Beherrschung von PDF-Text und -Schriftarten: Ein Leitfaden für Entwickler.
PDF-Dokumente haben die Art und Weise, wie wir formatierten Text über verschiedene Plattformen und Geräte austauschen und erhalten, revolutioniert. Hinter der glatten Oberfläche jedes PDF-Dokuments verbirgt sich jedoch ein ausgeklügeltes Textrendering-System, das fortschrittliche Typografiekonzepte mit präzisen mathematischen Operationen kombiniert. Das Verständnis, wie PDF Text und Schriftarten verarbeitet, ist entscheidend für Entwickler, die mit Dokumentgenerierung, Textextraktion oder PDF-Manipulation arbeiten.
Dieser umfassende Leitfaden führt Sie tief in die Welt des PDF-Textrenderings ein und untersucht alles, von grundlegenden Zeichenabständen bis hin zu komplexen Schriftart-Einbettungstechniken, Zeichensatzsystemen und den komplexen Herausforderungen der Textextraktion. Egal, ob Sie ein erfahrener Entwickler sind oder gerade erst mit PDF-Technologien beginnen, Sie erhalten wertvolle Einblicke, wie diese allgegenwärtigen Dokumente tatsächlich funktionieren.
Die Philosophie hinter dem PDF-Textrendering.
Als Adobe das Portable Document Format (PDF) entwickelte, standen sie vor einer grundlegenden Designherausforderung, die die Art und Weise prägen würde, wie Milliarden von Dokumenten heute dargestellt werden. Die Frage war: Wie kann man Flexibilität mit Konsistenz in einer Welt in Einklang bringen, in der Dokumente auf sehr unterschiedlichen Systemen identisch aussehen müssen, von hochauflösenden Druckern bis hin zu mobilen Geräten?
Sie hätten einen von zwei extremen Ansätzen wählen können:
- Dynamischer Layout-Ansatz: Speichern von Klartext mit Layout-Anweisungen, ähnlich wie bei Desktop-Publishing-Software, wodurch ein Echtzeit-Textfluss und Formatierungsberechnungen während der Ansicht möglich sind.
- Reine Vektorgrafik-Methode: Konvertiert alle Texte während der Erstellung in Vektorgrafiken, wodurch eine perfekte visuelle Konsistenz gewährleistet wird, aber die semantische Bedeutung und textbasierte Funktionalität vollständig verloren gehen.
Stattdessen verwendet PDF, was wir als "Goldilocks-Ansatz" bezeichnen könnten – einen ausgeklügelten Mittelweg, der das Beste aus beiden Welten vereint und gleichzeitig deren jeweilige Nachteile vermeidet. Dieses hybride System behält die grundlegenden Konzepte von Schriftarten und Zeichen bei, berechnet aber die meisten Layout-Entscheidungen während der Dokumenterstellung im Voraus.
Strategische Vorteile des PDF-Ansatzes
Vollständige Layoutkontrolle und Vorhersagbarkeit
Umfangreiche Formatierungsentscheidungen wie Absatzumbrüche, Zeilenabstände, Spaltenbreiten und Seitenlayout werden während der PDF-Erstellung von der Erstellungsanwendung vorgenommen. Das bedeutet, dass Ihr Dokument identisch aussieht, egal ob es auf einem Smartphone in Tokio angezeigt wird, auf einem 4K-Monitor in Silicon Valley oder auf einem Laserdrucker in New York ausgedruckt wird. Die Layoutintegrität bleibt in allen Anzeigeszenarien erhalten, wodurch die unvorhersehbaren Reflow-Probleme, die andere Dokumentformate plagen, vermieden werden.
Vorhersagbare Textformatierung im Detail
Kleine Textoperationen wie Zeichenpositionierung, Wortabstand und Schriftgrößenanpassung werden durch eine umfassende Reihe von klar definierten Operatoren standardisiert. Dies ermöglicht eine feingranulare Kontrolle über die Typografie bei gleichzeitiger Wahrung eines vorhersagbaren Verhaltens in verschiedenen PDF-Anzeigeprogrammen und -Verarbeitungsprogrammen. Das System unterstützt ausgefeilte typografische Funktionen wie Kerning, Ligaturen und kontextuelle Zeichenersetzung und gewährleistet gleichzeitig konsistente Ergebnisse.
Effiziente Speicherung und Ressourcenverwaltung.
Durch die Behandlung von Schriftarten als Bibliotheken wiederverwendbarer Zeichenformen bleiben PDF-Dateien auch bei textlastigen Dokumenten relativ kompakt. Anstatt die Vektorgrafik jedes einzelnen Buchstabens einzeln zu speichern, verweisen Dokumente auf gemeinsam genutzte Schriftartdefinitionen, die über mehrere Seiten und sogar mehrere Dokumente hinweg wiederverwendet werden können. Dieser Ansatz reduziert die Dateigröße erheblich und ermöglicht gleichzeitig ausgefeilte Schriftart-Subset- und -Einbettungsstrategien.
Semantische Integrität für Barrierefreiheit.
Im Gegensatz zu rein grafischen Ansätzen bewahrt PDF die entscheidende Verbindung zwischen visuellen Glyphen und ihren zugrunde liegenden Zeichencodes. Diese Bewahrung ermöglicht wichtige Funktionen wie Textsuche, Kopier- und Einfügeoperationen, Barrierefreiheit für Bildschirmlesegeräte und automatisierte Inhaltsanalyse. Das Format unterstützt Unicode-Zuordnungen, alternative Textbeschreibungen und strukturierte Informationen, die Dokumente für assistive Technologien zugänglich machen.
Umfassendes PDF-Textstatus-System.
Das Textrendering-System von PDF arbeitet über eine ausgefeilte Sammlung von Statusparametern, die zusammenwirken, um jeden Aspekt des Erscheinungsbilds von Text auf der Seite zu steuern. Betrachten Sie diese Parameter als eine umfassende Steuerung, die nicht nur das grundlegende Erscheinungsbild, sondern auch erweiterte typografische Funktionen, Positionsberechnungen und Rendering-Optimierungen steuert.
Das vollständige Textstatus-Parametersystem umfasst:
| Parameter | Operator | Description | Default Value |
|---|---|---|---|
| Character Spacing | Tc | Additional space between characters | 0 |
| Word Spacing | Tw | Additional space between words | 0 |
| Horizontal Scaling | Tz | Horizontal scaling percentage | 100 |
| Leading | TL | Line spacing for T* operator | 0 |
| Font and Size | Tf | Font selection and scaling | N/A |
| Text Rendering Mode | Tr | Fill, stroke, or path mode | 0 (Fill) |
| Text Rise | Ts | Vertical text displacement | 0 |
Zeichenabstand (Tc-Operator) – Präzise Kontrolle der Typografie.
Der Parameter für die Zeichenabstände ermöglicht eine feingranulare Steuerung des zusätzlichen Leerraums, der zwischen jedem Zeichen in einer Textzeichenkette eingefügt wird. Dieser Parameter wird in Textraum-Einheiten gemessen, die typischerweise 1/1000 der Schriftgröße entsprechen, was extrem präzise Anpassungen ermöglicht.
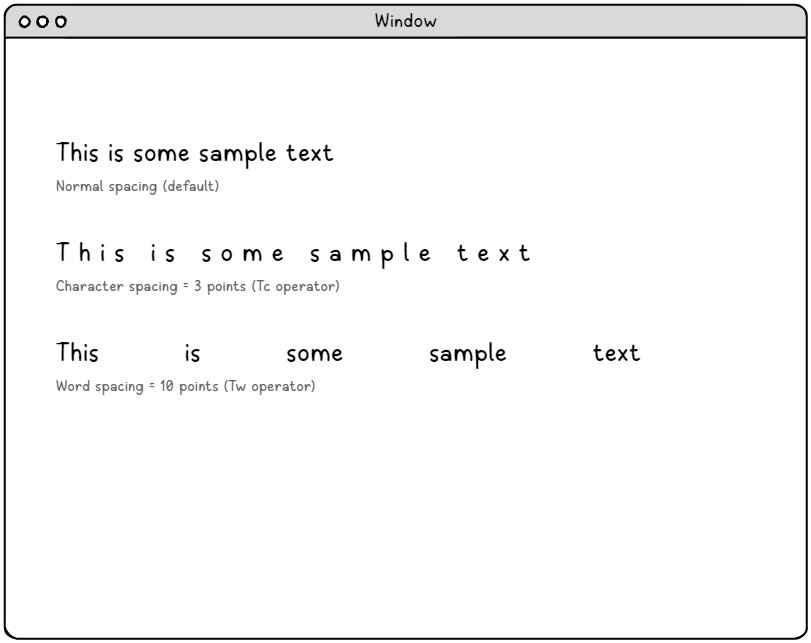
Anwendungsbereiche für Zeichenabstände sind:
- Typografische Verbesserung: Hervorhebung oder Verbesserung der Lesbarkeit in Überschriften und Fließtext.
- Unterstützung für automatische Textausrichtung: Feinabstimmung der Zeilenlängen in Textausrichtungen.
- Markenkonformität: Anpassung an spezifische typografische Stile, die von Unternehmensrichtlinien gefordert werden.
- Barrierefreiheit: Verbesserung der Lesbarkeit für Nutzer mit Legasthenie oder Sehbehinderungen.
|
1 2 3 4 5 6 7 8 9 10 11 |
BT /F0 24 Tf 1 0 0 1 50 700 Tm (Normal text spacing) Tj 0 -30 Td 3 Tc (Character spacing = 3 points) Tj 0 -30 Td -1 Tc (Tight character spacing = -1 point) Tj ET |
Wortabstand (Tw-Operator) – Intelligente Leerzeichenverwaltung.
Der Tw-Operator zielt speziell auf das Leerzeichenzeichen (ASCII 32) innerhalb von Textstrings ab und bietet eine gezielte Kontrolle über den Wortabstand, ohne andere Leerzeichen zu beeinflussen. Diese präzise Steuerung ist von unschätzbarem Wert für Textausrichtungsalgorithmen und die Erstellung professionell aussehender Dokumentlayouts.
Der Tw-Operator demonstriert den ausgeklügelten Ansatz von PDF zur Typografie, indem er erkennt, dass verschiedene Arten von Leerzeichen unterschiedliche Zwecke erfüllen. Während die Zeichenabstände alle Zeichen gleichmäßig beeinflussen, wirken Wortabstände nur auf tatsächliche Wortgrenzen, was Designern eine präzise Kontrolle über Textfluss und Lesbarkeit ermöglicht.
|
1 2 3 4 5 6 7 8 9 10 11 |
BT /F0 24 Tf 1 0 0 1 50 600 Tm (Normal word spacing) Tj 0 -30 Td 10 Tw (Extended word spacing improves readability) Tj 0 -30 Td -2 Tw (Compressed word spacing saves space) Tj ET |
Horizontale Skalierung (Tz-Operator) – Dimensionale Typografie-Steuerung.
Die horizontale Skalierung ermöglicht es Ihnen, Text horizontal zu dehnen oder zu komprimieren, ohne seine Höhe zu beeinflussen, und wird als Prozentsatz angegeben, wobei 100 % die normale Breite darstellt. Dieser Parameter ermöglicht responsive Typografie-Anpassungen und spezielle typografische Effekte, die mit herkömmlichen Setzmethoden nicht möglich wären.
Anwendungen der horizontalen Skalierung:
- Platzbeschränkte Layouts: Anpassen von Text an vorgegebene Spaltenbreiten oder Designelemente.
- Stilistische Effekte: Erstellen von komprimiertem oder erweitertem Text für Überschriften und Hervorhebungen.
- Schriftartsimulation: Annäherung an komprimierte oder erweiterte Schriftvarianten, wenn diese nicht verfügbar sind.
- Responsives Design: Anpassen von Text an unterschiedliche Seitengrößen unter Beibehaltung der Lesbarkeit.
Allerdings sollte horizontale Skalierung nur sparsam eingesetzt werden. Übermäßige Skalierung kann die Lesbarkeit beeinträchtigen und zu unnatürlich wirkendem Text führen, der das Leseerlebnis stört. Best Practices empfehlen, die Skalierung für Fließtext auf den Bereich von 85-115% zu beschränken, wobei größere Skalierungen für spezielle Darstellungszwecke reserviert sind.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
BT /F0 24 Tf 1 0 0 1 50 500 Tm 100 Tz (Normal horizontal scaling - 100%) Tj 0 -30 Td 80 Tz (Condensed text - 80% scaling) Tj 0 -30 Td 120 Tz (Extended text - 120% scaling) Tj ET |
Zeilenabstand (TL Operator) – Vertikaler Rhythmus und Lesbarkeit
Zeilenabstand, ausgesprochen "ledding", leitet sich von der traditionellen Typografie ab, bei der dünne Bleistreifen zwischen Zeilen von Text eingefügt wurden. In PDF bestimmt der Zeilenabstand den vertikalen Abstand zwischen den Textgrundlinien und steuert, wie stark sich die Textposition bei Verwendung des Operators T* (zur nächsten Zeile) ändert.
Ein korrekter Zeilenabstand ist entscheidend für die Schaffung eines lesbaren vertikalen Rhythmus im Text. Das Verhältnis zwischen Schriftgröße und Zeilenabstand hat einen erheblichen Einfluss auf die Lesbarkeit, die Lesegeschwindigkeit und die Gesamtästhetik des Dokuments. Typografieexperten empfehlen typischerweise Zeilenabstände zwischen 120% und 145% der Schriftgröße für optimale Lesbarkeit.
Überlegungen zum Zeilenabstand:
- Verhältnis zur Schriftgröße: Größere Schriftarten erfordern in der Regel proportional mehr Zeilenabstand.
- Auswirkungen auf die Zeilenlänge: Längere Zeilen profitieren von einem größeren Zeilenabstand, um Lesern zu helfen, zum Anfang der nächsten Zeile zurückzukehren.
- Schriftmerkmale: Schriften mit großer x-Höhe oder dekorativen Elementen benötigen möglicherweise einen angepassten Zeilenabstand.
- Lesekontext: Unterschiedliche Arten von Inhalten (Textkörper, Bildunterschriften, Überschriften) haben unterschiedliche Anforderungen an den Zeilenabstand.
|
1 2 3 4 5 6 7 8 9 10 |
BT /F0 18 Tf 18 TL 1 0 0 1 50 400 Tm (This text uses 18pt leading) Tj T* (which matches the font size) Tj T* 24 TL (This text uses 24pt leading) Tj T* (providing more generous spacing) Tj T* ET |
Textversatz (Ts Operator) – Präzision der vertikalen Positionierung.
Der Textversatz bietet präzise vertikale Anpassungsmöglichkeiten, mit denen Sie Text um eine bestimmte Höhe über oder unter der Grundlinie positionieren können, ohne den Gesamttextfluss zu beeinflussen. Dieser Parameter ist unerlässlich für die Erstellung professioneller Typografieelemente, die eine präzise vertikale Positionierung erfordern.

Anwendungen für Textversatz:
- Mathematische Notation: Positionierung von Exponenten, Subskripten und mathematischen Symbolen.
- Wissenschaftliche Inhalte: Chemische Formeln, Molekülstrukturen und wissenschaftliche Anmerkungen.
- Redaktionelle Elemente: Fußnotenzeichen, Markenzeichen und Copyright-Hinweise.
- Mehrsprachige Typografie: Anpassung der Grundlinienpositionen für verschiedene Schriftsysteme.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
BT /F0 36 Tf 1 0 0 1 140 290 Tm (H) Tj -8 Ts /F0 24 Tf (2) Tj 0 Ts /F0 36 Tf (O represents water with O) Tj 8 Ts /F0 24 Tf (2) Tj 0 Ts /F0 36 Tf ( as oxygen) Tj ET |
Erweiterte Texttransformationen und Matrixoperationen.
Eine der ausgefeiltesten Funktionen von PDF ist die Fähigkeit, Texttransformationen nahtlos mit Grafiktransformationen über ein duales Matrixsystem zu kombinieren. Diese Fähigkeit ermöglicht komplexe Layout-Effekte und gleichzeitig die mathematische Präzision, die für konsistente Textpositionierungsoperationen unter verschiedenen Betrachtungsbedingungen erforderlich ist.

Das Transformationssystem arbeitet mit zwei primären Matrizen:
Aktuelle Transformationsmatrix (CTM).
Die CTM verwaltet globale Koordinatentransformationen, die alle grafischen Elemente, einschließlich Text, beeinflussen. Sie steuert Operationen wie Rotation, Skalierung, Translation und Schrägung auf Seitenebene. Wenn Sie eine Transformation mit Operatoren wie cm (Matrix verketten) anwenden, ändern Sie die CTM.
Textmatrix (TM).
Die TM verwaltet speziell die Textpositionierung und lokale Texttransformationen. Sie arbeitet in Verbindung mit der CTM, um sicherzustellen, dass Textpositionierungsoperationen wie Zeilenumbrüche, Zeichenversatz und Absatzfluss weiterhin korrekt funktionieren, auch wenn der gesamte Textblock transformiert wird.
Sequenz der Matrixtransformationen.
Wenn PDF transformierten Text darstellt, folgt es einer präzisen mathematischen Sequenz:
- Berechnung des Glyphenabstands: Einzelne Zeichenformen werden in Glyphenraumkoordinaten definiert.
- Transformation des Textraums: Zeichen werden im Textraum unter Verwendung von Schriftgröße und Textparameterpositionen platziert.
- Anwendung der Textmatrix: Die Textmatrix transformiert Koordinaten vom Textraum in den Benutzerraum.
- Anwendung der Grafikmatrix: Die aktuelle Transformationsmatrix bestimmt die endgültige Position und Ausrichtung.
- Konvertierung in den Gerätebereich: Die endgültigen Koordinaten werden in gerätespezifische Einheiten für die Darstellung umgewandelt.
Dieser mehrstufige Prozess stellt sicher, dass Texttransformationen mathematisch präzise und visuell konsistent unter verschiedenen Betrachtungsbedingungen, Ausgabegeräten und Skalierungsfaktoren bleiben.
|
1 2 3 4 5 6 7 8 9 10 11 |
% Set up rotation transformation 0.96 0.25 -0.25 0.96 0 0 cm BT /F0 48 Tf 48 TL % Set text matrix for positioning 1 0 0 1 270 240 Tm (Text and graphics) Tj T* (transforms combined) Tj T* (with proper newlines) Tj ET |
Praktische Anwendungen von Texttransformationen.
- Rotierte Überschriften und Beschriftungen: Erstellung von geneigtem Text für Diagramme, Zeichnungen und spezielle Layouts.
- Künstlerische Typografie: Implementierung kreativer Texteffekte unter Beibehaltung der Lesbarkeit.
- Mehrfach ausgerichtete Dokumente: Unterstützung von Dokumenten mit gemischten Hoch- und Querformat-Elementen.
- Koordinatensystemausrichtung: Anpassung der Textausrichtung an vorhandene Grafik-Koordinatensysteme.
Umfassende Schriftartauswahl und Ressourcenverwaltung.
Die Schriftartverarbeitung in PDF beinhaltet ein ausgeklügeltes Ressourcenverwaltungssystem, das weit über die einfache Schriftartauswahl hinausgeht. Das System muss Schriftressourcen, Zeichensatzkodierungen, Skalierungsoperationen und Kompatibilitätsanforderungen effizient verwalten und gleichzeitig eine optimale Rendering-Leistung in verschiedenen Anzeigemediengrößen gewährleisten.
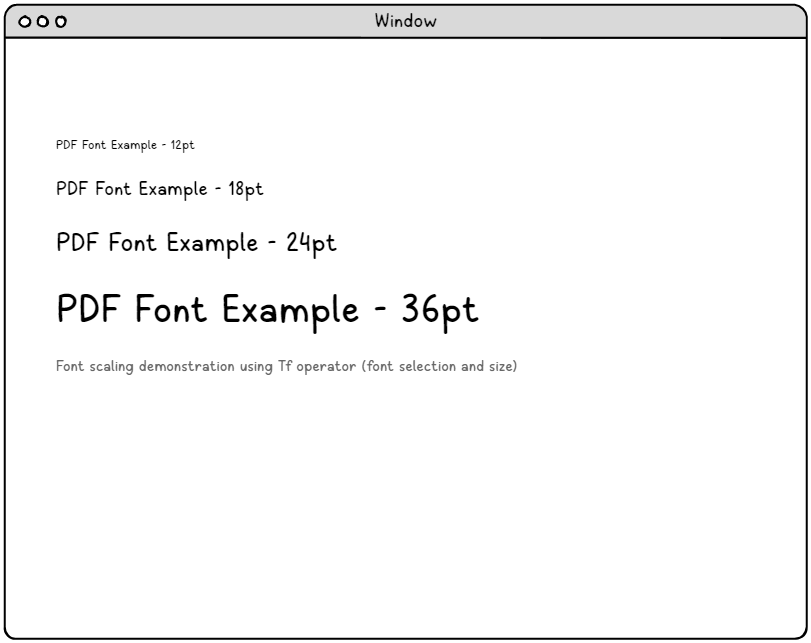
Schriftartressourcen-Dictionariesystem.
PDF-Dokumente verwenden eine hierarchische Schriftart-Dictionary-Struktur, die symbolische Namen auf tatsächliche Schriftartressourcen abbildet. Diese indirekte Schicht erfüllt mehrere wichtige Zwecke in der Dokumentenarchitektur:
- Ressourcenoptimierung: Mehrere Seiten und Inhaltsströme können identische Schriftartressourcen gemeinsam nutzen, ohne Duplikate zu erzeugen.
- Substitutionssteuerung: Schriftart-Fallback-Mechanismen können auf Ressourcenebene implementiert werden, ohne Inhaltsströme zu beeinflussen.
- Kodierungsverwaltung: Zeichensatzschemata können mit bestimmten Schriftartinstanzen verknüpft werden.
- Leistungsverbesserung: Das Laden und Parsen von Schriftarten kann durch intelligente Caching-Strategien optimiert werden.
Schriftarten und technische Eigenschaften.
Type 1 (PostScript) Schriftarten.
Type 1-Schriftarten repräsentieren Adobes ursprüngliche skalierbare Schrifttechnologie und verwenden kubische Bézier-Kurven, um Zeichenkonturen mit mathematischer Präzision zu definieren. Diese Schriftarten zeichnen sich durch ihre hervorragenden Skalierungseigenschaften und ausgeklügelten Hinting-Systeme in professionellen Publishing-Anwendungen aus.
Wichtige Merkmale von Type 1:
- Kubische Bézier-Konturen: Mathematisch präzise Kurvendefinitionen, die sich gleichmäßig auf jede Größe skalieren lassen.
- PostScript-Hinting: Intelligente Umrissanpassung für optimale Darstellung bei kleinen Größen.
- Encoding-Flexibilität: Unterstützung für benutzerdefinierte Zeichenkodierungen und spezielle Zeichensätze.
- Embedding-Kompatibilität: Vollständige Embedding-Unterstützung mit Mechanismen zur Wahrung der Lizenzbestimmungen.
TrueType-Schriftarten
TrueType-Schriftarten verwenden quadratische Bézier-Kurven und enthalten detaillierte Hinweise, die speziell für die Bildschirmdarstellung und Geräte mit niedriger Auflösung optimiert sind. Ursprünglich von Apple entwickelt und später von Microsoft übernommen, bieten TrueType-Schriftarten eine hervorragende plattformübergreifende Kompatibilität.
Vorteile von TrueType:
- Bildschirmoptimierung: Erweiterte Hilfesysteme, optimiert für die Ausrichtung am Pixelraster.
- Plattformkompatibilität: Breite Unterstützung für verschiedene Betriebssysteme und Anwendungen.
- Kompakte Speicherung: Effiziente Darstellung von Umrissen mithilfe von quadratischen Kurven.
- Unicode-Unterstützung: Native Unterstützung für große Zeichensätze und internationale Texte.
OpenType-Schriften
OpenType repräsentiert die Weiterentwicklung der digitalen Typografie und vereint die besten technischen Eigenschaften sowohl von Type 1- als auch von TrueType-Schriften und fügt revolutionäre typografische Funktionen hinzu, die die Art und Weise verändern, wie professioneller Text dargestellt wird.
OpenType-Innovationen:
- Erweiterte Typografie: Kontextuelle Ligaturen, Verzierungen, Alternativen und Stilsätze
- Umfangreiche Zeichensätze: Unterstützung für Tausende von Zeichen und mehrere Schriftsysteme
- Layout-Intelligenz: Ausgereifte Regeln für kontextuelle Zeichenersetzung und -positionierung.
- Plattformübergreifende Konsistenz: Identisches Rendering-Verhalten über verschiedene Systeme und Anwendungen hinweg.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
BT % Select font and set initial size /F0 12 Tf 1 0 0 1 50 750 Tm (12-point font example) Tj % Change to larger size, same font /F0 18 Tf 0 -25 Td (18-point font example) Tj % Even larger size /F0 24 Tf 0 -35 Td (24-point font example) Tj % Largest size /F0 36 Tf 0 -50 Td (36-point font example) Tj ET |
Professionelle Zeichenabstände und Glyphenpositionierung.
Professionelle Typografie erfordert eine präzise Kontrolle über den Abstand zwischen einzelnen Zeichen. Der visuelle Raum zwischen verschiedenen Buchstabenkombinationen variiert erheblich, abhängig von den Zeichenformen, und intelligente Kerning-Anpassungen sind unerlässlich, um optisch ansprechenden und gut lesbaren Text zu erstellen, der professionellen Publikationsstandards entspricht.

Der TJ-Operator bietet fortschrittliche Funktionen zur Glyphenpositionierung, die über einfache Zeichen- und Wortabstände hinausgehen. Anstatt mit monolithischen Textzeichenketten zu arbeiten, akzeptiert TJ ein heterogenes Array, das eine zeichengenaue Positionierung mit mathematischer Präzision ermöglicht.
Verständnis der TJ-Array-Architektur.
Der arraybasierte Ansatz des TJ-Operators revolutioniert die Textpositionierung, indem er gemischte Inhalte akzeptiert:
- String-Elemente: Enthalten den tatsächlichen Textinhalt, der mit Standard-Schriftkodierung dargestellt wird.
- Numerische Elemente: Geben horizontale Anpassungen in Tausendtel einer Text-Einheit an.
- Negative Werte: Bringen nachfolgende Zeichen näher zusammen und verringern so den Abstand zwischen den Zeichen.
- Positive Werte: Erhöhen den Abstand zwischen Zeichen und erweitern so das Textlayout.
Diese präzise Steuerung ermöglicht eine professionelle Typografie mit genauen Anpassungen des Zeichenabstands, die mit einfacheren Textoperatoren nicht möglich wären. Das System ermöglicht sowohl ästhetische Verbesserungen als auch technische Korrekturen der Schriftmetriken.
|
1 2 3 4 5 6 7 8 9 |
BT /F0 48 Tf 1 0 0 1 100 400 Tm % Standard text rendering (WAVE Type) Tj 0 -60 Td % Kerned text with precise adjustments [(W) -120 (A) -80 (V) -100 (E) 50 (T) -20 (y) -10 (p) -5 (e)] TJ ET |
Erweiterte Kerning-Strategien
Optisches Kerning
Optisches Kerning passt den Zeichenabstand basierend auf dem visuellen Erscheinungsbild von Zeichenkombinationen an, anstatt sich ausschließlich auf integrierte Schriftmetriken zu verlassen. Dieser Ansatz berücksichtigt die tatsächlichen Formen benachbarter Zeichen und ihre visuelle Interaktion.
Metrisches Kerning
Metrisches Kerning verwendet die in der Schrift integrierten Kerning-Tabellen, um den Abstand zwischen bestimmten Zeichenpaaren anzupassen. Professionelle Schriften enthalten umfangreiche Kerning-Tabellen mit Tausenden von Zeichenpaar-Anpassungen.
Manuelles Kerning
Manuelles Kerning ermöglicht präzise, zeichenweise Anpassungen für spezifische Designanforderungen oder zur Korrektur problematischer Zeichenkombinationen, die von automatischen Kerning-Systemen nicht ausreichend berücksichtigt werden.
Praktische Anwendungen für Kerning.
- Logo und Branding: Präzise Kontrolle über die Typografie der Corporate Identity.
- Überschriften-Typografie: Optimierung von großen Textmengen für maximale visuelle Wirkung.
- Feine Typografie: Erzielung einer textuellen Anordnung in Publikationsqualität.
- Mehrsprachige Unterstützung: Anpassung des Abstands für verschiedene Schriftsysteme und Zeichenkombinationen.
Textwiedergabe-Modi und visuelle Effekte.
PDF bietet acht verschiedene Textwiedergabe-Modi, die steuern, wie Text visuell dargestellt wird, und bieten umfassende Flexibilität für die Erstellung vielfältiger typografischer Effekte. Diese Modi bestimmen, ob Text gefüllt, umrandet, für Clipping-Pfade verwendet oder für spezielle Zwecke unsichtbar dargestellt wird.
Vollständige Referenz zu den Textwiedergabe-Modi.
| Mode | Name | Visual Effect | Common Uses |
|---|---|---|---|
| 0 | Fill | Solid color fill only | Standard body text |
| 1 | Stroke | Outline only, no fill | Decorative headers |
| 2 | Fill and Stroke | Both fill and outline | Emphasized text |
| 3 | Invisible | No visual rendering | Text positioning |
| 4 | Fill and Add to Path | Fill plus path construction | Text-based clipping |
| 5 | Stroke and Add to Path | Stroke plus path construction | Complex path operations |
| 6 | Fill, Stroke, and Add to Path | Complete text with path | Advanced graphics integration |
| 7 | Add to Path Only | Path construction, no rendering | Clipping path creation |
Erweiterte Anwendungen für Textwiedergabe-Modi.
Unsichtbarer Textmodus (Modus 3).
Unsichtbarer Text dient in PDF-Dokumenten mehreren speziellen Zwecken:
- Durchsuchbare Bild-PDFs: Überlagerung von unsichtbarem Text auf gescannten Dokumenten für Suchfunktionen.
- Textpositionierung: Vorwärtsbewegung der Textposition ohne visuelle Ausgabe für komplexe Layouts.
- Verbesserung der Barrierefreiheit: Bereitstellung alternativer Textbeschreibungen ohne visuelle Ablenkung.
- Template-Systeme: Erstellung von Positionierungsrahmen für die dynamische Inhaltserstellung.
Pfadkonstruktionsmodi (Modi 4-7).
Diese erweiterten Modi ermöglichen eine ausgefeilte Integration zwischen Text- und Grafiksystemen.
- Textbasiertes Clipping: Verwenden Sie Textformen, um andere grafische Elemente zu maskieren.
- Komplexes Maskieren: Erstellen Sie komplexe Maskierungseffekte mit Hilfe von Zeichenformen.
- Künstlerische Effekte: Kombinieren Sie Text mit Farbverläufen, Mustern und anderen grafischen Elementen.
- Interaktive Elemente: Erstellen Sie anklickbare Bereiche, die genau den Textgrenzen entsprechen.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
BT /F0 36 Tf 1 0 0 1 100 500 Tm % Standard filled text 0 Tr (Filled Text) Tj 0 -50 Td % Stroked text only 1 Tr 2 w (Stroked Text) Tj 0 -50 Td % Both filled and stroked 2 Tr (Filled and Stroked) Tj ET |
Schriftarten-Einbettung und Subset-Optimierung.
Die Schriftarten-Einbettung stellt eine der wichtigsten technischen Herausforderungen bei der PDF-Erstellung dar, da sie die Balance zwischen Dokumentportabilität, Dateigrößenoptimierung und rechtlicher Konformität finden muss. Das Einbettungssystem muss sicherstellen, dass Dokumente auf verschiedenen Systemen identisch gerendert werden, während gleichzeitig die Schriftartenlizenzbestimmungen eingehalten und vernünftige Dateigrößen beibehalten werden.
Schriftarten-Einbettungsstrategien.
Vollständige Schriftarten-Einbettung.
Die vollständige Schriftarten-Einbettung beinhaltet die gesamte Schriftartdatei innerhalb des PDF-Dokuments, wodurch eine perfekte Rendering-Kompatibilität gewährleistet wird, jedoch zu Lasten einer größeren Dateigröße. Dieser Ansatz garantiert, dass alle Zeichen, Kerning-Informationen und typografischen Merkmale verfügbar bleiben.
Vorteile:
- Vollständige Kompatibilität: Alle Schriftfunktionen bleiben unabhängig vom Zielsystem verfügbar.
- Wiedergabetreue: Perfekte Reproduktion der ursprünglichen Typografie und des Abstands.
- Funktionserhalt: Erweiterte OpenType-Funktionen bleiben funktionsfähig.
- Zukunftsfähigkeit: Dokumente bleiben lesbar, auch wenn sich die Schriftverfügbarkeit ändert.
Nachteile:
- Auswirkungen auf die Dateigröße: Deutliche Erhöhung der Dokumentgröße, insbesondere bei Verwendung mehrerer Schriftarten.
- Lizenzrechtliche Aspekte: Kann gegen Lizenzvereinbarungen verstoßen, die das Einbetten von Schriftarten einschränken.
- Verarbeitungsaufwand: Erhöhter Speicherbedarf und Verarbeitungszeit für das Laden von Schriftarten.
Schriftart-Subsetting:
Schriftart-Subsetting bettet nur die tatsächlich im Dokument verwendeten Zeichen ein, wodurch die Dateigröße drastisch reduziert wird, während die Genauigkeit der Darstellung für den enthaltenen Zeichensatz erhalten bleibt.
Vorteile der Teilmengenbildung:
- Optimale Dateigröße: Minimale Auswirkungen auf die Dokumentgröße bei gleichzeitiger Wahrung der Typografie.
- Lizenzkonformität: Reduzierte rechtliche Bedenken, da nur verwendete Zeichen enthalten sind.
- Leistungsverbesserung: Schnellere Schriftladezeiten und geringerer Speicherverbrauch.
- Bandbreiteneffizienz: Kleinere Dokumente werden schneller über Netzwerke übertragen.
Zeichenkodierung und Unicode-Zuordnung.
Das Zeichenkodierungssystem von PDF muss die Lücke zwischen schriftartspezifischen Zeichencodes und universellen Zeichenidentifikationssystemen wie Unicode überbrücken. Dieser Zuordnungsprozess ist entscheidend für die Textextraktion, die Suche und die Barrierefreiheit.
Kodierungsmechanismen.
Integrierte Kodierung: Verwendet die interne Zeichenzuordnung der Schriftart, geeignet für Standard-westliche Zeichensätze, aber eingeschränkt für internationale Inhalte.
Standard-PDF-Kodierungen: Vordefinierte Kodierungsschemata wie WinAnsiEncoding und MacRomanEncoding, die eine konsistente Zeichenzuordnung über verschiedene Plattformen hinweg bieten.
Benutzerdefinierte Kodierung: Dokument-spezifische Zeichenabbildungen, die die Unterstützung für spezielle Zeichen oder ältere Schriftarten ermöglichen.
Unicode (CMap)-Systeme: Moderne Methode, die Zeichenabbildungen (CMaps) verwendet, die eine direkte Zuordnung zwischen Zeichencodes und Unicode-Werten bereitstellen.
ToUnicode-Zuordnungstabellen
ToUnicode-CMaps ermöglichen eine genaue Textextraktion und -suche, indem sie eine Brücke zwischen schriftenspezifischen Zeichencodes und Unicode-Werten bilden. Diese Zuordnungstabellen sind für Barrierefreiheit und Inhaltsanalyse unerlässlich.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
% Example ToUnicode CMap structure 23 0 obj << /Length 317 >> stream /CIDInit /ProcSet findresource begin 12 dict begin begincmap /CIDSystemInfo << /Registry (Adobe) /Ordering (UCS) /Supplement 0 >> def /CMapName /Adobe-Identity-UCS def 1 begincodespacerange <0001> endcodespacerange 2 beginbfchar <0001> <0041> % Map glyph 1 to Unicode U+0041 (A) <0002> <0042> % Map glyph 2 to Unicode U+0042 (B) endbfchar endcmap CMapName currentdict /CMap defineresource pop end end endstream endobj |
Die komplexe Herausforderung der PDF-Textextraktion
Die Textextraktion aus PDF-Dokumenten stellt einen der technisch anspruchsvollsten Aspekte der PDF-Verarbeitung dar und erfordert ausgefeilte Algorithmen, die eine logische Lesereihenfolge aus einem grafikorientierten Format rekonstruieren können. Im Gegensatz zu herkömmlichen Textformaten, die die semantische Struktur beibehalten, speichert PDF Text als eine Reihe von positionierten grafischen Elementen, was die Extraktion zu einem komplexen Reverse-Engineering-Prozess macht.
Grundlegende Herausforderungen bei der Textextraktion.
Nicht-sequenzielle Textpositionierung.
PDF-Inhaltsströme positionieren Textelemente basierend auf visuellen Layoutanforderungen und nicht auf der logischen Lesereihenfolge. Ein einzelner Absatz kann durch Dutzende separater Textpositionierungsbefehle dargestellt werden, die im Inhaltsstrom verstreut sind und mit Grafikoperationen und anderen Nicht-Text-Elementen vermischt sind.
Dieser Positionierungsansatz verursacht mehrere Schwierigkeiten bei der Extraktion:
- Rekonstruktion der Lesereihenfolge: Bestimmung der korrekten Reihenfolge für Textelemente, die außerhalb der Reihenfolge positioniert sind.
- Spaltenerkennung: Identifizierung von mehrspaltigen Layouts und Bestimmung des korrekten Spaltenflusses.
- Analyse der Seitenstruktur: Unterscheidung von Kopfzeilen, Fußzeilen, Seitenleisten und Hauptinhaltsbereichen.
- Auflösung von Querverweisen: Verknüpfung verwandter Textelemente, die durch Grafiken oder Formatierungen getrennt sind.
Probleme mit Schriftarten und Kodierungen.
Die Extraktion von Zeichen erfordert eine genaue Interpretation von Schriftkodierungsschemata, die sich erheblich zwischen verschiedenen Schriftarten und Dokumenterstellungssystemen unterscheiden können.
- Fehlende Schriftartinformationen: Dokumente können auf Schriftarten verweisen, die auf dem System, auf dem die Extraktion durchgeführt wird, nicht verfügbar sind.
- Encoding-Variationen: Unterschiedliche Schriftarten können inkompatible Zeichenkodierungsschemata verwenden.
- Einschränkungen bei Teilmengen-Schriftarten: Eingebettete Schriftteilmengen können unvollständige Zeichenabbildungsinformationen enthalten.
- Unicode-Zuordnungsfehler: Falsche oder fehlende ToUnicode-Tabellen können zu einer falschen Zeicheninterpretation führen.
Erkennung der Layoutstruktur.
Professionelle Dokumente verwenden komplexe Layoutstrukturen, die automatisierte Extraktionssysteme herausfordern.
- Tabellenerkennung: Erkennung von tabellarischen Daten und Beibehaltung der Zeilen-/Spaltenbeziehungen.
- Listenstruktur: Erkennung von Aufzählungs- und nummerierten Listen mit korrekter hierarchischer Organisation.
- Schwebende Elemente: Verarbeitung von Textfeldern, Seitenleisten und Hervorhebungen, die den normalen Textfluss unterbrechen.
- Kontinuität über mehrere Seiten: Aufrechterhaltung des Kontexts über Seiten hinweg für Absätze und Abschnitte.
Erweiterte Extraktionsmethoden.
Ansatz für mehrstufige Analyse.
Hochentwickelte Extraktionssysteme verwenden mehrere Analysephasen, wobei jede Phase sich auf unterschiedliche Aspekte der Dokumentstruktur konzentriert:
- Zeichenebenen-Phase: Extrahieren von einzelnen Zeichenpositionen, Schriftarten und Kodierungsinformationen.
- Wortbildungs-Phase: Gruppieren von Zeichen zu Wörtern basierend auf Abständen und Schriftartmerkmalen.
- Zeilenerkennungs-Phase: Identifizieren von Textzeilen mithilfe der Basisanalyse und vertikaler Abstände.
- Paragraph Assembly Pass: Kombinieren von Zeilen zu Absätzen basierend auf Einrückungen und Abständen.
- Struktur Analyse Pass: Erkennen von Überschriften, Listen, Tabellen und anderen Dokumentelementen.
- Content Organization Pass: Anordnen von Elementen in einer logischen Lesereihenfolge und hierarchischer Struktur.
Machine Learning Enhancement.
Moderne Extraktionssysteme verwenden zunehmend maschinelle Lerntechniken, um die Genauigkeit zu verbessern.
- Layout-Klassifizierung: Trainieren von Modellen zur Erkennung gängiger Dokumentlayoutmuster.
- Vorhersage der Lesereihenfolge: Verwendung neuronaler Netze zur Bestimmung der optimalen Textreihenfolge.
- Erkennung von Inhaltstypen: Automatische Klassifizierung von Textelementen als Überschriften, Fließtext, Bildunterschriften usw.
- Erkennung der Tabellenstruktur: Erweiterte Algorithmen für die komplexe Erkennung von Tabellenlayouts.
Beispielcode für die Textextraktion.
Das folgende Beispiel demonstriert die Komplexität, die bei der Rekonstruktion von Text aus PDF-Positionsbefehlen involviert ist:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
% Complex text positioning that challenges extraction BT /F0 12 Tf 1 0 0 1 72 720 Tm (This text appears) Tj 150 0 Td (out of order) Tj -150 -15 Td (in the content stream) Tj 200 0 Td (but should be) Tj -200 -15 Td (reconstructed properly) Tj 100 0 Td (by extraction algorithms.) Tj ET % Graphics elements that interrupt text flow q 1 0 0 1 100 650 cm 0.5 g 0 0 200 50 re f Q % Continuation of text after graphics BT /F0 12 Tf 1 0 0 1 72 630 Tm (Text continues after graphics elements) Tj ET |
Qualitätssicherung und Validierung.
Professionelle Extraktionssysteme implementieren mehrere Validierungsmechanismen:
- Linguistische Analyse: Wörterbuchprüfungen und grammatikalische Validierung zur Identifizierung von Extraktionsfehlern.
- Formatkonsistenz: Überprüfung der extrahierten Struktur anhand gängiger Dokumentmuster.
- Kreuzreferenzvalidierung: Sicherstellung, dass interne Dokumentverweise erhalten bleiben.
- Überprüfung der Zeichenkodierung: Erkennung und Korrektur von Zeichenkodierungsfehlern.
Leistungsoptimierung und Best Practices.
Eine effiziente PDF-Textverarbeitung erfordert sorgfältige Aufmerksamkeit auf Leistungseffekte, die sich erheblich auf die Rendering-Geschwindigkeit, den Speicherverbrauch und die allgemeine Systemreaktionsfähigkeit auswirken können. Moderne PDF-Anwendungen müssen Dokumente von einfachen, einseitigen Dateien bis hin zu komplexen Publikationen mit Tausenden von Seiten verarbeiten können.
Schriftressourcenverwaltung.
Intelligente Caching-Strategien
Das Laden und Parsen von Schriftarten sind ressourcenintensive Operationen, von denen strategisches Caching erheblich profitieren kann:
- Ressourcen-Level-Caching: Cachen Sie geparste Schriftartobjekte auf Ressourcendiktarebene, um redundantes Parsen zu vermeiden.
- Glyphen-Rendering-Cache: Speichern Sie gerenderte Zeichen-Glyphen zur Wiederverwendung in mehreren Textoperationen.
- Metrik-Berechnungs-Cache: Cachen Sie Schriftmetrik-Berechnungen, um wiederholte Berechnungen zu vermeiden.
- Cross-Document Caching: Teilen Sie Schriftressourcen bei Bedarf zwischen mehreren PDF-Dokumenten.
Strategien für das Speicher-Management.
Effizientes Speicher-Management verhindert Leistungseinbußen bei textlastigen Anwendungen.
- Lazy Loading: Laden Sie Schriftressourcen nur dann, wenn sie für die Darstellung oder Verarbeitung erforderlich sind.
- Resource Pooling: Verwenden Sie Pools von häufig verwendeten Schriftobjekten, um den Speicher-Overhead zu reduzieren.
- Garbage Collection Optimierung: Implementierung intelligenter Bereinigungsstrategien für ungenutzte Schriftressourcen.
- Speicherabbildung: Verwendung von Speicherabbildungsdateien für große eingebettete Schriftarten, um den RAM-Verbrauch zu reduzieren.
Text-Stream-Optimierung.
Inhalts-Stream-Organisation.
Eine effiziente Organisation von Textoperationen kann die Rendering-Leistung erheblich verbessern:
- Batch-Textoperationen: Gruppieren Sie verwandte Textoperationen innerhalb einzelner BT/ET-Blöcke, um die Anzahl der Zustandsänderungen zu minimieren.
- Minimieren Sie Schriftwechsel. Organisieren Sie Inhalte, um Schriftartauswahldurchläufe zu reduzieren.
- Strategische Positionierung: Verwenden Sie relative Positionierung (Td, TD) anstelle von absoluter Positionierung (Tm), wenn dies angebracht ist.
- Zustandskonsolidierung: Fassen Sie kompatible Textzustandsänderungen zu einzelnen Operationen zusammen.
Optimierung der Rendering-Pipeline.
Moderne PDF-Prozessoren verwenden ausgefeilte Rendering-Pipelines.
- Multithreading: Parallele Verarbeitung unabhängiger Textelemente.
- GPU-Beschleunigung: Hardwarebeschleunigte Glyphenrasterung und Komposition.
- Progressives Rendering: Anzeige des Textinhalts während der Hintergrundverarbeitung.
- Viewport-Culling: Überspringen der Verarbeitung von Textelementen außerhalb des sichtbaren Bereichs.
Barrierefreiheit und universelles Design.
Die Erstellung zugänglicher PDF-Dokumente erfordert sorgfältige Aufmerksamkeit für Textstruktur, semantische Markierung und Kompatibilität mit Hilfstechnologien. Moderne Barrierefreiheitsstandards erfordern, dass PDF-Dokumente nahtlos mit Bildschirmleseprogrammen, Spracherkennungssoftware und anderen Hilfstechnologien funktionieren.
Strukturierte PDF-Dateien mit Tags.
Strukturierte PDF-Dateien mit Tags bieten semantische Strukturinformationen, die es Hilfstechnologien ermöglichen, die Dokumentorganisation zu verstehen.
- Logische Strukturhierarchie: Hierarchische Organisation von Dokumentelementen.
- Rollenbasierte Tagging-Methode: Semantische Identifizierung von Überschriften, Absätzen, Listen und anderen Elementen.
- Lesereihenfolge: Explizite Definition der korrekten Lesereihenfolge.
- Alternative Beschreibungen: Textalternativen für grafische Elemente und komplexe Strukturen.
Internationale Textunterstützung.
Globale Dokumentzugänglichkeit erfordert umfassende internationale Textunterstützung.
- Unicode-Konformität: Vollständige Unterstützung für internationale Zeichensätze und Schriftsysteme.
- Bidirektionale Textdarstellung: Korrekte Behandlung von Inhalten, die sowohl von links nach rechts als auch von rechts nach links verlaufen.
- Komplexe Schriftarten: Unterstützung für kontextabhängige Zeichenformung in Arabisch, indischen und anderen komplexen Schriftsystemen.
- Unterstützung für vertikale Textdarstellung: Traditionelle chinesische, japanische und mongolische vertikale Textlayouts.
Zukünftige Entwicklungen in der PDF-Typografie.
Die PDF-Spezifikation entwickelt sich ständig weiter und integriert neue Funktionen, die aufkommende Anforderungen in digitalen Dokumentenworkflows, Web-Integration und fortschrittlichen Typografieanwendungen erfüllen.
Typografie-Funktionen der nächsten Generation
Variable Font-Technologie
Variable Fonts stellen einen revolutionären Fortschritt in der digitalen Typografie dar und ermöglichen es, dass einzelne Schriftdateien mehrere Designvarianten enthalten:
- Varianz der Schriftstärke: Kontinuierliche Anpassung von dünn zu fett.
- Varianz der Schriftbreite: Dynamische Anpassung von kondensiert zu erweitert.
- Optische Größe: Automatische Optimierung für verschiedene Bildschirmgrößen.
- Benutzerdefinierte Achsen: Schriftenspezifische Variationen wie Kontrast, x-Höhe oder stilistische Variationen.
Farbfont-Integration.
Erweiterte Farbfonts ermöglichen eine umfangreiche typografische Gestaltung, die mit herkömmlichen Schriften bisher nicht möglich war.
- Eingebettete Grafiken: Schriften, die vollständige Farb-Bitmap- oder Vektorgrafiken enthalten.
- Gradient-Unterstützung: Zeichen mit komplexen Farbverläufen und Effekten.
- Mehrschichtige Schriftarten: Schriftarten mit separaten Ebenen für Schatten, Umrandungen und dekorative Elemente.
- Animierte Typografie: Zeitbasierte typografische Effekte für digitale Präsentationen.
Web- und Mobile-Integration:
Da PDF-Dokumente zunehmend in Web- und Mobile-Kontexten verwendet werden, konzentrieren sich neue Funktionen auf responsive und adaptive Typografie.
- Progressives Textladen: Schnellere erste Anzeige durch Hintergrundschriftladen.
- Responsive Typografie: Adaptive Textanpassung für verschiedene Bildschirmgrößen und Ausrichtungen.
- Für Touch-Geräte optimierte Interaktion: Verbesserte Textauswahl und Interaktion für Touchscreen-Geräte.
- Unterstützung für hohe Bildschirmauflösung: Optimierte Darstellung für hochauflösende Bildschirme.
Abschluss
Die Komplexität des PDF-Textsystems spiegelt Jahrzehnte der Entwicklung in digitaler Typografie und Dokumententechnologie wider. Jeder Operator, Parameter und jedes Kodierungsschema erfüllt spezifische Zwecke innerhalb des gesamten Ökosystems der professionellen Dokumenterstellung. Schrift-Embedding-Strategien, Zeichensatzsysteme, Transformationsmatrizen und Rendering-Modi arbeiten zusammen, um eine robuste Plattform für die Textkommunikation zu schaffen.
Während Sie weiterhin mit PDF-Text und -Schriften arbeiten, denken Sie daran, dass die Komplexität der Spezifikation wichtige Zwecke erfüllt: die Sicherstellung der Dokumentenlebensdauer, die Aufrechterhaltung der visuellen Integrität, die Unterstützung internationaler Inhalte und die Ermöglichung der Barrierefreiheit. Diese grundlegenden Konzepte werden Ihnen nützlich sein, während die PDF-Technologie sich weiterentwickelt und sich an neue Herausforderungen in der digitalen Kommunikation anpasst.