Comprensión de los metadatos y marcadores XML de PDF: Una guía técnica.
Temas clave cubiertos.
📍 Destinos.
Marcadores de ubicación precisos que definen posiciones específicas dentro de los documentos PDF. Estos permiten una navegación precisa para los marcadores y los hipervínculos, mientras que los esquemas de documentos proporcionan una funcionalidad de tabla de contenidos jerárquica.
📄 Metadatos XML.
Flujos XML estructurados que proporcionan metadatos completos del documento utilizando formatos XMP estandarizados, que van más allá de las propiedades básicas del documento para incluir información descriptiva rica.
📎 Archivos adjuntos.
Capacidad completa de incrustación de archivos que empaqueta recursos externos directamente dentro de documentos PDF, creando paquetes de documentos autocontenidos similares a los archivos adjuntos de correo electrónico.
📝 Anotaciones.
Elementos de superposición interactivos que agregan texto, gráficos y funcionalidad con capacidad de clic a las páginas PDF sin modificar el contenido subyacente. Incluye hipervínculos para una navegación perfecta del documento y varias herramientas de marcado para una mayor interacción del lector.
Marcadores y destinos.

La navegación del documento se basa en estructuras de marcadores jerárquicos, técnicamente conocidos como. esquema del documentoEste sistema organizado en árbol presenta entradas que se pueden hacer clic, que comúnmente son títulos de capítulos, encabezados de secciones y nombres de subsecciones, que permiten a los lectores saltar rápidamente a partes específicas del documento. Cada entrada de marcador combina texto de visualización con información de destino que especifica exactamente dónde debe navegar el enlace.
Comprensión de los destinos
Los destinos de PDF sirven como marcadores de ubicación precisos dentro de un documento, especificando qué página mostrar, dónde posicionar la vista en esa página y qué nivel de zoom aplicar. Puede crear destinos de dos maneras: definirlos directamente en línea (que usaremos en nuestros ejemplos para mayor claridad) o referenciarlos por nombre a través de un sistema de nombres de todo el documento. La mayoría de los lectores de PDF presentan los marcadores en un panel de navegación junto con el contenido principal del documento.
Cada destino utiliza una estructura de matriz donde los elementos específicos varían según el comportamiento de visualización que desea lograr. Aquí hay los patrones de destino principales disponibles:
Tabla de tipos de destino
Nota: "página" representa una referencia indirecta a un objeto de página. De forma predeterminada, estos destinos funcionan con los límites de la caja de recorte de la página, y recurren a la caja de medios cuando no se define una caja de recorte.
| Array | Description |
|---|---|
| [page /Fit] | Scales the page to fit completely within the viewer window, adjusting both width and height proportionally. |
| [page /FitH top] | Positions the specified top coordinate at the window’s top edge while scaling horizontally to fit the full page width. |
| [page /FitV left] | Aligns the specified left coordinate with the window’s left edge while scaling vertically to fit the full page height. |
| [page /XYZ left top zoom] | Positions the coordinates (left, top) at the window’s upper-left corner and applies the specified zoom factor. Null values preserve current settings for those parameters. |
| [page /FitR left bottom right top] | Zooms and positions the view to display the rectangular area defined by the left, bottom, right, and top coordinates. |
| [page /FitB] | Similar to /Fit, but scales based on the actual content boundaries instead of the defined crop box area. |
| [page /FitBH top] | Functions like /FitH but uses the content bounding box instead of the crop box for horizontal scaling calculations. |
| [page /FitBV left] | Operates like /FitV but calculates vertical scaling based on the content bounding box rather than the crop box boundaries. |
Estructura del esquema del documento
Los documentos con esquema crean una estructura de navegación jerárquica que funciona como un índice interactivo para los visores de PDF. Esta organización tipo árbol ayuda a los usuarios a navegar rápidamente por documentos complejos, proporcionando una visión general clara de la estructura. El sistema se basa en dos tipos fundamentales de objetos:
- Diccionario de esquema – La raíz de la jerarquía de esquema.
- Diccionarios de elementos de esquema – Entradas individuales en el esquema.
Estructura del diccionario de esquema (Tabla).
| Key | Value Type | Value |
|---|---|---|
| /Type | name | If present, must be /Outlines. |
| /First | indirect reference to dictionary | References the initial top-level outline entry in the document hierarchy. This field is mandatory when outline entries exist. |
| /Last | indirect reference to dictionary | References the final top-level outline entry in the document hierarchy. This field is mandatory when outline entries exist. |
| /Count | integer | Specifies how many outline entries are currently expanded across the entire outline tree. Can be omitted when no entries are in an open state. |
Implementación de elementos de esquema.
Cada elemento de esquema consta de un diccionario que especifica su título de visualización, destino y relaciones con otros elementos de la jerarquía.
Examinemos cómo se estructura un esquema simple de documento en la sintaxis PDF:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
8 0 obj <</Type/Outlines/Count 4/First 9 0 R/Last 9 0 R>> endobj 9 0 obj <</Title(Chapter 1: Experiment A)/Count 3/Parent 8 0 R/First 12 0 R/Last 18 0 R>> endobj 12 0 obj <</Title(1: Introduction)/Count 0/Parent 9 0 R/Next 15 0 R>> endobj 15 0 obj <</Title(2: Methodology)/Count 0/Parent 9 0 R/Prev 12 0 R/Next 18 0 R>> endobj 18 0 obj <</Title(3: Result verification)/Count 0/Parent 9 0 R/Prev 15 0 R/>> endobj |
Estructura de la tabla del diccionario de elementos del esquema.
* indica una entrada obligatoria.
| Key | Value Type | Value |
|---|---|---|
| /Title* | text string | Text to be displayed for this entry. |
| /Parent* | indirect reference to dictionary | References this item’s parent within the outline hierarchy, which can be either another outline item or the root outline dictionary. |
| /Prev | indirect reference to dictionary | References the preceding sibling item at the same hierarchical level, when applicable. |
| /Next | indirect reference to dictionary | References the following sibling item at the same hierarchical level, when applicable. |
| /First | indirect reference to dictionary | References the initial child item under this entry, when child items exist. |
| /Last | indirect reference to dictionary | References the final child item under this entry, when child items exist. |
| /Count | integer | When the entry is expanded, indicates the count of visible descendant entries. When collapsed, stores a negative value representing the total number of hidden descendants that would become visible upon expansion. |
| /Dest | name, string or array | The destination. Arrays are destinations, names are references to entries in the /Dests entry in the document catalog, strings are references to entries in the /Dests entry in the document’s name dictionary. |
Metadatos XML.
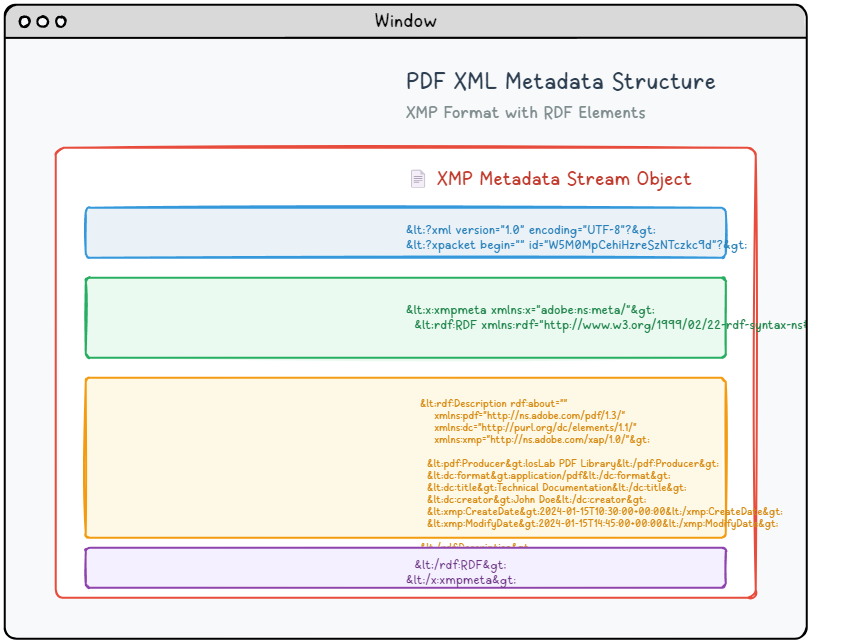
Los documentos PDF modernos pueden incorporar flujos de metadatos basados en XML que ofrecen información mucho más detallada y estructurada que las propiedades de documentos tradicionales. Este sistema de metadatos avanzado aprovecha la especificación XMP (Extensible Metadata Platform) de Adobe para proporcionar descripciones de documentos estandarizadas y legibles por máquina que mejoran la capacidad de búsqueda, la organización y las capacidades de procesamiento automatizado.
Estructura de los metadatos XMP.
Los metadatos XMP se empaquetan como un documento XML que utiliza la sintaxis RDF (Resource Description Framework) para organizar y describir las propiedades del documento en un formato estandarizado. Este contenido de metadatos se incrusta dentro de un objeto de flujo dedicado que incluye una identificación de tipo adecuada para los procesadores de PDF:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
6 0 obj <</Length 1235/Type/Metadata/Subtype/XML>>stream <?xpacket begin="锘xBF" id="W5M0MpCehiHzreSzNTczkc9d"?> <x:xmpmeta xmlns:x="adobe:ns:meta/" x:xmptk="Adobe XMP Core 5.2-c001 63.139439, 2010/09/27-13:37:26" ><rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" ><rdf:Description rdf:about="" xmlns:pdf="http://ns.adobe.com/pdf/1.3/" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:xmp="http://ns.adobe.com/xap/1.0/" ><pdf:Producer>losLab PDF Library</pdf:Producer> <dc:creator>losLab.com</dc:creator> <dc:title>Delphi PDF SDKs</dc:title> <xmp:CreateDate>2025-06-29T10:46:27+08:00</xmp:CreateDate> <xmp:ModifyDate>2025-06-29T10:58:57+08:00</xmp:ModifyDate> <xmp:MetadataDate>2025-06-29T10:46:27+08:00</xmp:MetadataDate> <dc:description>Delphi Development Library for PDF creation & editing</dc:description> <xmp:CreatorTool>HotPDF Component</xmp:CreatorTool> <dc:subject>PDF Developer Library for RAD Studio></dc:subject> <pdf:Keywords>Delphi, PDF SDK, PDF Component</pdf:Keywords> </rdf:Description>Robust Delphi PDF development library</rdf:RDF> </x:xmpmeta> <?xpacket end="w"?> endstream endobj |
Esquemas de metadatos estándar.
El framework XMP organiza los metadatos a través de espacios de nombres de esquema bien establecidos, cada uno sirviendo a categorías de información específicas:
📋 Dublin Core (dc:)
Información bibliográfica básica
- dc:title – Título del documento
- dc:creator – Autor(es) del documento
- dc:subject – Tema/palabras clave del documento
- dc:description – Descripción del documento
- dc:format – Tipo MIME
🏷️ XMP Basic (xmp:)
Propiedades básicas de XMP
- xmp:CreateDate – Fecha de creación
- xmp:ModifyDate – Fecha de modificación
- xmp:CreatorTool – Aplicación de creación
- xmp:MetadataDate – Fecha de modificación de metadatos
📄 Esquema PDF (pdf:)
Propiedades específicas de PDF
- pdf:Producer – Fabricante de PDF.
- pdf:Keywords – Palabras clave del documento.
- pdf:PDFVersion – Versión de PDF.
Integración con el catálogo de documentos.
El flujo de metadatos XML se referencia desde el catálogo de documentos:
|
1 2 3 |
1 0 obj < < Type Catalog Pages 2 0 R Metadata 10 0 R Outlines 1 0 R>> endobj |
🎯 Mejores prácticas para metadatos XML.
- Incluya siempre tanto el diccionario de información del documento como los metadatos XMP para una máxima compatibilidad.
- Asegúrese de que los valores de los metadatos sean consistentes entre ambas ubicaciones.
- Utilice la codificación XML adecuada (UTF-8) para caracteres internacionales.
- Incluya las fechas de creación y modificación en formato ISO 8601.
- Valide la estructura XML para evitar errores de análisis.
Archivos adjuntos.
Los archivos adjuntos en formato PDF proporcionan un método conveniente para incrustar archivos externos directamente dentro de un documento PDF, creando paquetes autocontenidos que incluyen todos los recursos necesarios. Estos archivos adjuntos se pueden asociar con todo el documento o vincular a páginas específicas, según sus necesidades. La mayoría de los visores de PDF modernos presentan estos archivos incrustados en un panel de archivos adjuntos dedicado, lo que facilita a los usuarios acceder, ver o guardar el contenido incluido. Esta función es particularmente valiosa para crear paquetes de documentos completos, como presentaciones que incluyen recursos complementarios o informes con archivos de datos adjuntos.
Estructura de archivos incrustados.
En esencia, un archivo incrustado consta de un objeto de flujo que contiene los datos reales del archivo, junto con una entrada de diccionario de flujo que especifica. /Type /EmbeddedFileEste enfoque sencillo permite almacenar cualquier tipo de archivo dentro de un PDF. Así es como se ve la estructura básica de un archivo incrustado:
|
1 2 3 4 5 6 |
8 0 obj < < Type EmbeddedFile Length 35>> stream This is a text file attachment... endstream endobj |
PDF admite dos enfoques distintos para referenciar archivos incrustados, cada uno para diferentes casos de uso: archivos adjuntos a nivel de documento, que son accesibles globalmente, y archivos adjuntos a nivel de página, que aparecen como elementos interactivos en páginas específicas.
Archivos adjuntos a nivel de documento
Para archivos adjuntos a nivel de documento, debe agregar una /EmbeddedFiles entrada al diccionario de nombres, que se accede a través de la /Names entrada en el catálogo del documento. Este enfoque hace que el archivo adjunto esté disponible globalmente en todo el PDF, independientemente de la página que esté viendo el usuario:
|
1 2 3 4 5 6 |
9 0 obj < < Names << EmbeddedFiles << Names [ (attachment.txt) << EF << F 8 0 R>> /F (attachment.txt) /Type /Filespec >> ] >> >> /Pages 1 0 R /Type /Catalog >> endobj |
Explicación de la estructura del código
- /Names – Contiene el diccionario de nombres para el documento.
- /EmbeddedFiles – Específicamente, maneja los nombres de archivos incrustados.
- (attachment.txt) – El nombre del archivo tal como lo ven los usuarios.
- /EF – Diccionario de archivos incrustados que contiene la referencia real al archivo.
- /F 8 0 R – Referencia al objeto de flujo de archivo incrustado.
- /Type /Filespec – Identifica esto como un diccionario de especificaciones de archivo.
Adjuntos a nivel de página.
Los adjuntos específicos de la página requieren un enfoque diferente utilizando anotaciones de adjuntos de archivo. Estos se agregan al /Annots array en el diccionario de la página de destino, creando un icono de adjunto visible con el que los usuarios pueden interactuar directamente en la página:
|
1 2 3 4 5 6 7 8 |
9 0 obj < < Type Page (Other dictionary entries as usual) Annots [ << FS << EF << F 8 0 R>> /F (attachment.txt) /Type /Filespec >> /Subtype /FileAttachment /Contents (attachment.txt) /Rect [ 18 796.88976378 45 823.88976378 ] >> ] >> endobj |
Propiedades de los adjuntos de la página.
- /FS – Diccionario de especificaciones de archivo (igual que /EF arriba).
- /Subtype /FileAttachment – Identifica esta anotación como un archivo adjunto.
- /Contents – Texto de la información que aparece al pasar el cursor sobre el icono del archivo adjunto.
- /Rect – Rectángulo que define la posición y el tamaño del icono del archivo adjunto en la página.
Casos de uso de archivos adjuntos.
📊 Archivos de datos.
Incorpore hojas de cálculo, bases de datos o archivos de datos sin procesar junto con informes y análisis.
🎨 Archivos fuente.
Incluya archivos de diseño originales, dibujos CAD o plantillas editables.
📹 Recursos multimedia.
Adjunte presentaciones en video, grabaciones de audio o contenido interactivo.
📋 Documentos de apoyo.
Incluya archivos PDF relacionados, contratos o materiales de referencia.
Anotaciones.

Las anotaciones PDF proporcionan una forma potente de agregar elementos interactivos y marcas visuales a los documentos sin alterar el contenido original de la página. Estos elementos superpuestos mejoran la experiencia de lectura al permitir a los usuarios resaltar texto, agregar comentarios o crear enlaces clicables. Entre los tipos de anotaciones más útiles se encuentran los hipervínculos, que permiten una navegación fluida entre diferentes secciones de un documento o a recursos externos.
Estructura de las anotaciones.
Si bien los diferentes tipos de anotaciones tienen diversos propósitos, todos siguen una estructura fundamental consistente, con propiedades específicas del tipo que se agregan según sea necesario. Las páginas PDF pueden contener múltiples anotaciones, que se organizan en una matriz referenciada por la entrada /Annots en el diccionario de cada página. Cada anotación se implementa como su propio objeto de diccionario con propiedades específicas.
Tabla de estructura del diccionario de anotaciones.
* indica una entrada obligatoria.
| Key | Value Type | Value |
|---|---|---|
| /Type | name | When specified, this value must be set to /Annot to properly identify the dictionary type. |
| /Subtype* | name | Specifies the specific annotation category (e.g., Link, Text, Highlight). |
| /Rect* | rectangle | Defines the annotation’s position and dimensions using standard PDF coordinate units. |
| /Contents | text string | Contains the annotation’s text content or provides an alternative descriptive label for accessibility purposes. |
Ejemplo fundamental del diccionario de anotaciones:
|
1 2 3 |
12 0 obj < < Type Annot Subtype Link Rect [100 200 300 250] Border [0 0 1] C [0.0 0.0 1.0] Dest [5 0 R XYZ null null null]>> endobj |
Tipos de anotaciones comunes.
🔗 Anotaciones de enlace.
Crea áreas clicables que navegan a destinos dentro del documento o a recursos externos.
- /Subtype /Link – Identifica una anotación de enlace.
- /Dest – Matriz de destino o destino con nombre.
- /A – Diccionario de acción para comportamientos más complejos.
📝 Anotaciones de texto.
Muestra notas y comentarios emergentes al hacer clic.
- /Subtype /Text – Identifica la anotación como texto.
- /Contents – El contenido de texto de la anotación.
- /Open – Indica si la anotación está inicialmente abierta.
🖍️ Anotaciones de marcado.
Resaltar, subrayar o tachar contenido de texto.
- /Subtype /Highlight Resaltado de texto
- /Subtype /Underline Subrayado de texto
- /Subtype /StrikeOut Tachado de texto
Acciones avanzadas para enlaces.
Las anotaciones de enlace pueden realizar diversas acciones más allá de la simple navegación:
|
1 2 3 |
13 0 obj < < Type Annot Subtype Link Rect [50 50 200 100] A << Type Action S URI URI (https: www.example.com)>> >> endobj |
Tipos de acción
- /S /GoTo – Navegar a un destino dentro del documento
- /S /GoToR – Navegar a un destino en otro documento
- /S /URI – Abrir una URL web
- /S /Launch – Launch an external application
- /S /JavaScript – Execute JavaScript code
Apariencia de las anotaciones
El estilo visual personalizado para las anotaciones se logra a través de flujos de apariencia, lo que permite un control preciso de cómo se muestran las anotaciones a los usuarios:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
14 0 obj < < Type Annot Subtype Square Rect [100 100 200 150] C [1.0 0.0 0.0] BS << W 2 S S>> /AP < < N 15 0 R>> >> endobj 15 0 obj < < Type XObject Subtype Form BBox [0 0 100 50] Length 85>> stream q 1.0 0.0 0.0 RG 2 w 10 10 80 30 re S Q endstream endobj |
Directrices prácticas de implementación
Integración de la estructura del documento
Una implementación exitosa requiere comprender cómo estos elementos funcionan juntos dentro de la arquitectura general del documento PDF.
|
1 2 3 4 |
1 0 obj < < Type Catalog Pages 2 0 R Outlines 3 0 R Names << EmbeddedFiles 4 0 R>> /Metadata 5 0 R >> endobj |
✅ Lista de verificación de implementación
- Configuración del catálogo de documentos – Asegúrese de que haya referencias correctas a los esquemas, nombres y metadatos.
- Numeración de objetos – Mantenga una numeración de objetos y referencias cruzadas consistentes.
- Codificación de flujos – Aplique los filtros y la codificación adecuados para los flujos.
- Validación – Verificar la estructura del PDF con herramientas de validación.
- Pruebas de compatibilidad – Realizar pruebas en diferentes visores y versiones de PDF.
Problemas comunes y soluciones.
❌ Los marcadores no se muestran.
Solución: Verificar que el catálogo de documentos incluya una /Outlines entrada y que la jerarquía del esquema esté estructurada correctamente con relaciones padre-hijo.
❌ Los metadatos no se reconocen.
Solución: Asegúrese de que el flujo de metadatos XML esté correctamente formateado, utilice los espacios de nombres correctos y esté referenciado en el catálogo de documentos. /Type /Metadata y /Subtype /XML.
❌ Adjuntos no accesibles.
Solución: Verifique que los archivos incrustados estén correctamente referenciados o bien en el diccionario de nombres a nivel de documento o en el diccionario de anotaciones a nivel de página, y que los diccionarios de especificaciones de archivos estén estructurados correctamente.
Conclusión.
Dominar los metadatos y la implementación de marcadores PDF es crucial para desarrollar documentos de calidad profesional que ofrezcan una experiencia de usuario y funcionalidad superiores. Estas potentes funciones proporcionan:
- Navegación mejorada. – A través de marcadores y destinos bien estructurados.
- Metadatos enriquecidos. – Permitiendo una mejor gestión y búsqueda de documentos.
- Integración de archivos. – Agrupación de recursos relacionados dentro de los documentos.
- Elementos interactivos. – Creación de experiencias de usuario atractivas mediante anotaciones.
Al implementar correctamente estas funciones, puede crear documentos PDF que van más allá de un simple texto y gráficos para convertirse en recursos completos e interactivos que sirven eficazmente tanto a los lectores humanos como a los sistemas automatizados.
🚀 Próximos pasos.
- Practique la implementación de estas estructuras en su flujo de trabajo de creación de PDF.
- Experimente con diferentes tipos de anotaciones y jerarquías de marcadores.
- Pruebe sus implementaciones en varios visores de PDF.
- Explore funciones avanzadas de PDF, basándose en estas bases.