Verständnis von PDF-XML-Metadaten und Lesezeichen: Ein technischer Leitfaden.
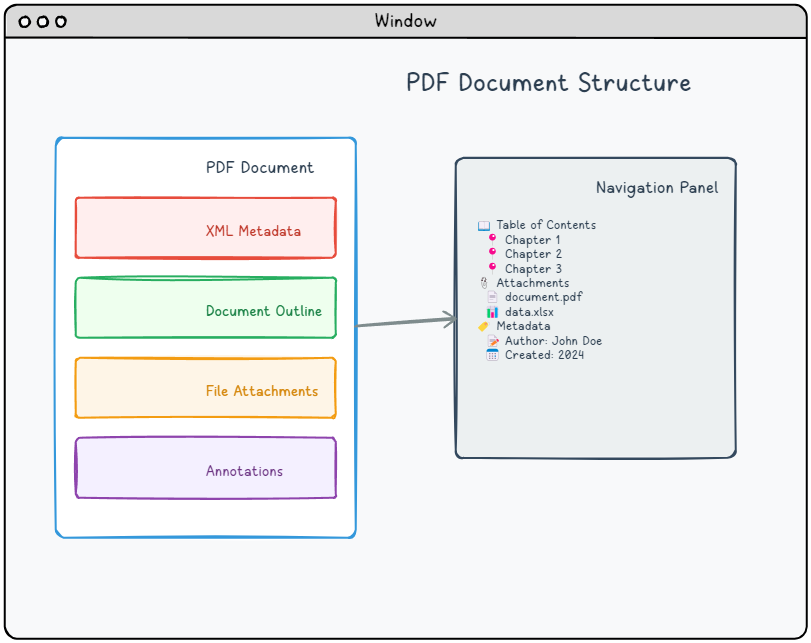
Wichtige Themen:
📍 Zielorte.
Präzise Positionsmarkierungen, die bestimmte Stellen innerhalb von PDF-Dokumenten definieren. Diese ermöglichen eine genaue Navigation für Lesezeichen und Hyperlinks, während Dokumentstrukturen eine hierarchische Inhaltsverzeichnis-Funktionalität bieten.
📄 XML-Metadaten
Strukturierte XML-Datenströme, die umfassende Dokumentmetadaten mithilfe standardisierter XMP-Formate bereitstellen und über grundlegende Dokumenteigenschaften hinausgehen, um detaillierte Informationen bereitzustellen.
📎 Datei-Anhänge
Vollständige Dateiebettungsfunktion, die externe Ressourcen direkt in PDF-Dokumenten verpackt und so eigenständige Dokumentbündel erstellt, ähnlich wie E-Mail-Anhänge.
📝 Anmerkungen
Interaktive Overlay-Elemente, die Text, Grafiken und klickbare Funktionen zu PDF-Seiten hinzufügen, ohne den zugrunde liegenden Inhalt zu ändern. Enthält Hyperlinks für eine nahtlose Dokumentnavigation und verschiedene Markierungswerkzeuge für eine verbesserte Benutzerinteraktion.
Lesezeichen und Ziele

Die Dokumentnavigation basiert auf hierarchischen Lesezeichenstrukturen, technisch bekannt als die DokumentstrukturDieses baumartig strukturierte System präsentiert anklickbare Einträge – typischerweise Kapitelüberschriften, Abschnittsüberschriften und Unterabschnittsnamen –, die es Lesern ermöglichen, schnell zu bestimmten Teilen des Dokuments zu springen. Jeder Lesezeicheneintrag kombiniert angezeigten Text mit Zielinformationen, die genau angeben, wohin der Link führen soll.
Verständnis von Zielen
PDF-Ziele dienen als präzise Positionsmarkierungen innerhalb eines Dokuments und geben an, welche Seite angezeigt werden soll, wo auf dieser Seite die Ansicht positioniert werden soll und welche Zoomstufe angewendet werden soll. Sie können Ziele auf zwei Arten erstellen: Sie können sie direkt inline definieren (was wir in unseren Beispielen zur Klarheit verwenden) oder sie über ein dokumentumfassendes Namenssystem anhand ihres Namens referenzieren. Die meisten PDF-Reader zeigen Lesezeichen in einem Navigationsbereich neben dem Hauptinhalt des Dokuments an.
Jedes Ziel verwendet eine Array-Struktur, wobei die spezifischen Elemente je nach gewünschtem Anzeigeverhalten variieren. Hier sind die wichtigsten verfügbaren Zielmuster:
Tabelle der Zieltypen
Hinweis: „Seite“ stellt eine indirekte Referenz auf ein Seitenobjekt dar. Standardmäßig funktionieren diese Ziele mit den Begrenzungsrahmen der Seite und greifen auf die Medienbegrenzungsrahmen zurück, wenn keine Begrenzungsrahmen definiert sind.
| Array | Description |
|---|---|
| [page /Fit] | Scales the page to fit completely within the viewer window, adjusting both width and height proportionally. |
| [page /FitH top] | Positions the specified top coordinate at the window’s top edge while scaling horizontally to fit the full page width. |
| [page /FitV left] | Aligns the specified left coordinate with the window’s left edge while scaling vertically to fit the full page height. |
| [page /XYZ left top zoom] | Positions the coordinates (left, top) at the window’s upper-left corner and applies the specified zoom factor. Null values preserve current settings for those parameters. |
| [page /FitR left bottom right top] | Zooms and positions the view to display the rectangular area defined by the left, bottom, right, and top coordinates. |
| [page /FitB] | Similar to /Fit, but scales based on the actual content boundaries instead of the defined crop box area. |
| [page /FitBH top] | Functions like /FitH but uses the content bounding box instead of the crop box for horizontal scaling calculations. |
| [page /FitBV left] | Operates like /FitV but calculates vertical scaling based on the content bounding box rather than the crop box boundaries. |
Struktur der Dokumentstruktur
Dokumentstrukturen erstellen eine hierarchische Navigationsstruktur, die als interaktives Inhaltsverzeichnis für PDF-Viewer dient. Diese baumartige Organisation hilft Benutzern, komplexe Dokumente schnell zu durchsuchen, indem sie einen klaren strukturellen Überblick bietet. Das System basiert auf zwei grundlegenden Objekttypen:
- Outline-Dictionary – Die Wurzel der Outline-Hierarchie
- Outline-Item-Dictionaries – Einzelne Einträge in der Outline
Struktur des Outline-Dictionary (Outline Dictionary Structure Table)
| Key | Value Type | Value |
|---|---|---|
| /Type | name | If present, must be /Outlines. |
| /First | indirect reference to dictionary | References the initial top-level outline entry in the document hierarchy. This field is mandatory when outline entries exist. |
| /Last | indirect reference to dictionary | References the final top-level outline entry in the document hierarchy. This field is mandatory when outline entries exist. |
| /Count | integer | Specifies how many outline entries are currently expanded across the entire outline tree. Can be omitted when no entries are in an open state. |
Implementierung von Outline-Items (Outline Item Implementation)
Jedes Outline-Item besteht aus einem Dictionary, das seinen Anzeigetitel, sein Ziel und seine Beziehungen zu anderen Elementen in der Hierarchie angibt.
Lassen wir uns ansehen, wie eine einfache Dokumentstruktur in der PDF-Syntax aufgebaut ist:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
8 0 obj <</Type/Outlines/Count 4/First 9 0 R/Last 9 0 R>> endobj 9 0 obj <</Title(Chapter 1: Experiment A)/Count 3/Parent 8 0 R/First 12 0 R/Last 18 0 R>> endobj 12 0 obj <</Title(1: Introduction)/Count 0/Parent 9 0 R/Next 15 0 R>> endobj 15 0 obj <</Title(2: Methodology)/Count 0/Parent 9 0 R/Prev 12 0 R/Next 18 0 R>> endobj 18 0 obj <</Title(3: Result verification)/Count 0/Parent 9 0 R/Prev 15 0 R/>> endobj |
Struktur der Outline-Element-Dictionary-Tabelle
* kennzeichnet einen erforderlichen Eintrag
| Key | Value Type | Value |
|---|---|---|
| /Title* | text string | Text to be displayed for this entry. |
| /Parent* | indirect reference to dictionary | References this item’s parent within the outline hierarchy, which can be either another outline item or the root outline dictionary. |
| /Prev | indirect reference to dictionary | References the preceding sibling item at the same hierarchical level, when applicable. |
| /Next | indirect reference to dictionary | References the following sibling item at the same hierarchical level, when applicable. |
| /First | indirect reference to dictionary | References the initial child item under this entry, when child items exist. |
| /Last | indirect reference to dictionary | References the final child item under this entry, when child items exist. |
| /Count | integer | When the entry is expanded, indicates the count of visible descendant entries. When collapsed, stores a negative value representing the total number of hidden descendants that would become visible upon expansion. |
| /Dest | name, string or array | The destination. Arrays are destinations, names are references to entries in the /Dests entry in the document catalog, strings are references to entries in the /Dests entry in the document’s name dictionary. |
XML-Metadaten
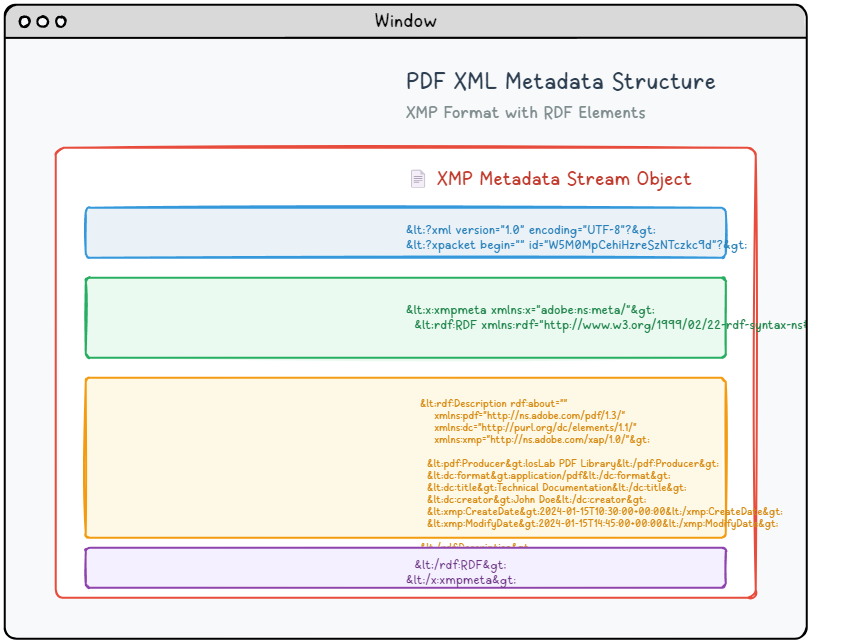
Moderne PDF-Dokumente können ausgefeilte, XML-basierte Metadatenströme enthalten, die deutlich detailliertere und strukturiertere Informationen bieten als herkömmliche Dokumenteigenschaften. Dieses fortschrittliche Metadatensystem nutzt die XMP-Spezifikation (Extensible Metadata Platform) von Adobe, um standardisierte, maschinenlesbare Dokumentbeschreibungen bereitzustellen, die die Suchbarkeit, Organisation und automatisierten Verarbeitungsprozesse verbessern.
Struktur der XMP-Metadaten
XMP-Metadaten werden als XML-Dokument verpackt, das die RDF-Syntax (Resource Description Framework) verwendet, um Dokumenteigenschaften in einem standardisierten Format zu organisieren und zu beschreiben. Diese Metadaten werden in einem dedizierten Stream-Objekt eingebettet, das eine korrekte Typenidentifikation für PDF-Prozessoren enthält:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
6 0 obj <</Length 1235/Type/Metadata/Subtype/XML>>stream <?xpacket begin="锘xBF" id="W5M0MpCehiHzreSzNTczkc9d"?> <x:xmpmeta xmlns:x="adobe:ns:meta/" x:xmptk="Adobe XMP Core 5.2-c001 63.139439, 2010/09/27-13:37:26" ><rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" ><rdf:Description rdf:about="" xmlns:pdf="http://ns.adobe.com/pdf/1.3/" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:xmp="http://ns.adobe.com/xap/1.0/" ><pdf:Producer>losLab PDF Library</pdf:Producer> <dc:creator>losLab.com</dc:creator> <dc:title>Delphi PDF SDKs</dc:title> <xmp:CreateDate>2025-06-29T10:46:27+08:00</xmp:CreateDate> <xmp:ModifyDate>2025-06-29T10:58:57+08:00</xmp:ModifyDate> <xmp:MetadataDate>2025-06-29T10:46:27+08:00</xmp:MetadataDate> <dc:description>Delphi Development Library for PDF creation & editing</dc:description> <xmp:CreatorTool>HotPDF Component</xmp:CreatorTool> <dc:subject>PDF Developer Library for RAD Studio></dc:subject> <pdf:Keywords>Delphi, PDF SDK, PDF Component</pdf:Keywords> </rdf:Description>Robust Delphi PDF development library</rdf:RDF> </x:xmpmeta> <?xpacket end="w"?> endstream endobj |
Standardisierte Metadaten-Schemas
Das XMP-Framework organisiert Metadaten mithilfe etablierter Schema-Namensräume, wobei jeder Namensraum spezifische Informationskategorien abdeckt:
📋 Dublin Core (dc:)
Grundlegende bibliografische Informationen
- dc:title – Dokumenttitel
- dc:creator – Dokumentautor(en)
- dc:subject – Dokumentthema/Schlüsselwörter
- dc:description – Dokumentbeschreibung
- dc:format – MIME-Typ
🏷️ XMP Basic (xmp:)
Kern-XMP-Eigenschaften
- xmp:CreateDate – Erstellungsdatum
- xmp:ModifyDate – Änderungsdatum
- xmp:CreatorTool – Erstellende Anwendung
- xmp:MetadataDate – Metadaten-Änderungsdatum
📄 PDF-Schema (pdf:)
PDF-spezifische Eigenschaften
- pdf:Producer – PDF-Ersteller
- pdf:Keywords – Dokument-Schlüsselwörter
- pdf:PDFVersion – PDF-Version
Integration mit dem Dokumentenverzeichnis
Der XML-Metadaten-Stream wird im Dokumentenverzeichnis referenziert:
|
1 2 3 |
1 0 obj < < Type Catalog Pages 2 0 R Metadata 10 0 R Outlines 1 0 R>> endobj |
🎯 Best Practices für XML-Metadaten
- Fügen Sie immer sowohl das Dokumentinformations-Dictionary als auch die XMP-Metadaten für maximale Kompatibilität hinzu.
- Stellen Sie sicher, dass die Metadatenwerte an beiden Stellen konsistent sind.
- Verwenden Sie die korrekte XML-Kodierung (UTF-8) für internationale Zeichen.
- Fügen Sie Erstellungs- und Änderungsdaten im ISO 8601-Format hinzu.
- Validieren Sie die XML-Struktur, um Parsing-Fehler zu vermeiden.
Datei-Anhänge
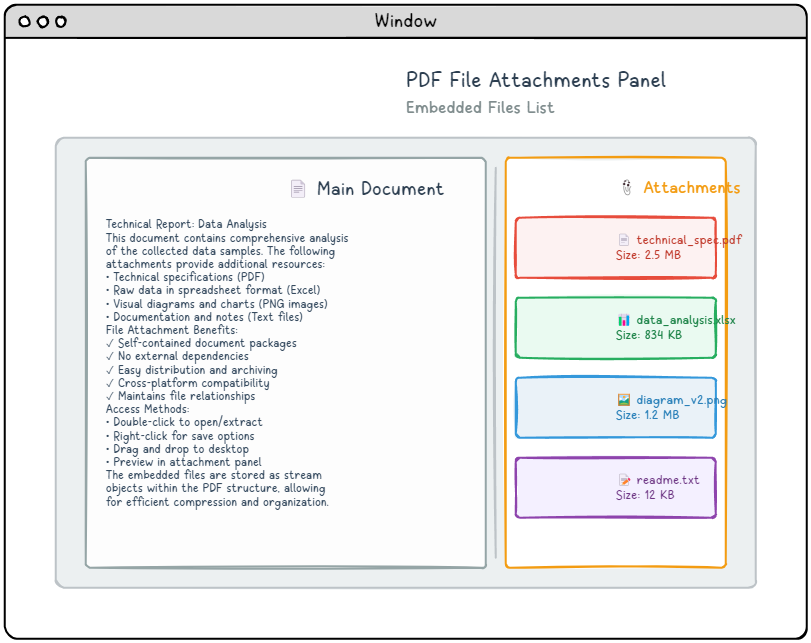
PDF-Dateianhänge bieten eine praktische Möglichkeit, externe Dateien direkt in ein PDF-Dokument einzubetten und so eigenständige Pakete zu erstellen, die alle erforderlichen Ressourcen enthalten. Diese Anhänge können entweder mit dem gesamten Dokument verknüpft oder mit bestimmten Seiten verknüpft werden, je nach Ihren Anforderungen. Die meisten modernen PDF-Betrachter zeigen diese eingebetteten Dateien in einem speziellen Anhangbereich an, wodurch es für Benutzer einfach ist, auf den enthaltenen Inhalt zuzugreifen, ihn anzuzeigen oder zu speichern. Diese Funktion ist besonders wertvoll für die Erstellung umfassender Dokumentpakete, z. B. Präsentationen mit zusätzlichen Ressourcen oder Berichten mit zugehörigen Datendateien.
Struktur eingebetteter Dateien
Im Kern besteht eine eingebettete Datei aus einem Stream-Objekt, das die eigentlichen Filedaten enthält, zusammen mit einem Stream-Dictionary-Eintrag, der Folgendes angibt: /Type /EmbeddedFileDieser einfache Ansatz ermöglicht die Speicherung jeder Art von Datei innerhalb einer PDF-Datei. Hier ist die grundlegende Struktur einer eingebetteten Datei:
|
1 2 3 4 5 6 |
8 0 obj < < Type EmbeddedFile Length 35>> stream This is a text file attachment... endstream endobj |
PDF unterstützt zwei unterschiedliche Ansätze für die Referenzierung eingebetteter Dateien, wobei jeder Ansatz unterschiedliche Anwendungsfälle bedient: Dokument-weite Anhänge, die global zugänglich sind, und seitenbezogene Anhänge, die als interaktive Elemente auf bestimmten Seiten erscheinen.
Dokument-weite Anhänge
Für dokumentweite Anhänge müssen Sie einen /EmbeddedFiles Eintrag im Namensverzeichnis hinzufügen, auf den über den /Names Eintrag im Dokumentkatalog zugegriffen wird. Dieser Ansatz macht den Anhang global im gesamten PDF verfügbar, unabhängig davon, auf welcher Seite sich der Benutzer gerade befindet:
|
1 2 3 4 5 6 |
9 0 obj < < Names << EmbeddedFiles << Names [ (attachment.txt) << EF << F 8 0 R>> /F (attachment.txt) /Type /Filespec >> ] >> >> /Pages 1 0 R /Type /Catalog >> endobj |
Erklärung der Code-Struktur
- /Names – Enthält das Namensverzeichnis für das Dokument.
- /EmbeddedFiles – Behandelt speziell eingebettete Dateinamen.
- (attachment.txt) – Der Dateiname, wie er für Benutzer sichtbar ist.
- /EF – Dictionary für eingebettete Dateien, das die tatsächliche Dateiverweise enthält.
- /F 8 0 R – Referenz zum eingebetteten Dateistream-Objekt.
- /Type /Filespec – Kennzeichnet dies als ein Dateispezifikations-Dictionary.
Seitenspezifische Anhänge
Seitenspezifische Anhänge erfordern einen anderen Ansatz unter Verwendung von Dateianhang-Annotationen. Diese werden dem /Annots Array im Dictionary der Zielseite hinzugefügt, wodurch ein sichtbares Anhangsymbol erstellt wird, mit dem Benutzer direkt auf der Seite interagieren können:
|
1 2 3 4 5 6 7 8 |
9 0 obj < < Type Page (Other dictionary entries as usual) Annots [ << FS << EF << F 8 0 R>> /F (attachment.txt) /Type /Filespec >> /Subtype /FileAttachment /Contents (attachment.txt) /Rect [ 18 796.88976378 45 823.88976378 ] >> ] >> endobj |
Eigenschaften für Seitenzusätze
- /FS – Dateispezifikations-Dictionary (gleich wie /EF oben)
- /Subtype /FileAttachment – Identifiziert diese Anmerkung als Dateianhang.
- /Contents – Tooltip-Text, der angezeigt wird, wenn der Mauszeiger über das Anhangssymbol bewegt wird.
- /Rect – Rechteck, das die Position und Größe des Anhangssymbols auf der Seite definiert.
Anwendungsfälle für Anhänge
📊 Datendateien
Betten Sie Tabellenkalkulationen, Datenbanken oder Rohdatendateien zusammen mit Berichten und Analysen ein.
🎨 Quelldateien
Fügen Sie Originaldesigndateien, CAD-Zeichnungen oder bearbeitbare Vorlagen hinzu.
📹 Mediendateien
Fügen Sie Videopräsentationen, Audioaufnahmen oder interaktive Inhalte bei.
📋 Begleitdokumente
Bündeln Sie zugehörige PDFs, Verträge oder Referenzmaterialien.
Anmerkungen

PDF-Annotationen bieten eine leistungsstarke Möglichkeit, interaktive Elemente und visuelle Markierungen zu Dokumenten hinzuzufügen, ohne den ursprünglichen Seiteninhalt zu verändern. Diese Overlay-Elemente verbessern das Leseerlebnis, indem sie es Benutzern ermöglichen, Text hervorzuheben, Kommentare hinzuzufügen oder anklickbare Links zu erstellen. Zu den nützlichsten Annotationstypen gehören Hyperlinks, die eine nahtlose Navigation zwischen verschiedenen Abschnitten eines Dokuments oder zu externen Ressourcen ermöglichen.
Struktur von Annotationen
Obwohl verschiedene Annotationstypen unterschiedliche Zwecke erfüllen, folgen sie alle einer konsistenten grundlegenden Struktur, wobei typenspezifische Eigenschaften bei Bedarf hinzugefügt werden. PDF-Seiten können mehrere Annotationen enthalten, die in einem Array organisiert sind und über den Eintrag /Annots im Dictionary jeder Seite referenziert werden. Jede Annotation wird als ihr eigenes Dictionary-Objekt mit spezifischen Eigenschaften implementiert.
Struktur des Annotation-Dictionarys Tabelle
* kennzeichnet einen erforderlichen Eintrag
| Key | Value Type | Value |
|---|---|---|
| /Type | name | When specified, this value must be set to /Annot to properly identify the dictionary type. |
| /Subtype* | name | Specifies the specific annotation category (e.g., Link, Text, Highlight). |
| /Rect* | rectangle | Defines the annotation’s position and dimensions using standard PDF coordinate units. |
| /Contents | text string | Contains the annotation’s text content or provides an alternative descriptive label for accessibility purposes. |
Beispiel für das grundlegende Annotation-Dictionary:
|
1 2 3 |
12 0 obj < < Type Annot Subtype Link Rect [100 200 300 250] Border [0 0 1] C [0.0 0.0 1.0] Dest [5 0 R XYZ null null null]>> endobj |
Häufige Annotationstypen
🔗 Link-Annotationen
Erstellen Sie anklickbare Bereiche, die zu Zielen innerhalb des Dokuments oder zu externen Ressourcen führen.
- /Subtype /Link – Identifiziert eine Verknüpfungsannotation.
- /Dest – Array für das Ziel oder benanntes Ziel.
- /A – Aktions-Dictionary für komplexere Verhaltensweisen.
📝 Text-Annotationen.
Zeigt Popup-Hinweise und Kommentare an, die beim Klicken erscheinen.
- /Subtype /Text – Wird als Textannotation identifiziert.
- /Contents – Der Textinhalt der Annotation.
- /Open – Gibt an, ob die Annotation anfänglich geöffnet ist.
🖍️ Markup Annotations
Hervorheben, Unterstreichen oder Durchstreichen von Textinhalten.
- /Subtype /Highlight – Text hervorheben
- /Subtype /Underline – Text unterstreichen
- /Subtype /StrikeOut – Text durchstreichen
Erweiterte Link-Aktionen
Link-Annotationen können verschiedene Aktionen ausführen, die über eine einfache Navigation hinausgehen:
|
1 2 3 |
13 0 obj < < Type Annot Subtype Link Rect [50 50 200 100] A << Type Action S URI URI (https: www.example.com)>> >> endobj |
Aktionstypen
- /S /GoTo – Navigiert zu einem Ziel innerhalb des Dokuments
- /S /GoToR – Navigiert zu einem Ziel in einem anderen Dokument
- /S /URI – Öffnet eine Web-URL
- /S /Launch – Starte eine externe Anwendung.
- /S /JavaScript – Führe JavaScript-Code aus.
Anmerkungsdarstellung
Benutzerdefinierte visuelle Formatierung für Anmerkungen wird durch Erscheinungs-Streams erreicht, wodurch eine präzise Kontrolle darüber ermöglicht wird, wie Anmerkungen für Benutzer angezeigt werden:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
14 0 obj < < Type Annot Subtype Square Rect [100 100 200 150] C [1.0 0.0 0.0] BS << W 2 S S>> /AP < < N 15 0 R>> >> endobj 15 0 obj < < Type XObject Subtype Form BBox [0 0 100 50] Length 85>> stream q 1.0 0.0 0.0 RG 2 w 10 10 80 30 re S Q endstream endobj |
Praktische Implementierungsrichtlinien
Integration der Dokumentstruktur.
Eine erfolgreiche Implementierung erfordert das Verständnis, wie diese Elemente innerhalb der umfassenderen PDF-Dokumentenstruktur zusammenwirken.
|
1 2 3 4 |
1 0 obj < < Type Catalog Pages 2 0 R Outlines 3 0 R Names << EmbeddedFiles 4 0 R>> /Metadata 5 0 R >> endobj |
✅ Implementierungs-Checkliste
- Einrichtung des Dokumentenverzeichnisses – Stellen Sie sicher, dass die Verweise auf Inhaltsverzeichnisse, Namen und Metadaten korrekt sind.
- Objektnummerierung – Achten Sie auf eine konsistente Objektnummerierung und Querverweise.
- Stream-Kodierung – Verwenden Sie geeignete Filter und Kodierungen für Streams.
- Validierung – Überprüfen Sie die PDF-Struktur mit Validierungstools.
- Kompatibilitätstests – Testen Sie die Kompatibilität mit verschiedenen PDF-Anzeigeprogrammen und Versionen.
Häufige Probleme und Lösungen.
❌ Lesezeichen werden nicht angezeigt.
Lösung: Stellen Sie sicher, dass der Dokumentkatalog einen Eintrag enthält. /Outlines und dass die Inhaltsstrukturordnung korrekt aufgebaut ist und die richtigen Eltern-Kind-Beziehungen aufweist.
❌ Metadaten werden nicht erkannt.
Lösung: Stellen Sie sicher, dass der XML-Metadatenstrom korrekt formatiert ist, die richtigen Namensräume verwendet und im Dokumentkatalog referenziert wird. /Type /Metadata Und /Subtype /XML.
❌ Anhänge nicht zugänglich.
Lösung: Überprüfen Sie, ob eingebettete Dateien entweder im Dokument-Level-Namensregister oder im Seiten-Level-Anmerkungsregister korrekt referenziert sind und ob die Dateispezifikationsregister korrekt strukturiert sind.
Abschluss
Die Beherrschung von PDF-Metadaten und der Implementierung von Lesezeichen ist entscheidend für die Entwicklung von Dokumenten in professioneller Qualität, die eine überlegene Benutzererfahrung und Funktionalität bieten. Diese leistungsstarken Funktionen bieten:
- Verbesserte Navigation. – Durch gut strukturierte Lesezeichen und Ziele.
- Umfangreiche Metadaten. – Ermöglichen eine bessere Dokumentenverwaltung und Suchfunktion.
- Dateiintegration – Bündelung verwandter Ressourcen innerhalb von Dokumenten
- Interaktive Elemente – Erstellung ansprechender Benutzererlebnisse durch Annotationen
Durch die korrekte Implementierung dieser Funktionen können Sie PDF-Dokumente erstellen, die über einfachen Text und Grafiken hinausgehen und zu umfassenden, interaktiven Ressourcen werden, die sowohl menschlichen Lesern als auch automatisierten Systemen effektiv dienen.
🚀 Nächste Schritte
- Üben Sie die Implementierung dieser Strukturen in Ihrem PDF-Erstellungsprozess.
- Experimentieren Sie mit verschiedenen Annotationstypen und Buchmarkhierarchien.
- Testen Sie Ihre Implementierungen in verschiedenen PDF-Anzeigeprogrammen.
- Erkunden Sie erweiterte PDF-Funktionen, die auf diesen Grundlagen aufbauen.