Das Verständnis der inneren Struktur von PDF.
Willkommen in der faszinierenden Welt der PDF-Interna! Haben Sie sich jemals gefragt, was eine PDF-Datei ausmacht? Hinter den vertrauten Dokumenten, die wir täglich betrachten, verbirgt sich eine ausgeklügelte Architektur, die den digitalen Dokumentenaustausch revolutioniert hat. In dieser umfassenden Untersuchung werden wir die Schichten der PDF-Struktur aufdecken und die komplexen Mechanismen enthüllen, die diese allgegenwärtigen Dateien funktionieren lassen.
🔍 Einführung: Mehr als nur die Oberfläche.
Das Portable Document Format (PDF) ist zum De-facto-Standard für den Dokumentenaustausch weltweit geworden. Von einfachen Textdokumenten bis hin zu komplexen interaktiven Formularen gewährleisten PDFs ein konsistentes Erscheinungsbild auf verschiedenen Plattformen und Geräten. Aber was steckt hinter dieser universellen Kompatibilität?
In dieser detaillierten Untersuchung werden wir die logische Struktur untersuchen, die PDF-Dateien wirklich portabel macht. Wir werden die grundlegenden Bausteine betrachten: Trailer-Dictionary., Dokumenten-Katalog.und Seitentree—das Dreigestirn, das jede PDF-Funktionalität steuert. Wir werden auch die Geheimnisse der speziellen Datenformate von PDF für Textstrings und Datumsangaben enthüllen.
🎯 Was Sie in diesem Leitfaden lernen werden:
- Die vier grundlegenden Komponenten der PDF-Struktur
- Wie PDF Inhalte effizient organisiert und referenziert
- Die Rolle von Dictionaries, Katalogen und Seitentrees
- Die einzigartigen Ansätze von PDF für Textkodierung und Datumsformatierung
- Beispiele aus der Praxis für PDF-Objektstrukturen.
- Best Practices zum Verständnis der internen Funktionsweise von PDF.
📋 Die Anatomie einer PDF-Datei: Überblick auf hoher Ebene.
Bevor wir uns mit den Details befassen, legen wir ein mentales Modell der PDF-Struktur fest. Stellen Sie sich eine PDF-Datei als ein ausgeklügeltes Dateisystem vor, in dem jedes Informationselement einen bestimmten Platz und Zweck hat.
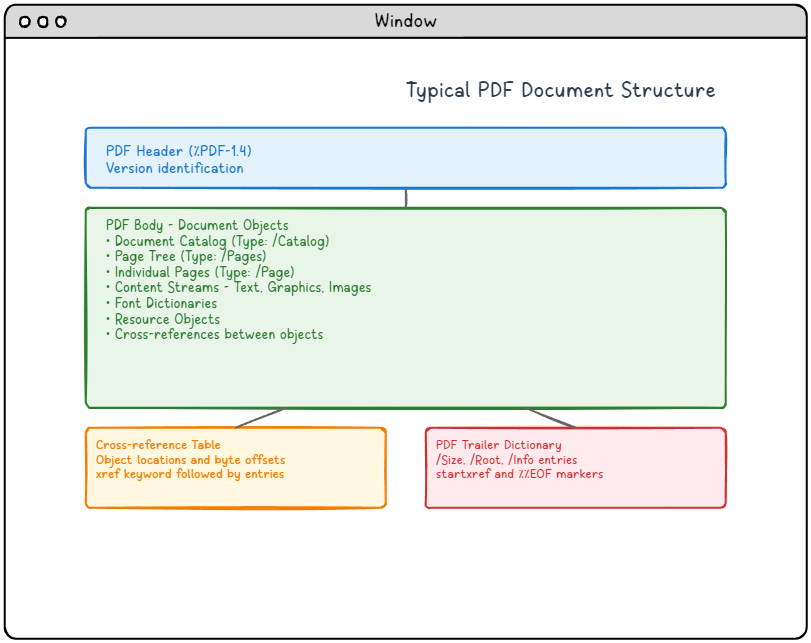
Abbildung 1: Typische PDF-Dokumentstruktur, die die vier Hauptkomponenten und ihre Beziehungen zeigt.
Lange Beschreibung für das Diagramm der PDF-Struktur:
Dieses Diagramm veranschaulicht die typische Struktur eines PDF-Dokuments mit vier Hauptkomponenten, die vertikal angeordnet sind:
-
- PDF-Header (Blauer Bereich oben): Enthält die Versionsinformation (%PDF-1.4), die die PDF-Formatversion angibt.
- PDF-Body (Grüner Bereich in der Mitte): Der größte Bereich, der alle Dokumentobjekte enthält, einschließlich Dokumentkatalog, Seitentree, einzelne Seiten, Inhaltsströme mit Text/Grafiken/Bildern, Schriftartdefinitionen, Ressourcenobjekte und Querverweise zwischen Objekten.
- Querverweistabelle (Oranger Bereich unten links): Enthält Objektpositionen und Byte-Offsets, gekennzeichnet mit dem Schlüsselwort "xref", gefolgt von Einträgen.
- PDF-Trailer-Dictionary (Roter Bereich unten rechts): Enthält wichtige Navigationsinformationen, einschließlich der Einträge "/Size", "/Root" und "/Info", und endet mit den Markern "startxref" und "%%EOF".
Pfeile zeigen den logischen Ablauf von der Kopfzeile zum Hauptteil, der sich dann in eine Querverweistabelle und ein Trailer-Dictionary verzweigt, und veranschaulichen, wie PDF-Reader die Dokumentstruktur durchsuchen.
Ein PDF-Dokument besteht aus vier Hauptelementen, die harmonisch zusammenarbeiten:
🏗️ Die vier Säulen der PDF-Struktur:
- Header – Identifiziert die PDF-Version und -Funktionen.
- Body – Enthält alle Dokumentobjekte (Text, Bilder, Schriftarten usw.).
- Querverweistabelle. – Ordnet Objekte für schnellen Zugriff.
- Anhänger – Bietet den Einstiegspunkt zur Navigation im Dokument.
Diese Struktur ermöglicht die bemerkenswerte Effizienz von PDF bei der Verarbeitung von Dokumenten jeder Größe, von einfachen einseitigen Briefen bis hin zu umfangreichen technischen Handbüchern mit Tausenden von Seiten.
🗂️ Das Trailer-Dictionary: Das GPS-System Ihrer PDF-Datei.
Stellen Sie sich vor, Sie versuchen, eine Bibliothek ohne Katalogsystem zu durchsuchen – es würde Chaos entstehen! Das Trailer-Dictionary dient als ausgeklügeltes Navigationssystem für PDF und bietet die wesentliche Roadmap, die PDF-Reader verwenden, um Ihr Dokument zu verstehen und anzuzeigen.
Das Trailer-Dictionary befindet sich am Ende der PDF-Datei und ist paradoxerweise eines der ersten Elemente, die beim Öffnen einer PDF-Datei verarbeitet werden. Es enthält die entscheidenden Informationen, die es Software ermöglichen, alle anderen Komponenten des Dokuments zu finden und zu interpretieren.
🔑 Wesentliche Einträge im Trailer-Dictionary.
| Key | Type | Purpose | Required? |
|---|---|---|---|
/Size |
Integer | Total entries in cross-reference table (usually objects + 1) | ✅ Yes |
/Root |
Indirect Reference | Points to the document catalog—the master control center | ✅ Yes |
/Info |
Indirect Reference | Links to document metadata (title, author, creation date) | ❌ Optional |
/ID |
Array of Strings | Unique document identifier for workflow management | ❌ Optional |
💡 Profi-Tipp: Das Verständnis von PDF-IDs.
Der /ID Das Array enthält zwei Zeichenketten: die erste wird beim Erstellen des Dokuments festgelegt und ändert sich nie, während die zweite sich jedes Mal aktualisiert, wenn das Dokument geändert wird. Dieses Dual-Identifikator-System ermöglicht ausgefeilte Dokumentenmanagement-Workflows.
📄 Beispiel für ein reales Trailer-Wörterbuch:
|
1 2 3 4 5 6 |
<< /Size 421 /Root 377 0 R /Info 375 0 R /ID [<5sazn0fs3tamppia2izf569h281104ae> <6cig0wa61ti593bzuwy41905tr6s5c5a>] >> |
Dieses Beispiel zeigt einen Trailer für ein Dokument mit 421 Objekten, wobei Objekt 377 als Dokumentenkatalog dient und Objekt 375 die Dokumentinformationen enthält.
📊 Dokumentinformationswörterbuch: Traditionelle PDF-Metadaten.
Das Dokumentinformationswörterbuch enthält die Erstellungs- und Änderungsdaten der Datei sowie einige einfache Metadaten. Dies ist das traditionelle Metadatensystem, das in älteren PDF-Versionen verwendet wird und nicht mit den umfassenderen XMP-Metadaten verwechselt werden sollte, die in zukünftigen Artikeln behandelt werden.
Betrachten Sie dieses Wörterbuch als einen grundlegenden Bibliothekskatalogeintrag. Obwohl es nicht unbedingt erforderlich ist, um das Dokument anzuzeigen, liefert es grundlegende Informationen über den Ursprung und die Historie des Dokuments mithilfe einfacher Textzeichenketten.
📋 Dokumentinformationsfelder.
| Key | Data Type | Description | Example |
|---|---|---|---|
/Title |
Text String | Document title (separate from any visible title) | “Annual Report 2024” |
/Subject |
Text String | Document subject or description | “Financial Performance Analysis” |
/Keywords |
Text String | Searchable keywords | “finance, quarterly, revenue” |
/Author |
Text String | Document creator | “Jane Smith” |
/Creator |
Text String | Original application that created the document | “Microsoft Word” |
/Producer |
Text String | Application that converted to PDF | “Adobe Acrobat” |
/CreationDate |
Date String | When the document was originally created | D:20240625132712+08’00’ |
/ModDate |
Date String | Last modification timestamp | D:20240626094530+08’00’ |
⚠️ Wichtige Unterscheidung
Der /Creator Und /Producer Die Felder dienen unterschiedlichen Zwecken: "Creator" identifiziert die ursprüngliche Anwendungssoftware (z. B. Microsoft Word), während "Producer" die Software angibt, die das endgültige PDF erstellt hat (z. B. Adobe Acrobat oder ein PDF-Druckertreiber).
📋 Vollständiges Dokumentinformationswörterbuch:
|
1 2 3 4 5 6 7 8 9 10 |
<< /ModDate (D:20060926213913+02'00') /CreationDate (D:20060926213913+02'00') /Title (Product Catalog - UK Edition) /Creator (QuarkXPress: pictwpstops filter 1.0) /Producer (Acrobat Distiller 6.0 for Macintosh) /Author (James Smith) /Subject (Quarterly Product Showcase) /Keywords (products, catalog, prices, specifications) >> |
🏛️ Dokumentenkatalog: Das zentrale Kontrollzentrum
Wenn das Trailer-Wörterbuch das GPS-System von PDF ist, dann ist der Dokumentenkatalog sein zentrales Kontrollzentrum. Als Wurzelobjekt des gesamten Dokumentengraphen orchestriert der Katalog, wie alle anderen Objekte miteinander in Beziehung stehen und wie sich das Dokument beim Anzeigen oder Drucken verhält.
Jedes Objekt in einem PDF-Dokument kann über direkte oder indirekte Referenzen ausgehend vom Dokumentenkatalog erreicht werden. Dieser zentralisierte Ansatz gewährleistet eine effiziente Navigation und erhält die Integrität des Dokuments.
🎛️ Wesentliche Katalogeinträge
| Key | Type | Purpose | Required? |
|---|---|---|---|
/Type |
Name | Must be /Catalog |
✅ Yes |
/Pages |
Indirect Reference | Root of the page tree structure | ✅ Yes |
/PageLabels |
Number Tree | Enables complex page numbering (i, ii, iii, 1, 2, 3) | ❌ Optional |
/Names |
Dictionary | Name trees for referencing objects by name | ❌ Optional |
/Dests |
Dictionary | Named destinations for hyperlinks | ❌ Optional |
/ViewerPreferences |
Dictionary | Controls PDF viewer behavior | ❌ Optional |
/PageMode |
Name | Default viewing mode (thumbnails, bookmarks, etc.) | ❌ Optional |
/PageLayout |
Name | Page display layout (single, facing pages, etc.) | ❌ Optional |
/Outlines |
Indirect Reference | Document bookmarks/outline structure | ❌ Optional |
/Metadata |
Indirect Reference | XMP metadata stream | ❌ Optional |
🎨 Betrachterpräferenzen: Steuerung der Benutzererfahrung
Der /ViewerPreferences Das Dictionary ermöglicht es Dokumenterstellern, die Darstellung ihrer Dokumente in PDF-Betrachtern zu beeinflussen. Dies kann das Ausblenden von Symbolleisten, das Anpassen von Seiten an Fenster oder sogar die Steuerung von Druckeinstellungen umfassen.
📚 Erläuterung der Optionen für die Seitenansicht
- /UseNone – Nur Dokument, ohne Navigationsleisten
- /UseOutlines – Zeigt das Lesezeichen-Panel an
- /UseThumbs – Zeigt Miniaturansichten der Seiten an
- /FullScreen – Präsentationsmodus starten
- /UseOC – Optionalinhalt (Ebenen) anzeigen
- /UseAttachments – Anhänge anzeigen
🌳 Seiten und Seitenzweige: Effiziente Inhaltsorganisation
Eine der cleversten Designentscheidungen von PDF ist die Art und Weise, wie Seiten organisiert sind. Anstatt einer einfachen linearen Liste verwendet PDF eine Baumstruktur, die die Leistung erheblich verbessert, insbesondere bei großen Dokumenten.
Stellen Sie sich vor, Sie müssten eine bestimmte Seite in einem 1000-seitigen Dokument finden, indem Sie jede Seite einzeln überprüfen – das könnte bis zu 1000 Operationen erfordern! Die Seitendatenstruktur reduziert dies auf nur wenige Operationen, wodurch PDF-Viewer auch bei sehr großen Dokumenten bemerkenswert schnell sind.
🏗️ Verständnis der Struktur des Seitendictionaries.
Jede Seite in einer PDF-Datei wird durch ein Seitendictionary dargestellt, das alle Elemente zusammenführt, die benötigt werden, um diese bestimmte Seite darzustellen: Inhalt, Ressourcen (Schriftarten, Bilder) und Layoutspezifikationen.
| Key | Type | Purpose | Inheritance |
|---|---|---|---|
/Type |
Name | Must be /Page |
❌ |
/Parent |
Indirect Reference | Parent node in page tree | ❌ |
/Resources |
Dictionary | Fonts, images, other resources | ✅ From parent if missing |
/Contents |
Stream/Array | Page content instructions | ❌ |
/MediaBox |
Rectangle | Physical page size | ✅ From parent if missing |
/CropBox |
Rectangle | Visible page area | ✅ Defaults to MediaBox |
/Rotate |
Integer | Page rotation (0, 90, 180, 270) | ✅ From parent if missing |
📐 Verständnis der PDF-Koordinatensysteme.
PDF verwendet ein ausgeklügeltes Koordinatensystem, das auf Rechtecken basiert, die durch vier Zahlen definiert sind, die die diagonalen Eckpunkte darstellen. Das Verständnis dieses Systems ist entscheidend für die Arbeit mit Seitenlayouts.
📏 Beispiele für die Definition von Rechtecken:
|
1 2 |
/MediaBox [0 0 595 842] # A4 size in points (8.27" × 11.69") /CropBox [50 50 545 792] # A4 with 50-point margins on all sides |
💡 PDF-Maßeinheiten.
PDF verwendet Punkte als Basiseinheit, wobei 1 Punkt = 1/72 Zoll entspricht. Dies macht Berechnungen einfach: 72 Punkte = 1 Zoll, 144 Punkte = 2 Zoll usw.
🌲 Die Page Tree Architektur.
Die Stärke der Page Tree Architektur liegt in ihrer ausgewogenen Struktur. Gute PDF-Anwendungen erstellen Bäume, in denen jede Seite in nur wenigen Schritten gefunden werden kann, unabhängig von der Dokumentgröße.
🌳 Beispiel für die Page Tree Architektur.
/Type /Pages
/Count 7.
/Count 3
/Count 2
/Type /Page
/Type /Page
Abbildung 2: Seitenstruktur für ein 7-seitiges Dokument, die eine ausgewogene Hierarchie für einen effizienten Zugriff zeigt.
🎯 Vorteile der Seitenstruktur:
- Logarithmische Zugriffszeit – Finden Sie jede Seite in O(log n) Operationen.
- Effiziente Speicherverwaltung. – Nur die benötigten Teile großer Dokumente laden.
- Skalierbare Architektur. – Die Leistung bleibt konsistent, wenn Dokumente größer werden.
- Optimierung der Vererbung. – Gemeinsame Eigenschaften werden über Seitengruppen hinweg geteilt.
📝 Struktur eines Page Tree-Knotens.
| Key | Type | Purpose |
|---|---|---|
/Type |
Name | Must be /Pages |
/Kids |
Array | References to child nodes (pages or page trees) |
/Count |
Integer | Total number of leaf pages under this node |
/Parent |
Reference | Parent node (required unless root) |
🏗️ Beispiel für die Implementierung eines Page Tree:
|
1 2 3 4 5 6 7 8 |
1 0 obj % Root node << /Type /Pages /Kids [2 0 R 3 0 R 4 0 R] /Count 7 >> endobj 2 0 obj % Intermediate node << /Type /Pages /Kids [5 0 R 6 0 R 7 0 R] /Parent 1 0 R /Count 3 >> endobj 5 0 obj % Actual page << /Type /Page /Parent 2 0 R /MediaBox [0 0 612 792] /Resources << >> >> endobj |
🔤 Text Strings: Umgang mit mehreren Kodierungen.
Die globale Reichweite von PDF erfordert robuste Textverarbeitungsfunktionen. Das Format unterstützt mehrere Kodierungsschemata, um verschiedene Sprachen und Zeichensätze zu unterstützen, und stellt sicher, dass Dokumente unabhängig vom Standort des Betrachters korrekt angezeigt werden.
Das Verständnis der Textkodierung in PDF ist entscheidend für alle, die mit internationalen Dokumenten arbeiten oder PDF-Verarbeitungsanwendungen entwickeln.
📝 Zwei primäre Kodierungsmethoden.
1. PDFDocEncoding
PDFDocEncoding basiert auf ISO Latin-1 und verarbeitet die meisten westeuropäischen Sprachen effizient. Es ist die Standardkodierung für PDF-Textstrings und bietet eine hervorragende Kompatibilität mit älteren Systemen.
2. Unicode (UTF-16BE)
Für internationale Zeichen und komplexe Schriften verwendet PDF Unicode mit UTF-16BE-Kodierung. Unicode-Strings werden durch ein spezielles Byte-Order-Mark (BOM) am Anfang identifiziert.
🔍 Erkennung von Unicode-Strings.
PDF-Viewer bestimmen die Kodierung, indem sie die ersten beiden Bytes einer Textzeichenkette untersuchen:
|
1 2 3 4 |
If bytes[0] == 254 AND bytes[1] == 255: encoding = "UTF-16BE" # Unicode byte-order marker U+FEFF else: encoding = "PDFDocEncoding" # Default PDF encoding |
⚠️ Kodierungsbeschränkung.
Aufgrund des Unicode-Erkennungsmechanismus dürfen PDFDocEncoding-Strings nicht mit der Byte-Sequenz [254, 255] (þÿ) beginnen. Diese Einschränkung hat jedoch selten Auswirkungen auf reale Dokumente.
📅 Datumsformate: Präzise Zeitinformationen.
PDF verwendet ein ausgeklügeltes Datumsformat, das nicht nur festhält, wann etwas passiert ist, sondern auch Zeitzonen berücksichtigt – was für globale Dokumentenworkflows und rechtliche Anforderungen entscheidend ist.
📋 Struktur des PDF-Datumsformats.
|
1 |
(D:YYYYMMDDHHmmSSOHH'mm') |
| Component | Meaning | Format | Example |
|---|---|---|---|
| YYYY | Year | Four digits | 2025 |
| MM | Month | 01-12 | 06 (June) |
| DD | Day | 01-31 | 25 |
| HH | Hour | 00-23 | 13 (1 PM) |
| mm | Minute | 00-59 | 27 |
| SS | Second | 00-59 | 12 |
| O | UTC Offset | +, -, or Z | + (later than UTC) |
| HH’ | Offset Hours | 00-23 | 08 (8 hours) |
| mm’ | Offset Minutes | 00-59 | 00 (no minutes) |
🌍 Beispiele für Zeitzonen.
|
1 2 3 |
(D:20250625132712+08'00') # June 25, 2024, 1:27:12 PM, UTC+8 (Beijing) (D:20250625132712-05'00') # Same moment in Eastern Standard Time (D:20250625132712Z) # Same moment in UTC (Zulu time) |
🕐 Flexible Datumsgenauigkeit.
Die Datumsangaben in PDFs unterstützen eine variable Genauigkeit. Sie können nur ein Jahr angeben. (D:2025), oder geben Sie die vollständige Genauigkeit bis auf Sekunden und Zeitzonen an. Fehlende Komponenten werden standardmäßig mit sinnvollen Werten belegt (01 für Monat/Tag, 00 für Zeitkomponenten).
🧩 Alles zusammenführen: Ein vollständiges Beispiel.
Lassen Sie uns ein vollständiges, manuell erstelltes PDF-Beispiel betrachten, das alle besprochenen Konzepte veranschaulicht. Dieses dreiseitige Dokument zeigt die Interaktion zwischen allen PDF-Strukturelementen.
📄 Vollständiges Beispiel für die PDF-Struktur:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
%PDF-1.0 % Header 1 0 obj % Document catalog << /PageLayout /TwoColumnLeft /Pages 2 0 R /Type /Catalog >> endobj 2 0 obj % Root of page tree << /Kids [3 0 R 4 0 R] /Type /Pages /Count 3 >> endobj 3 0 obj % Page one << /Type /Page /Parent 2 0 R /MediaBox [0 0 612 792] % US Letter size /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [5 0 R] >> endobj 4 0 obj % Intermediate page tree node << /Parent 2 0 R /Kids [6 0 R 7 0 R] /Count 2 /Type /Pages >> endobj 5 0 obj % Content stream for page one << /Length 58 >> stream BT /F0 24 Tf 50 750 Td (Hello, PDF World!) Tj ET endstream endobj 6 0 obj % Page two << /Type /Page /Parent 4 0 R /MediaBox [0 0 612 792] /Rotate 90 % Landscape orientation /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [8 0 R] >> endobj 7 0 obj % Page three << /Type /Page /Parent 4 0 R /MediaBox [0 0 612 792] /Resources << /Font << /F0 << /BaseFont /Times-Roman /Subtype /Type1 /Type /Font >> >> >> /Contents [9 0 R] >> endobj 8 0 obj % Content stream for page two << /Length 72 >> stream BT /F0 18 Tf 50 700 Td (This page is rotated 90 degrees) Tj ET endstream endobj 9 0 obj % Content stream for page three << /Length 45 >> stream BT /F0 24 Tf 50 750 Td (Final page) Tj ET endstream endobj 10 0 obj % Document information dictionary << /Title (PDF Structure Example) /Author (PDF Guide Author) /Producer (Manual Creation) /CreationDate (D:20240625132712+08'00') /ModDate (D:20240625133045+08'00') /Subject (Demonstrating PDF internal structure) /Keywords (PDF, structure, example, tutorial) >> endobj xref % Cross-reference table 0 11 0000000000 65535 f 0000000015 00000 n 0000000074 00000 n 0000000120 00000 n 0000000355 00000 n 0000000415 00000 n 0000000522 00000 n 0000000747 00000 n 0000000958 00000 n 0000001079 00000 n 0000001173 00000 n trailer % Trailer dictionary << /Size 11 /Root 1 0 R /Info 10 0 R /ID [<A1B2C3D4E5F6789012345678901234AB> <A1B2C3D4E5F6789012345678901234AB>] >> startxref 1456 %%EOF |
🗺️ Objektreferenzgraph
/Size 11
/Root 1 0 R → Document Catalog
/Info 10 0 R → Document Info
/Type /Catalog
/Pages 2 0 R
/Title /Author
/CreationDate /ModDate
/Type /Pages
/Kids [3 0 R 4 0 R]
/Count 3
/Type /Page
/Contents [5 0 R]
/Kids [6 0 R 7 0 R]
/Count 2
/Contents [8 0 R]
/Rotate 90
/Contents [9 0 R]
Abbildung 3: Objektreferenzdiagramm, das zeigt, wie das Trailer-Dictionary mit allen Dokumentkomponenten verbunden ist.
🔍 Analyse der Beispielstruktur.
🎯 Wichtige Beobachtungen:
- Effiziente Navigation. – Jede Seite ist in maximal 2 Schritten von der Root-Seite aus erreichbar.
- Ressourcenvererbung. – Schriftressourcen können von übergeordneten Knoten geerbt werden.
- Flexible Layout – Seite 2 demonstriert die Rotationsfunktionen.
- Umfangreiche Metadaten. – Vollständige Dokumentinformationen für das Workflow-Management.
- Eindeutige Kennzeichnung. – Das ID-Array ermöglicht die Dokumentverfolgung.
🚀 Erweiterte Themen und Best Practices.
🔧 Optimierungsstrategien.
📈 Tipps zur Leistungsoptimierung:
- Balanced Trees – Ermöglicht logarithmische Zugriffszeiten für große Dokumente.
- Resource Sharing – Platzieren Sie gemeinsame Ressourcen in den übergeordneten Seitennode-Strukturen.
- Efficient Encoding – Verwenden Sie PDFDocEncoding für westliche Texte, Unicode nur wenn nötig.
- Proper Inheritance – Nutzen Sie die Seitennode-Struktur-Vererbung für gemeinsame Eigenschaften.
- Minimale Metadaten – Nur notwendige Informationen in den Dictionary-Einträgen enthalten.
🛡️ Fehlervermeidung und Validierung
⚠️ Häufige Fehler, die vermieden werden sollten:
- Unterbrochene Verweise – Stellen Sie sicher, dass alle indirekten Verweise auf gültige Objekte verweisen.
- Inkonsistente Zählungen – Die Zählungen der Seitentypen müssen die tatsächliche Anzahl der Blattseiten genau widerspiegeln.
- Fehlende Pflichtfelder – Immer die obligatorischen Dictionary-Einträge einfügen
- Ungültige Datumsformate – Halten Sie sich genau an die Datumsformat-Spezifikationen
- Encoding-Unterschiede – Unicode- und PDFDocEncoding-Strings korrekt identifizieren
🔮 Zukünftige Überlegungen
Da PDF sich ständig weiterentwickelt, wird das Verständnis dieser grundlegenden Strukturen immer wertvoller. Moderne PDF-Funktionen wie digitale Signaturen, Accessibility-Tags und interaktive Formulare basieren alle auf dem soliden Fundament, das wir untersucht haben.
🌟 Neue PDF-Technologien:
- PDF/A-Standards – Formate für die Langzeitarchivierung
- PDF/UA-Barrierefreiheit – Einhaltung universeller Barrierefreiheitsstandards
- Interaktive Formulare – Dynamische Inhalte und Benutzerinteraktion
- Digitale Signaturen – Kryptografische Dokumentintegrität
- 3D-Inhalte – Drei-dimensionale Modell-Einbettung
🎯 Fazit: Beherrschung der PDF-Struktur
Das Verständnis der internen Struktur von PDF eröffnet Möglichkeiten für erweiterte Dokumentverarbeitung, Fehlerbehebung und Optimierung. Von den Navigationsfunktionen des Trailer-Dictionaries bis zur effizienten Organisation von Seitentrees dient jedes Element einem bestimmten Zweck bei der Erstellung der robusten, portablen Dokumente, auf die wir täglich angewiesen sind.
🏆 Wichtige Erkenntnisse:
- Hierarchisches Design – Die baumartige Struktur von PDF ermöglicht eine effiziente Skalierung.
- Intelligente Navigation – Querverweistabellen und -wörterbücher ermöglichen schnellen Zugriff.
- Flexible Kodierung – Unterstützung mehrerer Textkodierungen für den globalen Dokumentenaustausch.
- Umfangreiche Metadaten. – Umfassende Informationsverfolgung unterstützt komplexe Arbeitsabläufe.
- Vererbungsmodell – Ressourcenfreigabe reduziert Redundanz und Dateigröße.
„Die Schönheit von PDF liegt nicht in seiner Komplexität, sondern darin, wie diese Komplexität elegant organisiert ist, um das einfache Ziel der universellen Dokumentportabilität zu erreichen.“
Diese umfassende Untersuchung der PDF-Struktur zielt darauf ab, die technischen Aspekte eines der wichtigsten Dokumentformate der Welt zu erklären. Das Verständnis dieser internen Abläufe ermöglicht es Entwicklern, Dokumentmanagern und interessierten Personen, effektiver mit der PDF-Technologie zu arbeiten. Es wird empfohlen, ausgereifte PDF-Entwicklungsbibliotheken zu verwenden, um Ihre PDF-Verarbeitungsaufgaben erheblich zu vereinfachen.