Understanding PDF XML Metadata and Bookmarks: A Technical Guide
Key Topics Covered
📍 Destinations
Precise location markers that define specific positions within PDF documents. These enable accurate navigation for bookmarks and hyperlinks, while document outlines provide hierarchical table-of-contents functionality.
📄 XML Metadata
Structured XML streams that provide comprehensive document metadata using standardized XMP formats, extending beyond basic document properties to include rich descriptive information.
📎 File Attachments
Complete file embedding capability that packages external resources directly within PDF documents, creating self-contained document bundles similar to email attachments.
📝 Annotations
Interactive overlay elements that add text, graphics, and clickable functionality to PDF pages without modifying the underlying content. Includes hyperlinks for seamless document navigation and various markup tools for enhanced reader interaction.
Bookmarks and Destinations

Document navigation relies on hierarchical bookmark structures, technically known as the document outline. This tree-organized system presents clickable entries—commonly chapter titles, section headers, and subsection names—that enable readers to jump quickly to specific parts of the document. Each bookmark entry combines display text with destination information that specifies exactly where the link should navigate.
Understanding Destinations
PDF destinations serve as precise location markers within a document, specifying which page to display, where on that page to position the view, and what zoom level to apply. You can create destinations in two ways: define them directly inline (which we’ll use in our examples for clarity) or reference them by name through a document-wide naming system. Most PDF readers present bookmarks in a navigation panel alongside the main document content.
Each destination uses an array structure where the specific elements vary based on the viewing behavior you want to achieve. Here are the main destination patterns available:
Destination Types Table
Note: “page” represents an indirect reference to a page object. By default, these destinations work with the page’s crop box boundaries, falling back to the media box when no crop box is defined.
| Array | Description |
|---|---|
| [page /Fit] | Scales the page to fit completely within the viewer window, adjusting both width and height proportionally. |
| [page /FitH top] | Positions the specified top coordinate at the window’s top edge while scaling horizontally to fit the full page width. |
| [page /FitV left] | Aligns the specified left coordinate with the window’s left edge while scaling vertically to fit the full page height. |
| [page /XYZ left top zoom] | Positions the coordinates (left, top) at the window’s upper-left corner and applies the specified zoom factor. Null values preserve current settings for those parameters. |
| [page /FitR left bottom right top] | Zooms and positions the view to display the rectangular area defined by the left, bottom, right, and top coordinates. |
| [page /FitB] | Similar to /Fit, but scales based on the actual content boundaries instead of the defined crop box area. |
| [page /FitBH top] | Functions like /FitH but uses the content bounding box instead of the crop box for horizontal scaling calculations. |
| [page /FitBV left] | Operates like /FitV but calculates vertical scaling based on the content bounding box rather than the crop box boundaries. |
Document Outline Structure
Document outlines create a hierarchical navigation structure that functions as an interactive table of contents for PDF viewers. This tree-like organization helps users quickly navigate through complex documents by providing a clear structural overview. The system relies on two fundamental object types:
- Outline dictionary – The root of the outline hierarchy
- Outline item dictionaries – Individual entries in the outline
Outline Dictionary Structure Table
| Key | Value Type | Value |
|---|---|---|
| /Type | name | If present, must be /Outlines. |
| /First | indirect reference to dictionary | References the initial top-level outline entry in the document hierarchy. This field is mandatory when outline entries exist. |
| /Last | indirect reference to dictionary | References the final top-level outline entry in the document hierarchy. This field is mandatory when outline entries exist. |
| /Count | integer | Specifies how many outline entries are currently expanded across the entire outline tree. Can be omitted when no entries are in an open state. |
Outline Item Implementation
Every outline item consists of a dictionary that specifies its display title, target destination, and relationships to other items in the hierarchy.
Let’s examine how a simple document outline is structured in PDF syntax:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
8 0 obj <</Type/Outlines/Count 4/First 9 0 R/Last 9 0 R>> endobj 9 0 obj <</Title(Chapter 1: Experiment A)/Count 3/Parent 8 0 R/First 12 0 R/Last 18 0 R>> endobj 12 0 obj <</Title(1: Introduction)/Count 0/Parent 9 0 R/Next 15 0 R>> endobj 15 0 obj <</Title(2: Methodology)/Count 0/Parent 9 0 R/Prev 12 0 R/Next 18 0 R>> endobj 18 0 obj <</Title(3: Result verification)/Count 0/Parent 9 0 R/Prev 15 0 R/>> endobj |
Outline Item Dictionary Structure Table
* denotes a required entry
| Key | Value Type | Value |
|---|---|---|
| /Title* | text string | Text to be displayed for this entry. |
| /Parent* | indirect reference to dictionary | References this item’s parent within the outline hierarchy, which can be either another outline item or the root outline dictionary. |
| /Prev | indirect reference to dictionary | References the preceding sibling item at the same hierarchical level, when applicable. |
| /Next | indirect reference to dictionary | References the following sibling item at the same hierarchical level, when applicable. |
| /First | indirect reference to dictionary | References the initial child item under this entry, when child items exist. |
| /Last | indirect reference to dictionary | References the final child item under this entry, when child items exist. |
| /Count | integer | When the entry is expanded, indicates the count of visible descendant entries. When collapsed, stores a negative value representing the total number of hidden descendants that would become visible upon expansion. |
| /Dest | name, string or array | The destination. Arrays are destinations, names are references to entries in the /Dests entry in the document catalog, strings are references to entries in the /Dests entry in the document’s name dictionary. |
XML Metadata
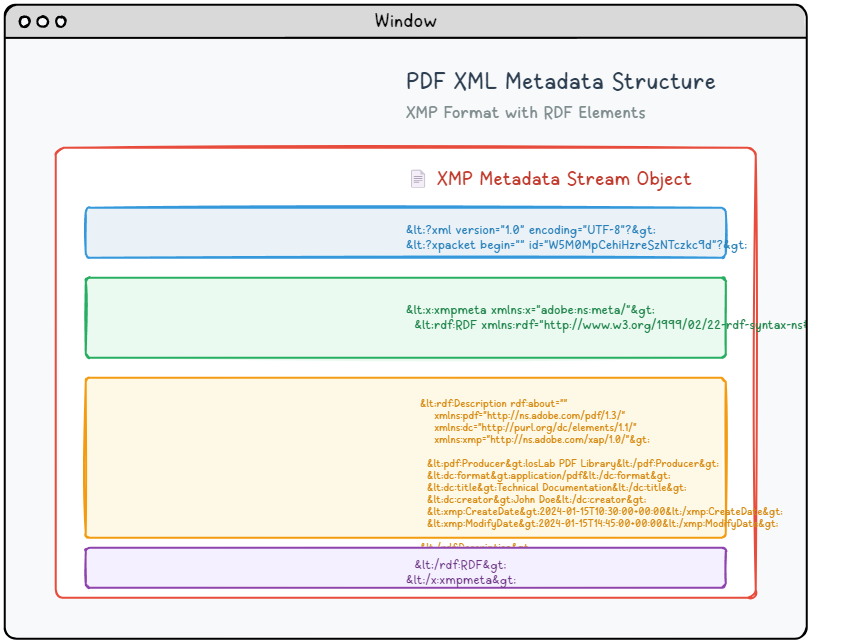
Modern PDF documents can incorporate sophisticated XML-based metadata streams that offer far more detailed and structured information than traditional document properties. This advanced metadata system leverages Adobe’s XMP (Extensible Metadata Platform) specification to provide standardized, machine-readable document descriptions that enhance searchability, organization, and automated processing capabilities.
XMP Metadata Structure
XMP metadata is packaged as an XML document that utilizes RDF (Resource Description Framework) syntax to organize and describe document properties in a standardized format. This metadata content is embedded within a dedicated stream object that includes proper type identification for PDF processors:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
6 0 obj <</Length 1235/Type/Metadata/Subtype/XML>>stream <?xpacket begin="锘xBF" id="W5M0MpCehiHzreSzNTczkc9d"?> <x:xmpmeta xmlns:x="adobe:ns:meta/" x:xmptk="Adobe XMP Core 5.2-c001 63.139439, 2010/09/27-13:37:26" ><rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" ><rdf:Description rdf:about="" xmlns:pdf="http://ns.adobe.com/pdf/1.3/" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:xmp="http://ns.adobe.com/xap/1.0/" ><pdf:Producer>losLab PDF Library</pdf:Producer> <dc:creator>losLab.com</dc:creator> <dc:title>Delphi PDF SDKs</dc:title> <xmp:CreateDate>2025-06-29T10:46:27+08:00</xmp:CreateDate> <xmp:ModifyDate>2025-06-29T10:58:57+08:00</xmp:ModifyDate> <xmp:MetadataDate>2025-06-29T10:46:27+08:00</xmp:MetadataDate> <dc:description>Delphi Development Library for PDF creation & editing</dc:description> <xmp:CreatorTool>HotPDF Component</xmp:CreatorTool> <dc:subject>PDF Developer Library for RAD Studio></dc:subject> <pdf:Keywords>Delphi, PDF SDK, PDF Component</pdf:Keywords> </rdf:Description>Robust Delphi PDF development library</rdf:RDF> </x:xmpmeta> <?xpacket end="w"?> endstream endobj |
Standard Metadata Schemas
The XMP framework organizes metadata through well-established schema namespaces, each serving specific information categories:
📋 Dublin Core (dc:)
Basic bibliographic information
- dc:title – Document title
- dc:creator – Document author(s)
- dc:subject – Document subject/keywords
- dc:description – Document description
- dc:format – MIME type
🏷️ XMP Basic (xmp:)
Core XMP properties
- xmp:CreateDate – Creation date
- xmp:ModifyDate – Modification date
- xmp:CreatorTool – Creating application
- xmp:MetadataDate – Metadata modification date
📄 PDF Schema (pdf:)
PDF-specific properties
- pdf:Producer – PDF producer
- pdf:Keywords – Document keywords
- pdf:PDFVersion – PDF version
Integration with Document Catalog
The XML metadata stream is referenced from the document catalog:
|
1 2 3 |
1 0 obj < < Type Catalog Pages 2 0 R Metadata 10 0 R Outlines 1 0 R>> endobj |
🎯 Best Practices for XML Metadata
- Always include both document information dictionary and XMP metadata for maximum compatibility
- Ensure metadata values are consistent between both locations
- Use proper XML encoding (UTF-8) for international characters
- Include creation and modification dates in ISO 8601 format
- Validate XML structure to prevent parsing errors
File Attachments
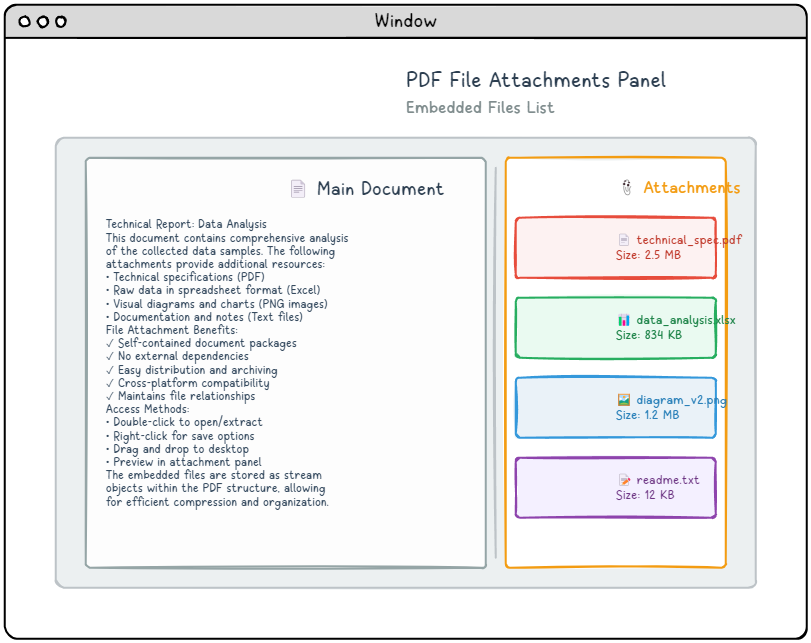
PDF file attachments provide a convenient method for embedding external files directly within a PDF document, creating self-contained packages that include all necessary resources. These attachments can be associated with the entire document or linked to specific pages, depending on your needs. Most modern PDF viewers present these embedded files in a dedicated attachments panel, making it easy for users to access, view, or save the included content. This feature is particularly valuable for creating comprehensive document packages, such as presentations that include supplementary resources or reports with accompanying data files.
Embedded File Structure
At its core, an embedded file consists of a stream object that contains the actual file data, along with a stream dictionary entry specifying /Type /EmbeddedFile. This straightforward approach allows any type of file to be stored within a PDF. Here’s how the basic embedded file structure looks:
|
1 2 3 4 5 6 |
8 0 obj < < Type EmbeddedFile Length 35>> stream This is a text file attachment... endstream endobj |
PDF supports two distinct approaches for referencing embedded files, each serving different use cases: document-level attachments that are globally accessible, and page-level attachments that appear as interactive elements on specific pages.
Document-Level Attachments
For document-wide attachments, you’ll need to add an /EmbeddedFiles entry to the name dictionary, which is accessed through the /Names entry in the document catalog. This approach makes the attachment globally available throughout the entire PDF, regardless of which page the user is currently viewing:
|
1 2 3 4 5 6 |
9 0 obj < < Names << EmbeddedFiles << Names [ (attachment.txt) << EF << F 8 0 R>> /F (attachment.txt) /Type /Filespec >> ] >> >> /Pages 1 0 R /Type /Catalog >> endobj |
Code Structure Explanation
- /Names – Contains the name dictionary for the document
- /EmbeddedFiles – Specifically handles embedded file names
- (attachment.txt) – The filename as it appears to users
- /EF – Embedded file dictionary containing the actual file reference
- /F 8 0 R – Reference to the embedded file stream object
- /Type /Filespec – Identifies this as a file specification dictionary
Page-Level Attachments
Page-specific attachments require a different approach using file attachment annotations. These are added to the /Annots array in the target page’s dictionary, creating a visible attachment icon that users can interact with directly on the page:
|
1 2 3 4 5 6 7 8 |
9 0 obj < < Type Page (Other dictionary entries as usual) Annots [ << FS << EF << F 8 0 R>> /F (attachment.txt) /Type /Filespec >> /Subtype /FileAttachment /Contents (attachment.txt) /Rect [ 18 796.88976378 45 823.88976378 ] >> ] >> endobj |
Page Attachment Properties
- /FS – File specification dictionary (same as /EF above)
- /Subtype /FileAttachment – Identifies this annotation as a file attachment
- /Contents – Tooltip text that appears when hovering over the attachment icon
- /Rect – Rectangle defining the position and size of the attachment icon on the page
Attachment Use Cases
📊 Data Files
Embed spreadsheets, databases, or raw data files alongside reports and analyzes
🎨 Source Files
Include original design files, CAD drawings, or editable templates
📹 Media Resources
Attach video presentations, audio recordings, or interactive content
📋 Supporting Documents
Bundle related PDFs, contracts, or reference materials
Annotations

PDF annotations provide a powerful way to add interactive elements and visual markup to documents without altering the original page content. These overlay elements enhance the reading experience by allowing users to highlight text, add comments, or create clickable links. Among the most useful annotation types are hyperlinks, which enable seamless navigation between different sections of a document or to external resources.
Annotation Structure
While different annotation types serve various purposes, they all follow a consistent foundational structure with type-specific properties added as needed. PDF pages can contain multiple annotations, which are organized in an array referenced by the /Annots entry in each page’s dictionary. Every annotation is implemented as its own dictionary object with specific properties.
Annotation Dictionary Structure Table
* denotes a required entry
| Key | Value Type | Value |
|---|---|---|
| /Type | name | When specified, this value must be set to /Annot to properly identify the dictionary type. |
| /Subtype* | name | Specifies the specific annotation category (e.g., Link, Text, Highlight). |
| /Rect* | rectangle | Defines the annotation’s position and dimensions using standard PDF coordinate units. |
| /Contents | text string | Contains the annotation’s text content or provides an alternative descriptive label for accessibility purposes. |
The fundamental annotation dictionary example:
|
1 2 3 |
12 0 obj < < Type Annot Subtype Link Rect [100 200 300 250] Border [0 0 1] C [0.0 0.0 1.0] Dest [5 0 R XYZ null null null]>> endobj |
Common Annotation Types
🔗 Link Annotations
Create clickable areas that navigate to destinations within the document or external resources.
- /Subtype /Link – Identifies as a link annotation
- /Dest – Destination array or named destination
- /A – Action dictionary for more complex behaviors
📝 Text Annotations
Display pop-up notes and comments that appear when clicked.
- /Subtype /Text – Identifies as a text annotation
- /Contents – The text content of the annotation
- /Open – Whether the annotation is initially open
🖍️ Markup Annotations
Highlight, underline, or strike through text content.
- /Subtype /Highlight – Text highlighting
- /Subtype /Underline – Text underlining
- /Subtype /StrikeOut – Text strikethrough
Advanced Link Actions
Link annotations can perform various actions beyond simple navigation:
|
1 2 3 |
13 0 obj < < Type Annot Subtype Link Rect [50 50 200 100] A << Type Action S URI URI (https: www.example.com)>> >> endobj |
Action Types
- /S /GoTo – Navigate to a destination within the document
- /S /GoToR – Navigate to a destination in another document
- /S /URI – Open a web URL
- /S /Launch – Launch an external application
- /S /JavaScript – Execute JavaScript code
Annotation Appearance
Custom visual styling for annotations is achieved through appearance streams, enabling precise control over how annotations display to users:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
14 0 obj < < Type Annot Subtype Square Rect [100 100 200 150] C [1.0 0.0 0.0] BS << W 2 S S>> /AP < < N 15 0 R>> >> endobj 15 0 obj < < Type XObject Subtype Form BBox [0 0 100 50] Length 85>> stream q 1.0 0.0 0.0 RG 2 w 10 10 80 30 re S Q endstream endobj |
Practical Implementation Guidelines
Document Structure Integration
Successful implementation requires understanding how these elements work together within the broader PDF document architecture:
|
1 2 3 4 |
1 0 obj < < Type Catalog Pages 2 0 R Outlines 3 0 R Names << EmbeddedFiles 4 0 R>> /Metadata 5 0 R >> endobj |
✅ Implementation Checklist
- Document Catalog Setup – Ensure proper references to outlines, names, and metadata
- Object Numbering – Maintain consistent object numbering and cross-references
- Stream Encoding – Apply appropriate filters and encoding for streams
- Validation – Verify PDF structure with validation tools
- Compatibility Testing – Test across different PDF viewers and versions
Common Issues and Solutions
❌ Bookmarks Not Displaying
Solution: Verify that the document catalog includes an /Outlines entry and that the outline hierarchy is properly structured with correct parent-child relationships.
❌ Metadata Not Recognized
Solution: Ensure the XML metadata stream is properly formatted, uses correct namespaces, and is referenced in the document catalog with /Type /Metadata and /Subtype /XML.
❌ Attachments Not Accessible
Solution: Check that embedded files are properly referenced in either the document-level names dictionary or page-level annotations dictionary, and that file specification dictionaries are correctly structured.
Conclusion
Mastering PDF metadata and bookmark implementation is crucial for developing professional-grade documents that offer superior user experience and functionality. These powerful features provide:
- Enhanced Navigation – Through well-structured bookmarks and destinations
- Rich Metadata – Enabling better document management and searchability
- File Integration – Bundling related resources within documents
- Interactive Elements – Creating engaging user experiences with annotations
By implementing these features correctly, you can create PDF documents that go beyond simple text and graphics to become comprehensive, interactive resources that serve both human readers and automated systems effectively.
🚀 Next Steps
- Practice implementing these structures in your PDF creation workflow
- Experiment with different annotation types and bookmark hierarchies
- Test your implementations across multiple PDF viewers
- Explore advanced PDF features building on these foundations