Entendiendo la estructura interna de PDF.
Bienvenido al fascinante mundo de los entresijos de PDF. ¿Alguna vez te has preguntado qué hace que un archivo PDF funcione? Más allá de los documentos familiares que vemos a diario, existe una arquitectura sofisticada que ha revolucionado el intercambio de documentos digitales. En esta exploración exhaustiva, desentrañaremos las capas de la estructura de PDF, revelando los mecanismos intrincados que hacen que estos archivos omnipresentes funcionen.
🔍 Introducción: Más allá de la superficie.
El formato de documento portátil (PDF) se ha convertido en el estándar de facto para el intercambio de documentos en todo el mundo. Desde documentos de texto simples hasta formularios interactivos complejos, los PDF mantienen una apariencia consistente en diferentes plataformas y dispositivos. Pero, ¿qué hay debajo de esta compatibilidad universal?
En esta inmersión profunda, exploraremos la estructura lógica que hace que los archivos PDF sean realmente portátiles. Examinaremos los componentes fundamentales: el diccionario de cola, catálogo del documento.y árbol de páginas—el trío que orquesta la funcionalidad de cada archivo PDF. También descubriremos los secretos de los formatos de datos especializados de PDF para cadenas de texto y fechas.
🎯 Lo que aprenderá en esta guía:
- Los cuatro componentes fundamentales de la estructura de PDF.
- Cómo PDF organiza y referencia el contenido de manera eficiente.
- El papel de los diccionarios, los catálogos y los árboles de páginas.
- Los enfoques únicos de PDF para la codificación de texto y el formato de fechas.
- Ejemplos del mundo real de estructuras de objetos PDF.
- Mejores prácticas para comprender el funcionamiento interno de PDF.
📋 La anatomía de un PDF: Visión general de alto nivel.
Antes de profundizar en los detalles, establezcamos un modelo mental de la estructura de PDF. Piensa en un PDF como un sistema de archivos sofisticado donde cada pieza de información tiene un lugar y un propósito específicos.
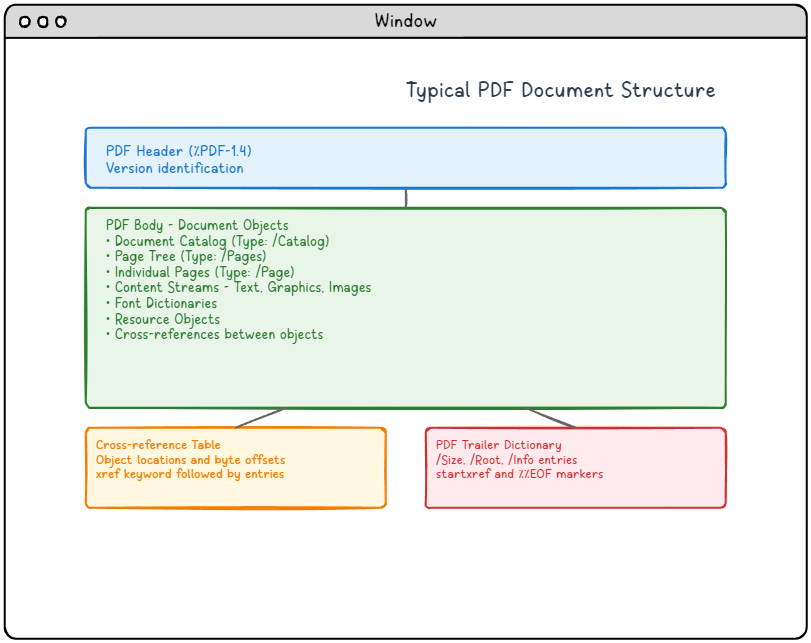
Figura 1: Estructura típica de un documento PDF que muestra los cuatro componentes principales y sus relaciones.
Descripción detallada del diagrama de la estructura de PDF:
Este diagrama ilustra la estructura típica de un documento PDF con cuatro componentes principales dispuestos verticalmente:
-
- Encabezado PDF (sección azul en la parte superior): Contiene la identificación de la versión (%PDF-1.4) que especifica la versión del formato PDF.
- Cuerpo del PDF (sección verde en el centro): La sección más grande que contiene todos los objetos del documento, incluyendo el catálogo del documento, el árbol de páginas, las páginas individuales, los flujos de contenido con texto/gráficos/imágenes, los diccionarios de fuentes, los objetos de recursos y las referencias cruzadas entre objetos.
- Tabla de referencias cruzadas (sección naranja en la parte inferior izquierda): Contiene las ubicaciones de los objetos y los desplazamientos de bytes, marcados con la palabra clave xref seguida de las entradas.
- Diccionario de cola del PDF (sección roja en la parte inferior derecha): Contiene información de navegación esencial, incluyendo las entradas /Size, /Root, /Info, y termina con los marcadores startxref y %%EOF.
Las flechas muestran el flujo lógico desde el encabezado al cuerpo, y luego se ramifican tanto a la tabla de referencias cruzadas como al diccionario del pie de página, lo que ilustra cómo los lectores de PDF navegan por la estructura del documento.
Un documento PDF consta de cuatro elementos estructurales principales que funcionan en armonía:
🏗️ Los Cuatro Pilares de la Estructura de PDF:
- Encabezado – Identifica la versión y las capacidades del PDF.
- Cuerpo – Contiene todos los objetos del documento (texto, imágenes, fuentes, etc.).
- Tabla de referencias cruzadas. – Mapea las ubicaciones de los objetos para un acceso rápido.
- Remolque. – Proporciona el punto de entrada para navegar por el documento.
Esta estructura permite que el PDF tenga una eficiencia notable en el manejo de documentos de cualquier tamaño, desde simples cartas de una página hasta manuales técnicos masivos con miles de páginas.
🗂️ El Diccionario del Remolque: El Sistema de GPS de tu PDF.
Imagina intentar navegar por una biblioteca sin un sistema de catálogo: ¡el caos se desataría! El diccionario del remolque sirve como el sofisticado sistema de navegación de PDF, proporcionando el mapa esencial que los lectores de PDF utilizan para comprender y mostrar tu documento.
Ubicado al final del archivo PDF, el diccionario del remolque es, paradójicamente, una de las primeras cosas que se procesan al abrir un PDF. Contiene la información crucial que permite al software localizar e interpretar todos los demás componentes del documento.
🔑 Entradas esenciales en el diccionario del remolque.
| Key | Type | Purpose | Required? |
|---|---|---|---|
/Size |
Integer | Total entries in cross-reference table (usually objects + 1) | ✅ Yes |
/Root |
Indirect Reference | Points to the document catalog—the master control center | ✅ Yes |
/Info |
Indirect Reference | Links to document metadata (title, author, creation date) | ❌ Optional |
/ID |
Array of Strings | Unique document identifier for workflow management | ❌ Optional |
💡 Consejo: Comprender los ID de PDF.
El /ID El array contiene dos cadenas: la primera se establece cuando se crea el documento y nunca cambia, mientras que la segunda se actualiza cada vez que se modifica el documento. Este sistema de doble identificador permite flujos de trabajo sofisticados de gestión de documentos.
📄 Ejemplo práctico de diccionario de trailers:
|
1 2 3 4 5 6 |
<< /Size 421 /Root 377 0 R /Info 375 0 R /ID [<5sazn0fs3tamppia2izf569h281104ae> <6cig0wa61ti593bzuwy41905tr6s5c5a>] >> |
Este ejemplo muestra un trailer para un documento con 421 objetos, donde el objeto 377 sirve como catálogo del documento y el objeto 375 contiene la información del documento.
📊 Diccionario de información del documento: metadatos tradicionales de PDF.
El diccionario de información del documento contiene las fechas de creación y modificación del archivo, junto con algunos metadatos simples. Este es el sistema de metadatos tradicional utilizado en versiones más antiguas de PDF, y no debe confundirse con los metadatos XMP más completos que se tratarán en futuros artículos.
Piense en este diccionario como una entrada básica de catálogo de biblioteca. Aunque no es esencial para mostrar el documento, proporciona información fundamental sobre el origen y la historia del documento utilizando cadenas de texto simples.
📋 Campos de información del documento.
| Key | Data Type | Description | Example |
|---|---|---|---|
/Title |
Text String | Document title (separate from any visible title) | “Annual Report 2024” |
/Subject |
Text String | Document subject or description | “Financial Performance Analysis” |
/Keywords |
Text String | Searchable keywords | “finance, quarterly, revenue” |
/Author |
Text String | Document creator | “Jane Smith” |
/Creator |
Text String | Original application that created the document | “Microsoft Word” |
/Producer |
Text String | Application that converted to PDF | “Adobe Acrobat” |
/CreationDate |
Date String | When the document was originally created | D:20240625132712+08’00’ |
/ModDate |
Date String | Last modification timestamp | D:20240626094530+08’00’ |
⚠️ Distinción importante.
El /Creator y /Producer Los campos sirven para diferentes propósitos: Creator identifica la aplicación original que creó el documento (como Microsoft Word), mientras que Producer identifica el software que generó el PDF final (como Adobe Acrobat o un controlador de impresora PDF).
📋 Diccionario completo de información del documento:
|
1 2 3 4 5 6 7 8 9 10 |
<< /ModDate (D:20060926213913+02'00') /CreationDate (D:20060926213913+02'00') /Title (Product Catalog - UK Edition) /Creator (QuarkXPress: pictwpstops filter 1.0) /Producer (Acrobat Distiller 6.0 for Macintosh) /Author (James Smith) /Subject (Quarterly Product Showcase) /Keywords (products, catalog, prices, specifications) >> |
🏛️ Catálogo de documentos: El centro de control principal.
Si el diccionario del trailer es el sistema de GPS del PDF, entonces el catálogo del documento es su centro de comando central. Como el objeto raíz de todo el grafo del documento, el catálogo organiza cómo se relacionan todos los demás objetos entre sí y cómo se comporta el documento al ser visualizado o impreso.
Cada objeto en un documento PDF se puede acceder a través de referencias directas o indirectas, comenzando desde el catálogo del documento. Este enfoque centralizado garantiza una navegación eficiente y mantiene la integridad del documento.
🎛️ Entradas esenciales del catálogo.
| Key | Type | Purpose | Required? |
|---|---|---|---|
/Type |
Name | Must be /Catalog |
✅ Yes |
/Pages |
Indirect Reference | Root of the page tree structure | ✅ Yes |
/PageLabels |
Number Tree | Enables complex page numbering (i, ii, iii, 1, 2, 3) | ❌ Optional |
/Names |
Dictionary | Name trees for referencing objects by name | ❌ Optional |
/Dests |
Dictionary | Named destinations for hyperlinks | ❌ Optional |
/ViewerPreferences |
Dictionary | Controls PDF viewer behavior | ❌ Optional |
/PageMode |
Name | Default viewing mode (thumbnails, bookmarks, etc.) | ❌ Optional |
/PageLayout |
Name | Page display layout (single, facing pages, etc.) | ❌ Optional |
/Outlines |
Indirect Reference | Document bookmarks/outline structure | ❌ Optional |
/Metadata |
Indirect Reference | XMP metadata stream | ❌ Optional |
🎨 Preferencias del visor: Controlando la experiencia del usuario.
El /ViewerPreferences El diccionario permite a los autores de documentos influir en cómo los visores de PDF muestran sus documentos. Esto puede incluir ocultar barras de herramientas, ajustar las páginas a las ventanas o incluso controlar la configuración de impresión.
📚 Explicación de las opciones de modo de página
- /UseNone – Solo documento, sin paneles de navegación
- /UseOutlines – Mostrar el panel de marcadores
- /UseThumbs – Mostrar miniaturas de página
- /FullScreen – Entrar en modo presentación
- /UseOC – Mostrar el panel de contenido opcional (capas)
- /UseAttachments – Mostrar el panel de adjuntos
🌳 Páginas y Árboles de Páginas: Organizando el Contenido de Forma Eficiente
Una de las decisiones de diseño más ingeniosas de PDF es cómo organiza las páginas. En lugar de usar una simple lista lineal, PDF emplea una estructura de árbol que mejora drásticamente el rendimiento, especialmente para documentos grandes.
Imagina intentar encontrar una página específica en un documento de 1000 páginas revisando cada página secuencialmente; ¡podría llevar hasta 1000 operaciones! La estructura de árbol de páginas reduce esto a solo unas pocas operaciones, lo que hace que los visores de PDF sean notablemente rápidos incluso con documentos masivos.
🏗️ Comprensión de la estructura del diccionario de páginas.
Cada página en un PDF está representada por un diccionario de página que reúne todos los elementos necesarios para renderizar esa página específica: instrucciones de contenido, recursos (fuentes, imágenes) y especificaciones de diseño.
| Key | Type | Purpose | Inheritance |
|---|---|---|---|
/Type |
Name | Must be /Page |
❌ |
/Parent |
Indirect Reference | Parent node in page tree | ❌ |
/Resources |
Dictionary | Fonts, images, other resources | ✅ From parent if missing |
/Contents |
Stream/Array | Page content instructions | ❌ |
/MediaBox |
Rectangle | Physical page size | ✅ From parent if missing |
/CropBox |
Rectangle | Visible page area | ✅ Defaults to MediaBox |
/Rotate |
Integer | Page rotation (0, 90, 180, 270) | ✅ From parent if missing |
📐 Comprensión de los sistemas de coordenadas de PDF.
PDF utiliza un sistema de coordenadas sofisticado basado en rectángulos definidos por cuatro números que representan las esquinas diagonales. Comprender este sistema es crucial para trabajar con diseños de página.
📏 Ejemplos de definición de rectángulos:
|
1 2 |
/MediaBox [0 0 595 842] # A4 size in points (8.27" × 11.69") /CropBox [50 50 545 792] # A4 with 50-point margins on all sides |
💡 Unidades de medida de PDF.
PDF utiliza puntos como su unidad básica de medida, donde 1 punto = 1/72 de pulgada. Esto hace que los cálculos sean sencillos: 72 puntos = 1 pulgada, 144 puntos = 2 pulgadas, etc.
La arquitectura de árbol de páginas.
La brillantez de la arquitectura de árbol reside en su estructura equilibrada. Las buenas aplicaciones de PDF crean árboles donde cualquier página se puede encontrar en solo unos pocos pasos, independientemente del tamaño del documento.
Ejemplo de arquitectura de árbol de páginas.
/Type /Pages
/Count 7
/Count 3
/Count 2
/Type /Page
/Type /Page
Figura 2: Estructura de árbol de páginas para un documento de 7 páginas, mostrando una jerarquía equilibrada para un acceso eficiente.
🎯 Beneficios del rendimiento de la estructura de árbol de páginas:
- Tiempo de acceso logarítmico – Encuentra cualquier página en O(log n) operaciones.
- Uso eficiente de la memoria. – Carga solo las porciones necesarias de documentos grandes.
- Arquitectura escalable. – El rendimiento se mantiene constante a medida que los documentos crecen.
- Optimización de la herencia. – Propiedades comunes compartidas entre grupos de páginas.
📝 Estructura del nodo del árbol de páginas.
| Key | Type | Purpose |
|---|---|---|
/Type |
Name | Must be /Pages |
/Kids |
Array | References to child nodes (pages or page trees) |
/Count |
Integer | Total number of leaf pages under this node |
/Parent |
Reference | Parent node (required unless root) |
🏗️ Ejemplo de implementación del árbol de páginas:
|
1 2 3 4 5 6 7 8 |
1 0 obj % Root node << /Type /Pages /Kids [2 0 R 3 0 R 4 0 R] /Count 7 >> endobj 2 0 obj % Intermediate node << /Type /Pages /Kids [5 0 R 6 0 R 7 0 R] /Parent 1 0 R /Count 3 >> endobj 5 0 obj % Actual page << /Type /Page /Parent 2 0 R /MediaBox [0 0 612 792] /Resources << >> >> endobj |
🔤 Cadenas de texto: Manejo de múltiples codificaciones.
El alcance global de PDF requiere sólidas capacidades de manejo de texto. El formato admite múltiples esquemas de codificación para adaptarse a diferentes idiomas y conjuntos de caracteres, lo que garantiza que los documentos se muestren correctamente independientemente de la ubicación del usuario.
Comprender la codificación de texto de PDF es crucial para cualquier persona que trabaje con documentos internacionales o desarrolle aplicaciones de procesamiento de PDF.
📝 Dos métodos de codificación principales.
1. PDFDocEncoding
Basado en ISO Latin-1, PDFDocEncoding maneja la mayoría de los idiomas europeos occidentales de manera eficiente. Es la codificación predeterminada para las cadenas de texto de PDF y proporciona una excelente compatibilidad con los sistemas heredados.
2. Unicode (UTF-16BE)
Para caracteres internacionales y scripts complejos, PDF utiliza Unicode con codificación UTF-16BE. Las cadenas Unicode se identifican mediante un marcador de orden de bytes (BOM) al principio.
🔍 Detección de cadenas Unicode.
Los visores de PDF determinan la codificación examinando los dos primeros bytes de una cadena de texto:
|
1 2 3 4 |
If bytes[0] == 254 AND bytes[1] == 255: encoding = "UTF-16BE" # Unicode byte-order marker U+FEFF else: encoding = "PDFDocEncoding" # Default PDF encoding |
⚠️ Restricción de codificación.
Debido al mecanismo de detección de Unicode, las cadenas PDFDocEncoding no pueden comenzar con la secuencia de bytes [254, 255] (þÿ). Sin embargo, esta limitación rara vez afecta a los documentos reales.
📅 Formatos de fecha: información temporal precisa.
PDF utiliza un formato de fecha sofisticado que captura no solo cuándo ocurrió algo, sino que también tiene en cuenta las zonas horarias, lo cual es crucial para los flujos de trabajo de documentos globales y los requisitos legales.
📋 Estructura del formato de fecha de PDF.
|
1 |
(D:YYYYMMDDHHmmSSOHH'mm') |
| Component | Meaning | Format | Example |
|---|---|---|---|
| YYYY | Year | Four digits | 2025 |
| MM | Month | 01-12 | 06 (June) |
| DD | Day | 01-31 | 25 |
| HH | Hour | 00-23 | 13 (1 PM) |
| mm | Minute | 00-59 | 27 |
| SS | Second | 00-59 | 12 |
| O | UTC Offset | +, -, or Z | + (later than UTC) |
| HH’ | Offset Hours | 00-23 | 08 (8 hours) |
| mm’ | Offset Minutes | 00-59 | 00 (no minutes) |
🌍 Ejemplos de zonas horarias.
|
1 2 3 |
(D:20250625132712+08'00') # June 25, 2024, 1:27:12 PM, UTC+8 (Beijing) (D:20250625132712-05'00') # Same moment in Eastern Standard Time (D:20250625132712Z) # Same moment in UTC (Zulu time) |
🕐 Precisión de fecha flexible.
Las fechas en PDF admiten una precisión variable. Puede especificar solo el año. (D:2025), o incluya la precisión completa hasta los segundos y las zonas horarias. Los componentes faltantes toman valores predeterminados razonables (01 para mes/día, 00 para los componentes de tiempo).
🧩 Poniéndolo todo junto: un ejemplo completo.
Analicemos un ejemplo completo de un archivo PDF, creado manualmente, que demuestra todos los conceptos que hemos discutido. Este documento de tres páginas muestra la interacción entre todos los elementos estructurales de un PDF.
📄 Ejemplo completo de estructura de PDF:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
%PDF-1.0 % Header 1 0 obj % Document catalog << /PageLayout /TwoColumnLeft /Pages 2 0 R /Type /Catalog >> endobj 2 0 obj % Root of page tree << /Kids [3 0 R 4 0 R] /Type /Pages /Count 3 >> endobj 3 0 obj % Page one << /Type /Page /Parent 2 0 R /MediaBox [0 0 612 792] % US Letter size /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [5 0 R] >> endobj 4 0 obj % Intermediate page tree node << /Parent 2 0 R /Kids [6 0 R 7 0 R] /Count 2 /Type /Pages >> endobj 5 0 obj % Content stream for page one << /Length 58 >> stream BT /F0 24 Tf 50 750 Td (Hello, PDF World!) Tj ET endstream endobj 6 0 obj % Page two << /Type /Page /Parent 4 0 R /MediaBox [0 0 612 792] /Rotate 90 % Landscape orientation /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [8 0 R] >> endobj 7 0 obj % Page three << /Type /Page /Parent 4 0 R /MediaBox [0 0 612 792] /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [9 0 R] >> endobj 8 0 obj % Content stream for page two << /Length 72 >> stream BT /F0 18 Tf 50 700 Td (This page is rotated 90 degrees) Tj ET endstream endobj 9 0 obj % Content stream for page three << /Length 45 >> stream BT /F0 24 Tf 50 750 Td (Final page) Tj ET endstream endobj 10 0 obj % Document information dictionary << /Title (PDF Structure Example) /Author (PDF Guide Author) /Producer (Manual Creation) /CreationDate (D:20240625132712+08'00') /ModDate (D:20240625133045+08'00') /Subject (Demonstrating PDF internal structure) /Keywords (PDF, structure, example, tutorial) >> endobj xref % Cross-reference table 0 11 0000000000 65535 f 0000000015 00000 n 0000000074 00000 n 0000000120 00000 n 0000000355 00000 n 0000000415 00000 n 0000000522 00000 n 0000000747 00000 n 0000000958 00000 n 0000001079 00000 n 0000001173 00000 n trailer % Trailer dictionary << /Size 11 /Root 1 0 R /Info 10 0 R /ID [<A1B2C3D4E5F6789012345678901234AB> <A1B2C3D4E5F6789012345678901234AB>] >> startxref 1456 %%EOF |
🗺️ Gráfico de referencias de objetos.
/Size 11
/Root 1 0 R → Document Catalog
/Info 10 0 R → Document Info
/Type /Catalog
/Pages 2 0 R
/Title /Author
/CreationDate /ModDate
/Type /Pages
/Kids [3 0 R 4 0 R]
/Count 3
/Type /Page
/Contents [5 0 R]
/Kids [6 0 R 7 0 R]
/Count 2
/Contents [8 0 R]
/Rotate 90
/Contents [9 0 R]
Figura 3: Gráfico de referencias de objetos que muestra cómo el diccionario del tráiler se conecta a todos los componentes del documento.
🔍 Análisis de la estructura de ejemplo.
🎯 Observaciones clave:
- Navegación eficiente. – Cualquier página accesible en un máximo de 2 pasos desde la raíz.
- Herencia de recursos. – Los recursos de fuente pueden heredarse de los nodos padre.
- Diseño flexible. – La página 2 muestra las capacidades de rotación.
- Metadatos enriquecidos. – Información completa del documento para la gestión de flujos de trabajo.
- Identificación única. – El array de ID permite el seguimiento de documentos.
🚀 Temas avanzados y mejores prácticas.
🔧 Estrategias de optimización.
📈 Consejos para la optimización del rendimiento:
- Árboles balanceados. – Mantener tiempos de acceso logarítmicos para documentos grandes.
- Compartición de recursos. – Colocar recursos comunes en nodos del árbol de páginas padre.
- Codificación eficiente. – Utilizar PDFDocEncoding para texto occidental, Unicode solo cuando sea necesario.
- Herencia adecuada. – Aprovechar la herencia del árbol de páginas para propiedades comunes.
- Metadatos mínimos. – Incluir solo las entradas de diccionario necesarias.
🛡️ Prevención y validación de errores.
⚠️ Errores comunes a evitar:
- Referencias rotas. – Asegurarse de que todas las referencias indirectas apunten a objetos válidos.
- Contadores inconsistentes. – Los conteos del árbol de páginas deben reflejar con precisión las páginas hoja.
- Campos obligatorios faltantes. – Siempre incluya las entradas obligatorias del diccionario.
- Formatos de fecha inválidos. – Siga las especificaciones precisas del formato de fecha.
- Desajustes de codificación. – Identifique correctamente las cadenas Unicode frente a PDFDocEncoding.
🔮 Consideraciones futuras.
A medida que PDF continúa evolucionando, comprender estas estructuras fundamentales se vuelve cada vez más valioso. Las características modernas de PDF, como las firmas digitales, las etiquetas de accesibilidad y los formularios interactivos, se basan en la sólida base que hemos explorado.
🌟 Tecnologías emergentes de PDF:
- Estándares PDF/A – Formatos de archivo a largo plazo
- Accesibilidad PDF/UA – Cumplimiento de la accesibilidad universal
- Formularios interactivos – Contenido dinámico e interacción con el usuario
- Firmas digitales – Integridad criptográfica de documentos.
- Contenido 3D. – Incorporación de modelos tridimensionales.
🎯 Conclusión: Dominando la estructura de PDF.
Comprender la estructura interna de PDF abre las puertas a un procesamiento avanzado de documentos, solución de problemas y optimización. Desde las capacidades de navegación del diccionario de cola hasta la organización eficiente de los árboles de páginas, cada componente cumple un propósito específico en la creación de los documentos robustos y portátiles en los que confiamos diariamente.
🏆 Puntos clave:
- Diseño jerárquico. – La estructura basada en árboles de PDF permite una escalabilidad eficiente.
- Navegación inteligente. – Las tablas y diccionarios de referencia cruzada proporcionan acceso rápido.
- Codificación flexible. – Admite múltiples codificaciones de texto para el intercambio global de documentos.
- Metadatos enriquecidos. – El seguimiento integral de la información admite flujos de trabajo complejos.
- Modelo de herencia. – El uso compartido de recursos reduce la redundancia y el tamaño del archivo.
"La belleza de PDF reside no en su complejidad, sino en cómo esa complejidad se organiza elegantemente para servir al objetivo simple de la portabilidad universal de los documentos".
Esta exploración exhaustiva de la estructura de PDF tiene como objetivo desmitificar los aspectos técnicos de uno de los formatos de documentos más importantes del mundo. Comprender estos aspectos internos permite a los desarrolladores, administradores de documentos y personas curiosas trabajar de manera más efectiva con la tecnología PDF. Se recomienda utilizar bibliotecas de desarrollo de PDF maduras para simplificar en gran medida sus tareas de procesamiento de PDF.