBox |
Rectangle | Physical page size | ✅ From parent if missing |
/CropBox |
Rectangle | Visible page area | ✅ Defaults to MediaBox |
/Rotate |
Integer | Page rotation (0, 90, 180, 270) | ✅ From parent if missing |
📐 Comprendre les systèmes de coordonnées PDF.
PDF utilise un système de coordonnées sophistiqué basé sur des rectangles définis par quatre nombres représentant les coins diagonaux. Comprendre ce système est essentiel pour travailler avec les mises en page de pages.
📏 Exemples de définition de rectangles :
|
1 2 |
/MediaBox [0 0 595 842] # A4 size in points (8.27" × 11.69") /CropBox [50 50 545 792] # A4 with 50-point margins on all sides |
💡 Unités de mesure PDF.
PDF utilise les points comme unité de mesure de base, où 1 point = 1/72 de pouce. Cela rend les calculs simples : 72 points = 1 pouce, 144 points = 2 pouces, etc.
🌲 L'architecture de l'arbre de pages.
La force de l'architecture de l'arbre de pages réside dans sa structure équilibrée. Les bonnes applications PDF créent des arbres où n'importe quelle page peut être localisée en quelques étapes, quelle que soit la taille du document.
🌳 Exemple d'architecture de l'arbre de pages.
/Type /Pages
/Count 7
/Count 3
/Count 2
/Type /Page
/Type /Page
Figure 2: Structure arborescente des pages pour un document de 7 pages, présentant une hiérarchie équilibrée pour un accès efficace.
🎯 Avantages de la structure arborescente :
- Temps d'accès logarithmique – Trouver n'importe quelle page en O(log n) opérations.
- Utilisation efficace de la mémoire. – Chargez uniquement les portions nécessaires de documents volumineux.
- Architecture évolutive. – Les performances restent constantes, même lorsque les documents augmentent.
- Optimisation de l'héritage. – Les propriétés communes sont partagées entre les groupes de pages.
📝 Structure des nœuds de l'arborescence des pages.
| Key | Type | Purpose |
|---|---|---|
/Type |
Name | Must be /Pages |
/Kids |
Array | References to child nodes (pages or page trees) |
/Count |
Integer | Total number of leaf pages under this node |
/Parent |
Reference | Parent node (required unless root) |
🏗️ Exemple d'implémentation de l'arborescence des pages :
|
1 2 3 4 5 6 7 8 |
1 0 obj % Root node << /Type /Pages /Kids [2 0 R 3 0 R 4 0 R] /Count 7 >> endobj 2 0 obj % Intermediate node << /Type /Pages /Kids [5 0 R 6 0 R 7 0 R] /Parent 1 0 R /Count 3 >> endobj 5 0 obj % Actual page << /Type /Page /Parent 2 0 R /MediaBox [0 0 612 792] /Resources << >> >> endobj |
🔤 Chaînes de texte : Gestion de plusieurs encodages.
La portée mondiale des fichiers PDF nécessite des capacités robustes de gestion du texte. Le format prend en charge plusieurs schémas d'encodage pour s'adapter aux différentes langues et jeux de caractères, garantissant que les documents s'affichent correctement, quel que soit le pays de l'utilisateur.
La compréhension de l'encodage du texte PDF est essentielle pour toute personne travaillant avec des documents internationaux ou développant des applications de traitement de fichiers PDF.
📝 Deux méthodes d'encodage principales.
1. PDFDocEncoding
Basé sur l'ISO Latin-1, PDFDocEncoding gère efficacement la plupart des langues d'Europe occidentale. C'est l'encodage par défaut pour les chaînes de texte PDF et offre une excellente compatibilité avec les systèmes existants.
2. Unicode (UTF-16BE)
Pour les caractères internationaux et les scripts complexes, PDF utilise Unicode avec l'encodage UTF-16BE. Les chaînes Unicode sont identifiées par un marqueur d'ordre des octets (BOM) spécial au début.
🔍 Détection des chaînes Unicode.
Les lecteurs PDF déterminent l'encodage en examinant les deux premiers octets d'une chaîne de texte.
|
1 2 3 4 |
If bytes[0] == 254 AND bytes[1] == 255: encoding = "UTF-16BE" # Unicode byte-order marker U+FEFF else: encoding = "PDFDocEncoding" # Default PDF encoding |
⚠️ Contrainte d'encodage.
En raison du mécanisme de détection Unicode, les chaînes PDFDocEncoding ne peuvent pas commencer par la séquence d'octets [254, 255] (þÿ). Cependant, cette limitation affecte rarement les documents réels.
📅 Formats de date : informations temporelles précises.
PDF utilise un format de date sophistiqué qui capture non seulement quand quelque chose s'est produit, mais prend également en compte les fuseaux horaires, ce qui est essentiel pour les flux de travail documentaires mondiaux et les exigences légales.
📋 Structure du format de date PDF.
|
1 |
(D:YYYYMMDDHHmmSSOHH'mm') |
| Component | Meaning | Format | Example |
|---|---|---|---|
| YYYY | Year | Four digits | 2025 |
| MM | Month | 01-12 | 06 (June) |
| DD | Day | 01-31 | 25 |
| HH | Hour | 00-23 | 13 (1 PM) |
| mm | Minute | 00-59 | 27 |
| SS | Second | 00-59 | 12 |
| O | UTC Offset | +, -, or Z | + (later than UTC) |
| HH’ | Offset Hours | 00-23 | 08 (8 hours) |
| mm’ | Offset Minutes | 00-59 | 00 (no minutes) |
🌍 Exemples de fuseaux horaires.
|
1 2 3 |
(D:20250625132712+08'00') # June 25, 2024, 1:27:12 PM, UTC+8 (Beijing) (D:20250625132712-05'00') # Same moment in Eastern Standard Time (D:20250625132712Z) # Same moment in UTC (Zulu time) |
🕐 Précision de date flexible.
Les dates PDF prennent en charge une précision variable. Vous pouvez spécifier uniquement l'année. (D:2025), ou inclure la précision complète jusqu'aux secondes et aux fuseaux horaires. Les composants manquants prennent par défaut des valeurs raisonnables (01 pour le mois/le jour, 00 pour les composantes temporelles).
🧩 Rassembler le tout : un exemple complet.
Examinons un exemple complet de fichier PDF, créé manuellement, qui illustre tous les concepts que nous avons abordés. Ce document de trois pages met en évidence l'interaction entre tous les éléments structurels du fichier PDF.
📄 Exemple complet de structure PDF :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
%PDF-1.0 % Header 1 0 obj % Document catalog << /PageLayout /TwoColumnLeft /Pages 2 0 R /Type /Catalog >> endobj 2 0 obj % Root of page tree << /Kids [3 0 R 4 0 R] /Type /Pages /Count 3 >> endobj 3 0 obj % Page one << /Type /Page /Parent 2 0 R /MediaBox [0 0 612 792] % US Letter size /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [5 0 R] >> endobj 4 0 obj % Intermediate page tree node << /Parent 2 0 R /Kids [6 0 R 7 0 R] /Count 2 /Type /Pages >> endobj 5 0 obj % Content stream for page one << /Length 58 >> stream BT /F0 24 Tf 50 750 Td (Hello, PDF World!) Tj ET endstream endobj 6 0 obj % Page two << /Type /Page /Parent 4 0 R /MediaBox [0 0 612 792] /Rotate 90 % Landscape orientation /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [8 0 R] >> endobj 7 0 obj % Page three << /Type /Page /Parent 4 0 R /MediaBox [0 0 612 792] /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [9 0 R] >> endobj 8 0 obj % Content stream for page two << /Length 72 >> stream BT /F0 18 Tf 50 700 Td (This page is rotated 90 degrees) Tj ET endstream endobj 9 0 obj % Content stream for page three << /Length 45 >> stream BT /F0 24 Tf 50 750 Td (Final page) Tj ET endstream endobj 10 0 obj % Document information dictionary << /Title (PDF Structure Example) /Author (PDF Guide Author) /Producer (Manual Creation) /CreationDate (D:20240625132712+08'00') /ModDate (D:20240625133045+08'00') /Subject (Demonstrating PDF internal structure) /Keywords (PDF, structure, example, tutorial) >> endobj xref % Cross-reference table 0 11 0000000000 65535 f 0000000015 00000 n 0000000074 00000 n 0000000120 00000 n 0000000355 00000 n 0000000415 00000 n 0000000522 00000 n 0000000747 00000 n 0000000958 00000 n 0000001079 00000 n 0000001173 00000 n trailer % Trailer dictionary << /Size 11 /Root 1 0 R /Info 10 0 R /ID [<A1B2C3D4E5F6789012345678901234AB> <A1B2C3D4E5F6789012345678901234AB>] >> startxref 1456 %%EOF |
🗺️ Graphe de références d'objets.
/Size 11
/Root 1 0 R → Document Catalog
/Info 10 0 R → Document Info
/Type /Catalog
/Pages 2 0 R
/Title /Author
/CreationDate /ModDate
/Type /Pages
/Kids [3 0 R 4 0 R]
/Count 3
/Type /Page
/Contents [5 0 R]
/Kids [6 0 R 7 0 R]
/Count 2
/Contents [8 0 R]
/Rotate 90
/Contents [9 0 R]
Figure 3 : Graphe de références des objets montrant comment le dictionnaire de la remorque se connecte à tous les composants du document.
🔍 Analyse de la structure de l'exemple.
🎯 Observations clés :
- Navigation efficace. – Toute page accessible en un maximum de 2 étapes depuis la racine.
- Héritage des ressources. – Les ressources de police peuvent être héritées des nœuds parents.
- Disposition flexible. – La page 2 illustre les capacités de rotation.
- Métadonnées riches. – Informations complètes sur le document pour la gestion des flux de travail.
- Identification unique. – Le tableau d'ID permet le suivi des documents.
🚀 Sujets avancés et bonnes pratiques.
🔧 Stratégies d'optimisation.
📈 Conseils pour l'optimisation des performances.
- Arbres équilibrés. – Maintenir des temps d'accès logarithmiques pour les grands documents.
- Partage des ressources. – Placer les ressources communes dans les nœuds de l'arborescence des pages parent.
- Codage efficace. – Utiliser PDFDocEncoding pour le texte occidental, Unicode uniquement lorsque cela est nécessaire.
- Héritage correct. – Tirer parti de l'héritage de l'arborescence des pages pour les propriétés communes.
- Métadonnées minimales. – Inclure uniquement les entrées de dictionnaire contenant les informations nécessaires.
🛡️ Prévention et validation des erreurs.
⚠️ Pièges courants à éviter :
- Références rompues. – S'assurer que toutes les références indirectes pointent vers des objets valides.
- Comptages incohérents. – Les comptages de l'arborescence des pages doivent refléter avec précision les pages terminales.
- Champs obligatoires manquants. – Inclure toujours les entrées obligatoires du dictionnaire.
- Formats de date invalides. – Respecter scrupuleusement les spécifications de format de date.
- Incompatibilités de codage. – Identifier correctement les chaînes Unicode par rapport aux chaînes PDFDocEncoding.
🔮 Considérations futures.
Au fur et à mesure que le format PDF continue d'évoluer, la compréhension de ces structures fondamentales devient de plus en plus précieuse. Les fonctionnalités modernes du PDF, telles que les signatures numériques, les balises d'accessibilité et les formulaires interactifs, s'appuient toutes sur la base solide que nous avons explorée.
🌟 Technologies PDF émergentes :
- Normes PDF/A – Formats d'archivage à long terme
- Accessibilité PDF/UA – Conformité à l'accessibilité universelle
- Formulaires interactifs – Contenu dynamique et interaction utilisateur
- Signatures numériques – Intégrité cryptographique des documents.
- Contenu 3D. – Intégration de modèles tridimensionnels.
🎯 Conclusion : Maîtriser la structure des PDF.
Comprendre la structure interne des PDF ouvre la voie à un traitement avancé des documents, au dépannage et à l'optimisation. De la navigation offerte par le dictionnaire de la remorque à l'organisation efficace des arbres de pages, chaque composant a un objectif précis dans la création des documents robustes et portables sur lesquels nous nous appuyons quotidiennement.
🏆 Points clés :
- Conception hiérarchique. – La structure basée sur des arbres des PDF permet une mise à l'échelle efficace.
- Navigation intelligente. – Les tableaux de référence croisée et les dictionnaires permettent un accès rapide.
- Encodage flexible. – Prise en charge de plusieurs encodages de texte pour l'échange mondial de documents.
- Métadonnées riches. – Le suivi complet des informations prend en charge les flux de travail complexes.
- Modèle d'héritage. – Le partage de ressources réduit la redondance et la taille des fichiers.
« La beauté du PDF ne réside pas dans sa complexité, mais dans la manière dont cette complexité est élégamment organisée pour atteindre l'objectif simple de la portabilité universelle des documents. »
Cette exploration approfondie de la structure PDF vise à démystifier les aspects techniques de l'un des formats de documents les plus importants au monde. Comprendre ces aspects internes permet aux développeurs, aux gestionnaires de documents et aux personnes curieuses de travailler plus efficacement avec la technologie PDF. Il est recommandé d'utiliser des bibliothèques de développement PDF matures pour simplifier considérablement vos tâches de traitement PDF.